Tachyon:Spark生态系统中的分布式内存文件系统
Posted Frank201608
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tachyon:Spark生态系统中的分布式内存文件系统相关的知识,希望对你有一定的参考价值。
本文只是本人的阅读笔记,更完整的内容,请查阅原文:http://www.csdn.net/article/2015-06-25/2825056
摘要:Tachyon是个分布式的内存文件系统, 它在减轻Spark内存压力的同时,也赋予了Spark内存快速大量数据读写的能力。Tachyon把内存存储的功能从Spark中分离出来, 使Spark可以更专注计算的本身, 通过更细的分工达到更高的执行效率。
Tachyon简介
分布式内存计算的模式也是一柄双刃剑,在提高性能的同时不得不面对分布式数据存储所产生的问题,具体问题主要有以下几个:
1、当两个Spark作业需要共享数据时,必须通过写磁盘操作。
比如:作业1要先把生成的数据写入HDFS,然后作业2再从HDFS把数据读出来。在此,磁盘的读写可能造成性能瓶颈。
2、由于Spark会利用自身的JVM对数据进行缓存,当Spark程序崩溃时JVM进程退出,所缓存数据也随之丢失,因此在工作重启时又需要从HDFS把数据再次读出。
3、当两个Spark作业需操作相同的数据时,每个作业的JVM都需要缓存一份数据,不但造成资源浪费,也极易引发频繁的垃圾收集,造成性能的降低。
以上问题的根源来自于数据存储,由于计算平台尝试自行进行存储管理,以至于Spark不能专注于计算本身,造成整体执行效率的降低。Tachyon的提出就是为了解决这些问题,把存储与数据读写的功能从Spark中分离,使得Spark更专注在计算的本身。
Tachyon的部署
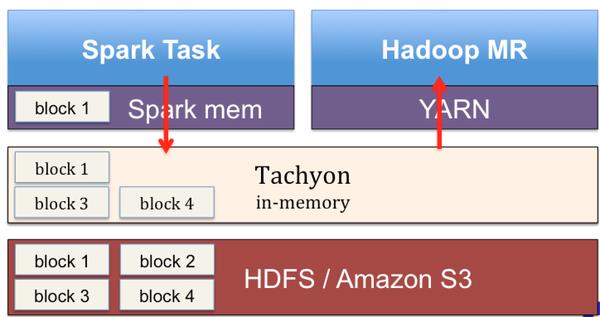
Tachyon被部署在计算平台(Spark,MR)之下以及存储平台(HDFS, S3)之上,通过全局地隔离计算平台与存储平台, Tachyon可以有效地解决上文列举的几个问题:
1、当两个Spark作业需要共享数据时,无需再通过写磁盘,而是借助Tachyon进行内存读写,从而提高计算效率。
2、在使用Tachyon对数据进行缓存后,即便在Spark程序崩溃JVM进程退出后,所缓存数据也不会丢失。这样,Spark工作重启时可以直接从Tachyon内存读取数据了。
3、当两个Spark作业需要操作相同的数据时,它们可以直接从Tachyon获取,并不需要各自缓存一份数据,从而降低JVM内存压力,减少垃圾收集发生的频率。
Tachyon系统架构
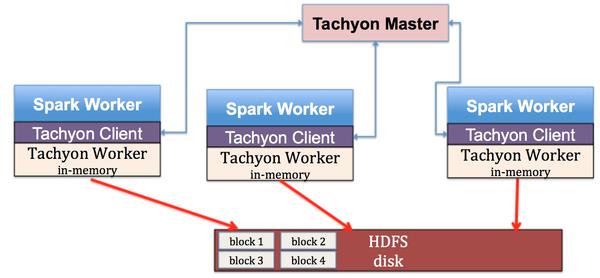
Tachyon有三个主要的部件:
- Tachyon Master;
- Tachyon Client;
- Tachyon Worker。
在每个Spark Worker节点上,都部署了一个Tachyon Worker,Spark Worker通过Tachyon Client访问Tachyon进行数据读写。所有的Tachyon Worker都被Tachyon Master所管理,Tachyon Master通过Tachyon Worker定时发出的心跳来判断Worker是否已经崩溃以及每个Worker剩余的内存空间量。
以上是关于Tachyon:Spark生态系统中的分布式内存文件系统的主要内容,如果未能解决你的问题,请参考以下文章
Tachyon 默认情况下是不是由 Apache Spark 中的 RDD 实现?
Tachyon on Mesos:分布式内存文件系统在Mesos应用中的实践