构造业务需要的docker()
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了构造业务需要的docker()相关的知识,希望对你有一定的参考价值。
构造业务需要的docker
需求
毕设中想要引入docker来运行大数据插件
构造互相免密的Docker
使用centos作为基础docker
Dockerfile
FROM centos
RUN yum install -y net-tools openssh-clients openssh-server passwd && \\
ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key -P '' && \\
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key -P '' && \\
sed -i 's/#Port 22/Port 22 /' /etc/ssh/sshd_config && \\
sed -i 's/#ListenAddress 0.0.0.0/ListenAddress 0.0.0.0/' /etc/ssh/sshd_config && \\
sed -i 's/#ListenAddress ::/ListenAddress ::/' /etc/ssh/sshd_config && \\
ssh-keygen -t rsa -f /root/.ssh/id_rsa -P '' && \\
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys && \\
chmod 700 ~/.ssh/authorized_keys && \\
sed -i 's/root@.*/root@\\*/' /root/.ssh/id_rsa.pub && \\
rm -f /run/nologin
LABEL maintainer="ShiZi"
CMD /usr/sbin/sshd -D
docker build -t nopasswd:1.0 .

使用该镜像启动的容器之间是相互免密的。
构造JDK
命令行构造JDK
命令行方便操作,可以验证路径,实际构造需要改写为dockerfile构造。
运行一个nopasswd:1.0
docker run -it --name=JDK nopasswd:1.0 bash
不结束退出ctrl+p+q
将jdk压缩包放入容器
docker cp jdk-8u181-linux-x64_oracle.tar.gz JDK:/jdk.tar.gz
进入JDK
docker attach JDK
解压jdk
tar -zxvf jdk.tar.gz
将其放在安装目录中
mv jdk1.8.0_181/ /usr/local/
写入环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
测试
java -version

保存为镜像
不结束退出ctrl+p+q
docker commit -a shizi JDK java:1.0-test
Dockerfile构造JDK
Dockerfile
FROM nopasswd:1.0
ADD jdk-8u181-linux-x64_oracle.tar.gz /usr/local
ENV JAVA_HOME /usr/local/jdk1.8.0_181
ENV JRE_HOME $JAVA_HOME/jre
ENV CLASSPATH .:$JAVA_HOME/lib:$JRE_HOME/lib
ENV PATH $JAVA_HOME/bin:$PATH
LABEL maintainer="ShiZi"
CMD java -version
构造docker
docker build -t jdk:1.0 .
运行

构造hadoop
Dockerfile
FROM jdk:1.0
ADD hadoop-3.3.0.tar.gz /usr/local
ENV HADOOP_HOME=/usr/local/hadoop-3.3.0
ENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
COPY core-site.xml /usr/local/hadoop-3.3.0/etc/hadoop/core-site.xml
COPY hdfs-site.xml /usr/local/hadoop-3.3.0/etc/hadoop/hdfs-site.xml
COPY yarn-site.xml /usr/local/hadoop-3.3.0/etc/hadoop/yarn-site.xml
COPY mapred-site.xml /usr/local/hadoop-3.3.0/etc/hadoop/mapred-site.xml
LABEL maintainer="ShiZi"
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.3.0/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.3.0/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.3.0/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>namenode:9870</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.addtess</name>
<value>resourcemanager:8088</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop-3.3.0/etc/hadoop:/usr/local/hadoop-3.3.0/share/hadoop/common/lib/*:/usr/local/hadoop-3.3.0/share/hadoop/common/*:/usr/local/hadoop-3.3.0/share/hadoop/hdfs:/usr/local/hadoop-3.3.0/share/hadoop/hdfs/lib/*:/usr/local/hadoop-3.3.0/share/hadoop/hdfs/*:/usr/local/hadoop-3.3.0/share/hadoop/mapreduce/*:/usr/local/hadoop-3.3.0/share/hadoop/yarn:/usr/local/hadoop-3.3.0/share/hadoop/yarn/lib/*:/usr/local/hadoop-3.3.0/share/hadoop/yarn/*</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.0</value>
</property>
</configuration>
构造Docker
docker build -t hadoop:1.0
构造namenode
Dockerfile
FROM hadoop:1.0
CMD if [ ! -f /usr/local/hadoop-3.3.0/tmp/dfs/name/current/VERSION ];then hadoop namenode -format;fi && hadoop-daemon.sh start namenode && tail -f /dev/null
LABEL maintainer="ShiZi"
构造Docker
docker build -t namenode:1.0 .
