前端工程化-babel解析
Posted natsu-cc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端工程化-babel解析相关的知识,希望对你有一定的参考价值。
前言:
Babel 是一个通用的多功能 javascript 编译器,但与一般编译器不同的是它只是把同种语言的高版本规则转换为低版本规则(例如将ES6都给转换成目前支持比较广泛的ES5语法),而不是输出另一种低级机器可识别的代码,并且在依赖不同的拓展插件下可用于不同形式的静态分析。
Babel工作的三个阶段:
Babel的功能非常纯粹,以字符串的形式将源代码传给它,它就会返回一段新的代码字符串(以及sourcemap)。它既不会运行你的代码,也不会将多个代码打包到一起,它就是个编译器,例如输入语言是ES6+,编译目标语言是ES5。
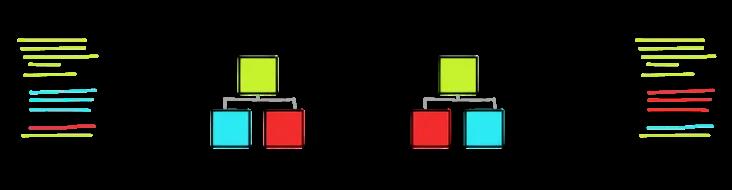
- 解析(Parse)
将代码解析生成抽象语法树( 即AST ),也就是计算机理解我们代码的方式(扩展:一般来说每个 js 引擎都有自己的 AST,比如熟知的 v8,chrome 浏览器会把 js 源码转换为抽象语法树,再进一步转换为字节码或机器代码),而 babel 则是通过 babylon 实现的 。简单来说就是一个对于 JS 代码的一个编译过程,进行了词法分析与语法分析的过程。 - 转换 (Transform)
对于抽象语法树(AST) 进行变换一系列的操作,babel 接受得到 AST 并通过 babel-traverse 对其进行遍历,在此过程中进行添加、更新及移除等操作。 - 生成( Generate)
根据变换后的抽象语法树(AST)再生成代码字符串, 使用到的模块是 babel-generator。
举例:
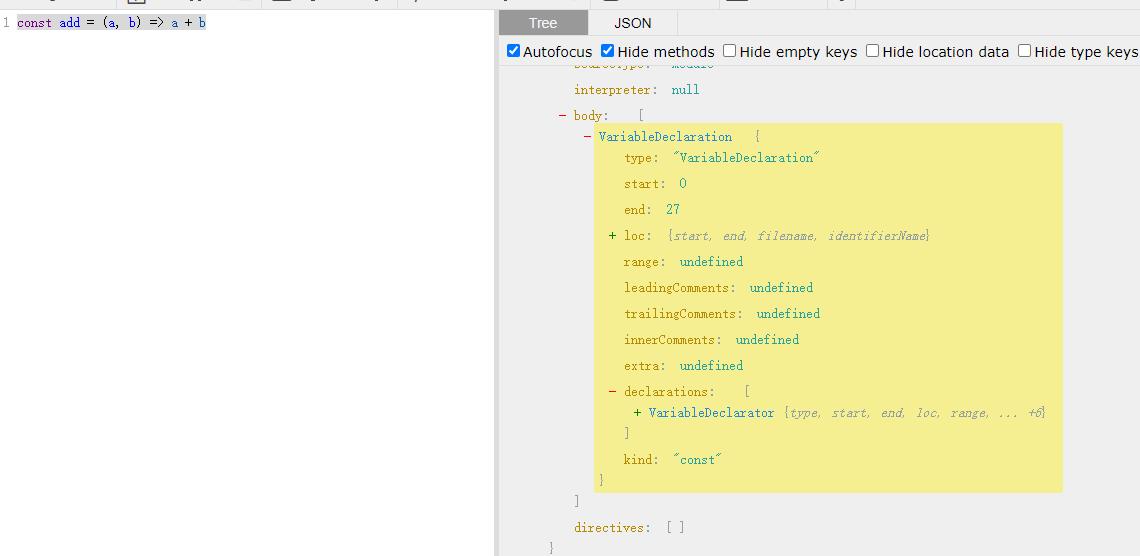
// ES6代码:
const add = (a, b) => a + b
经过 Babel 变成:
// ES5代码:
var add = function add(a, b)
return a + b;
;
Parse(解析):
Parse 阶段可以细分为两个阶段:词法分析(Lexical Analysis, LA)和语法分析(Syntactic Analysis, SA)。
- 词法分析(将整个代码字符串分割成语法单元数组)
词法分析阶段可以看成是对代码进行“分词”,它接收一段源代码,然后执行一段 tokenize 函数,把代码分割成被称为Tokens 的东西。Tokens 是一个数组,由一些代码的碎片组成,比如数字、标点符号、运算符号等。
语法单元:
- 空白:JS中连续的空格、换行、缩进等这些如果不在字符串里,就没有任何实际逻辑意义,所以把连续的空白符直接组合在一起作为一个语法单元。
- 注释:行注释或块注释,虽然对于人类来说有意义,但是对于计算机来说知道这是个“注释”就行了,并不关心内容,所以直接作为一个不可再拆的语法单元。
- 字符串:对于机器而言,字符串的内容只是会参与计算或展示,里面再细分的内容也是没必要分析的。
- 数字:JS语言里就有16、10、8进制以及科学表达法等数字表达语法,数字也是个具备含义的最小单元。
- 标识符:没有被引号扩起来的连续字符,可包含字母、_、$、及数字(数字不能作为开头)。标识符可能代表一个变量,或者true、false这种内置常量、也可能是if、return、function这种关键字,是哪种语义,分词阶段并不在乎,只要正确切分就好了。
- 运算符:+、-、*、/、>、<等等。
- 括号:(…)可能表示运算优先级、也可能表示函数调用,分词阶段并不关注是哪种语义,只把“(”或“)”当做一种基本语法单元。
- 其他:如中括号、大括号、分号、冒号、点等等。
// 代码分词后
[
"type": "Keyword", "value": "const" ,
"type": "Identifier", "value": "add" ,
"type": "Punctuator", "value": "=" ,
"type": "Punctuator", "value": "(" ,
"type": "Identifier", "value": "a" ,
"type": "Punctuator", "value": "," ,
