拐点检测常用算法介绍
Posted Wallace JW
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拐点检测常用算法介绍相关的知识,希望对你有一定的参考价值。
前言
最近在学习拐点检测的相关问题, 发现 C.Truong 的论文 对拐点检测的整个流程和目前主流的一些算法介绍的比较清楚,所以在这里进行了一些记录以及总结,并且对 Truong 发布的 ruptures 库做了一些简单的介绍。如果想要进行更深入的研究,请参考原论文和 ruptures。
文章目录
概览
问题定义
拐点检测名为 change point detection,对于一条不平缓的时间序列曲线,认为存在一些时间点 ( t 1 , t 2 , . . . , t k ) (t_1,t_2,...,t_k) (t1,t2,...,tk),使得曲线在这些点对应的位置发生突变,这些时间点对应的曲线点称为拐点,在连续的两个拐点之间,曲线是平稳的。
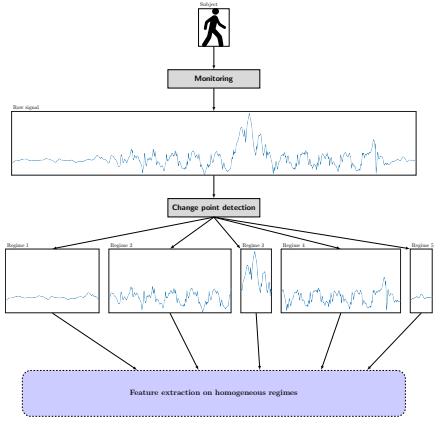
拐点检测算法的质量通过算法输出拐点与实际观测到的拐点的差值绝对值除以样本数来评估。
∀
k
,
∣
t
^
k
−
t
k
⋆
∣
/
T
,
\\forall k, \\quad\\left|\\hatt_k-t_k^\\star\\right| / T,
∀k,∣∣t^k−tk⋆∣∣/T,
理想情况下,当样本数T无穷大时,误差应该减少到0,这种性质称为满足渐近一致性 (asymptotic consistency.)
max
k
=
1
,
…
,
K
∗
∣
t
^
k
−
t
k
⋆
∣
/
T
⟶
p
0
\\max _k=1, \\ldots, K^*\\left|\\hatt_k-t_k^\\star\\right| / T \\stackrelp\\longrightarrow 0
k=1,…,K∗max∣∣t^k−tk⋆∣∣/T⟶p0
符号定义
y a . . b y_a..b ya..b 表示时间点 a 和 b 之间的时间序列,因此完整信号为 y 0.. T y_0..T y0..T。
对于给定的拐点索引
t
t
t,它的关联分数 associate fraction 称为拐点分数 change point fractions ,公式为 :
τ
:
=
t
/
T
∈
(
0
,
1
]
.
\\tau :=t / T \\in(0,1].
τ:=t/T∈(0,1].
拐点分数的集合 τ = τ 1 , τ 2 , … \\boldsymbol\\tau=\\left\\\\tau_1, \\tau_2, \\ldots\\right\\ τ=τ1,τ2,… 写作 ∣ τ |\\boldsymbol\\tau ∣τ|
研究方法
一般思路是构造一个对照函数 contrast function,目标是将对照函数的值最小化。
V
(
t
,
y
)
:
=
∑
k
=
0
K
c
(
y
t
k
…
t
k
+
1
)
,
V(\\mathbft, y) :=\\sum_k=0^K c\\left(y_t_k \\ldots t_k+1\\right),
V(t,y):=k=0∑Kc(ytk…tk+1),
其中
c
(
⋅
)
c(\\cdot)
c(⋅) 表示用来测量拟合度 goodness-of-fit 的损失函数 cost function, 损失函数的值在均匀的子序列上较低,在不均匀的子序列上较高。
基于离散优化问题 discrete optimization problem,拐点的总数量记为 K K K :
如果
K
K
K 是固定值,估算的拐点值为:
min
∣
t
∣
=
K
V
(
t
)
,
\\operatornamemin_|\\mathbft|=K V(\\mathbft),
min∣t∣=KV(t),
如果
K
K
K 不是固定值,估算的拐点值为:
min
t
V
(
t
)
+
pen
(
t
)
.
\\min _t V(\\mathbft)+\\operatornamepen(\\mathbft).
tminV(t)+pen(t).
其中
p
e
n
(
t
)
pen(t)
pen(t)为对
t
t
t 的惩罚项项
在这种方法论下,拐点检测的算法包含以下三个元素:
- 选择合适的损失函数来测算子序列的均匀程度 homogeneity,这与要检测的变化类型有关
- 解决离散优化问题
- 合理约束拐点的数量,确定使用固定的 K K K 还是用 p e n ( ) pen() pen() 来惩罚 penalizing 不固定的数量
损失函数
损失函数与被检测拐点的变化类型有关,下文介绍的损失函数使用在子序列 y a . . b y_a..b ya..b 上,其中 1 < = a < b < = T 1 <= a < b <= T 1<=a<b<=T
Piecewise i.i.d. signals
首先介绍一种使用 i . i . d . i.i.d. i.i.d. 变量对信号 y y y 进行建模的一般参数模型。
i . i . d . i.i.d. i.i.d. Independent and identically distributed,独立同分布,指一组随机变量中每个变量的概率分布都相同,且这些随机变量互相独立。
假设
y
1
,
.
.
.
,
y
T
y_1,...,y_T
y1,...,yT 是独立随机变量,概率分布 probability distribution
f
(
y
t
∣
θ
)
f\\left(y_t | \\theta\\right)
f(yt∣θ) 依赖于向量值参数
θ
\\theta
θ vector-value parameter,
θ
\\theta
θ 表示预测到发生突然变化的兴趣点。假设存在一系列真实的拐点
t
⋆
=
t
1
⋆
,
…
\\mathrmt^\\star=\\left\\t_1^\\star, \\ldots\\right\\
t⋆=t1⋆,…,并且满足:
y
t
∼
∑
i
=
0
K
f
(
⋅
∣
θ
k
)
,
(
t
k
⋆
<
t
≤
t
k
+
1
⋆
)
.
y_t \\sim \\sum_i=0^K f\\left(\\cdot | \\theta_k\\right) , \\left(t_k^\\star<t \\leq t_k+1^\\star\\right).
yt∼i=0∑Kf(⋅∣θk),(tk⋆以上是关于拐点检测常用算法介绍的主要内容,如果未能解决你的问题,请参考以下文章