构造datanode
Dockerfile
FROM hadoop:1.0
CMD hadoop-daemon.sh start datanode && tail -f /dev/null
LABEL maintainer="ShiZi"
构造Docker
docker build -t datanode:1.0 .
构造resourcemanager
Dockerfile
FROM hadoop:1.0
CMD yarn-daemon.sh start resourcemanager && tail -f /dev/null
LABEL maintainer="ShiZi"
构造Docker
docker build -t resourcemanager:1.0 .
构造nodemanager
Dockerfile
FROM hadoop:1.0
CMD yarn-daemon.sh start nodemanager && tail -f /dev/null
LABEL maintainer="ShiZi"
构造Docker
docker build -t nodemanager:1.0 .
使用官方mysql构造docker
Dockerfile
FROM mysql:5.7.36
CMD service mysql start && mysql -u root -p123456 -e "use mysql;grant all privileges on *.* to root@'%' identified by '123456' with grant option;flush privileges;" && tail -f /dev/null
LABEL maintainer="ShiZi"
构造Docker
docker build -t hive_mysql:1.0 .
构造Hive
Dockerfile
FROM hadoop:1.0
ADD hive.tar.gz /usr/local/
COPY hive-env.sh /usr/local/hive/conf/
COPY hive-site.xml /usr/local/hive/conf/
COPY mysql-connector-java-5.1.32.jar /usr/local/hive/lib/
ENV HIVE_HOME /usr/local/hive
ENV PATH $HIVE_HOME/bin:$PATH
RUN rm /usr/local/hive/lib/guava-19.0.jar && \\
cp /usr/local/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/
CMD if [ ! -d /mysql_data/hive ]; then schematool -initSchema -dbType mysql -verbos;fi && \\
hive --service metastore
LABEL maintainer="ShiZi"
编排Docker
docker-compose.yml