"type": "Identifier", "value": "b" ,
"type": "Punctuator", "value": ")" ,
"type": "Punctuator", "value": "=>" ,
"type": "Identifier", "value": "a" ,
"type": "Punctuator", "value": "+" ,
"type": "Identifier", "value": "b"
]
- 语法分析(在分词结果的基础之上分析语法单元之间的关系)
语法分析就是把词汇进行立体的组合,确定有多重意义的词语最终是什么意思、多个词语之间有什么关系以及又应该再哪里断句等,通过语法分析把 Tokens 转化为上面提到过的 AST。
语法分析的过程又是个遍历语法单元的过程,语句和表达式会以树状的结构互相包含。
编程语言的解析中两个重要重要概念:
- 语句:语句是一个具备边界的代码区域,相邻的两个语句之间从语法上来讲互不干扰,调换顺序虽然可能会影响执行结果,但不会产生语法错误。例如return true、var a = 10、if (…) …
- 表达式:最终有个结果的一小段代码,它的特点是可以原样嵌入到另一个表达式。
例如1+1、str.replace(‘a’, ‘b’)、i < 10 && i > 0等。
Transform(转换):
AST 中有很多相似的元素,它们都有一个 type 属性,这样的元素被称作节点。一个节点通常含有若干属性,可以用于描述 AST 的部分信息。操作 AST 也就是操作其中的节点,可以增删改这些节点,从而转换成实际需要的 AST。
Babel 对于 AST 的遍历是深度优先遍历,对于 AST 上的每一个分支 Babel 都会先向下遍历走到尽头,然后再向上遍历退出刚遍历过的节点,然后寻找下一个分支。
"type": "Program",
"body": [
"type": "VariableDeclaration", // 变量声明
"declarations": [ // 具体声明
"type": "VariableDeclarator", // 变量声明
"id":
"type": "Identifier", // 标识符(最基础的)
"name": "add" // 函数名
,
"init":
"type": "ArrowFunctionExpression", // 箭头函数
"id": null,
"expression": true,
"generator": false,
"params": [ // 参数
"type": "Identifier",
"name": "a"
,
"type": "Identifier",
"name": "b"
],
"body": // 函数体
"type": "BinaryExpression", // 二项式
"left": // 二项式左边
"type": "Identifier",
"name": "a"
,
"operator": "+", // 二项式运算符
"right": // 二项式右边
"type": "Identifier",
"name": "b"
],
"kind": "const"
],
"sourceType": "module"
遍历过程,babel 通过实例化 visitor 对象完成,既其实我们生成出来的 AST 结构都拥有一个 accept 方法用来接收 visitor 访问者对象的访问,而访问者其中也定义了 visit 方法(即开发者定义的函数方法)使其能够对树状结构不同节点做出不同的处理,借此做到在对象结构的一次访问过程中,我们能够遍历整个对象结构。(访问者设计模式:提供一个作用于某对象结构中的各元素的操作表示,它使得可以在不改变各元素的类的前提下定义作用于这些元素的新操作)。而这个过程中可以将一些es5不支持的节点转换成低级兼容的语法,构建一个新的AST。
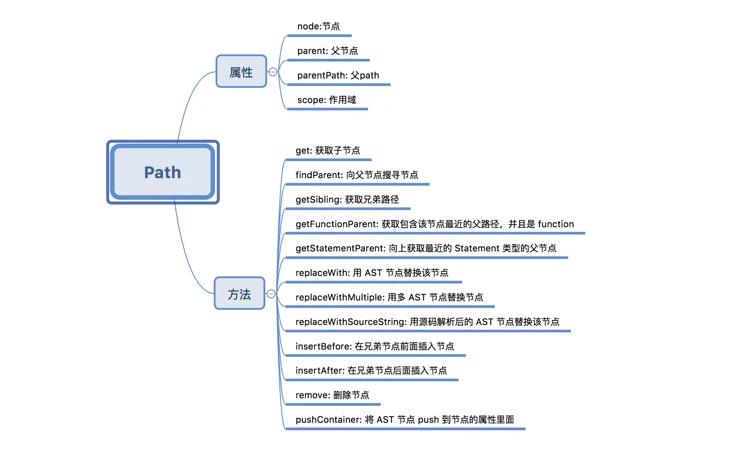
Visitors 在遍历到每个节点的时候,都会给我们传入 path 参数,包含了节点的信息以及节点和所在的位置,供我们对特定节点进行修改。
Generate(代码生成):
经过上面两个阶段,需要转译的代码已经转换,生成新的 AST 了,最后的阶段理所应当就是根据这个 AST 来生成代码了。
以上是关于前端工程化-babel解析的主要内容,如果未能解决你的问题,请参考以下文章