version: '3.8'
services:
namenode:
image: namenode:1.0
ports:
- "9000:9000"
- "9870:9870"
hostname: namenode
links:
- datanode
- resourcemanager
- nodemanager
- mysql
- hive
volumes:
- /data/hdfs/name:/usr/local/hadoop-3.3.0/tmp/
datanode:
image: datanode:1.0
volumes:
- /data/hdfs/data:/usr/local/hadoop-3.3.0/tmp/
resourcemanager:
image: resourcemanager:1.0
ports:
- "8030-8033:8030-8033"
- "8088:8088"
hostname: resourcemanager
nodemanager:
image: nodemanager:1.0
mysql:
image: hive_mysql:1.0
ports:
- "3306:3306"
hostname: mysql
volumes:
- /data/mysql:/var/lib/mysql
hive:
image: hive:1.0
ports:
- "9083:9083"
hostname: hive
volumes:
- /data/mysql:/mysql_data:ro
跨主机部署
这里使用docker原生跨主机解决方案overlay网络,但仅使用overlay网络也会有诸多问题,但好在有可以忍受的替代方案。
创建overlay网络(自定义网段),这里自定义网段是为了方便之后方便映射
docker network create -d overlay --subnet 10.1.0.0/24 --ip-range 10.1.0.0/24 --gateway 10.1.0.1 hadoop_net_hadoop
编排集群
docker-compose.yml
version: '3.8'
networks:
default:
external:
name: hadoop_net
services:
namenode:
image: namenode:1.0
hostname: namenode
networks:
default:
ipv4_address: 10.1.0.100
volumes:
- /data_online/hdfs/name:/usr/local/hadoop-3.3.0/tmp/
datanode:
image: datanode:1.0
volumes:
- /data_online/hdfs/data:/usr/local/hadoop-3.3.0/tmp/
resourcemanager:
image: resourcemanager:1.0
hostname: resourcemanager
networks:
default:
ipv4_address: 10.1.0.110
nodemanager:
image: nodemanager:1.0
mysql:
image: hive_mysql:1.0
hostname: mysql
volumes:
- /data_online/mysql:/var/lib/mysql
networks:
default:
ipv4_address: 10.1.0.120
hive:
image: hive:1.0
hostname: hive
- /data_online/mysql:/mysql_data:ro
networks:
default:
ipv4_address: 10.1.0.130
这里没有使用-p来暴露端口的原因是实验发现当使用-p来暴露overlay网络中容器的端口的时候,docker会写入一个nat规则将端口上的请求转发到容器的虚拟ip这个ip不能连接到容器(但3306端口的mysql访问可以,不知道为什么),容器中并没有防火墙服务,只能初步断定为overlay网络的问题。
具体https://blog.csdn.net/shi_zi_183/article/details/121551059
改写路由
route add -net 10.1.0.0 netmask 255.255.255.0 gw 172.18.0.1 dev docker_gwbridge
编写nat
iptables -t nat -A DOCKER -p tcp -m tcp --dport 9870 -j DNAT --to-destination 10.1.0.100:9870
iptables -t nat -A DOCKER -p tcp -m tcp --dport 8088 -j DNAT --to-destination 10.1.0.110:8088
iptables -t nat -A DOCKER -p tcp -m tcp --dport 3306 -j DNAT --to-destination 10.1.0.120:3306
iptables -t nat -A DOCKER -p tcp -m tcp --dport 9083 -j DNAT --to-destination 10.1.0.130:9083
新建挂载目录
mkdir -p /data_online/hdfs/name
mkdir -p /data_online/hdfs/data
mkdir -p /data_online/mysql
赋予权限
chmod 777 -R /data_online
node1
cd hadoop_node1
docker-compose up -d mysql namenode datanode resourcemanager nodemanager hive
node2
cd hadoop_node2
docker-compose up -d datanode nodemanager

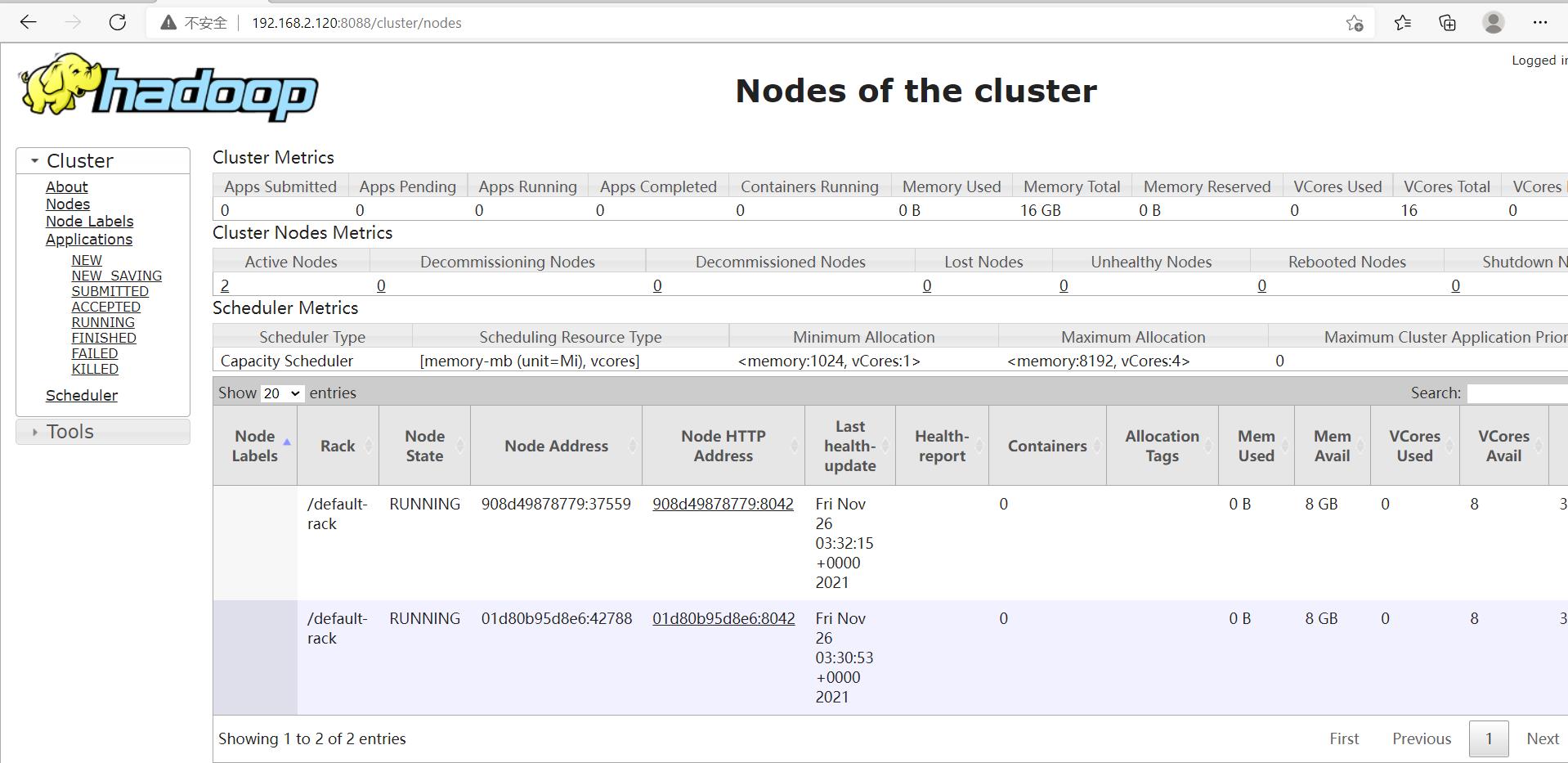
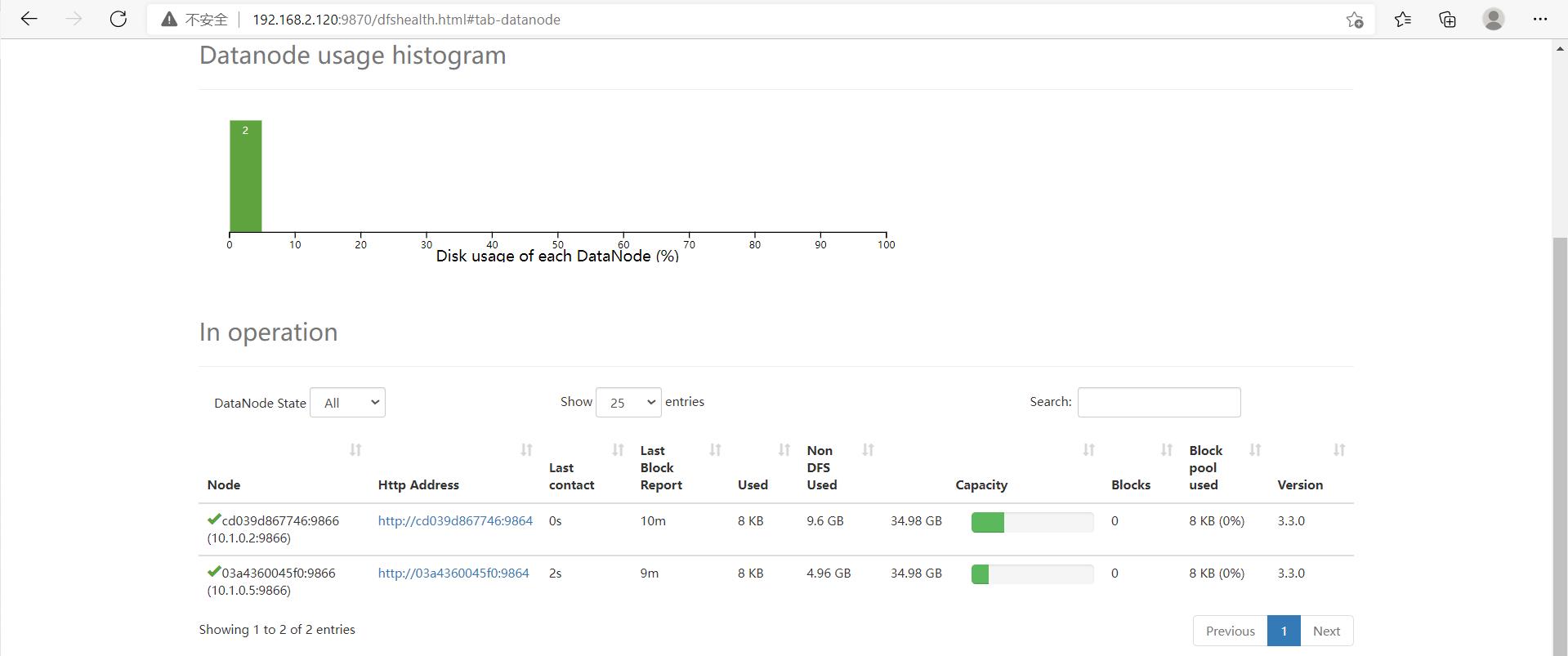
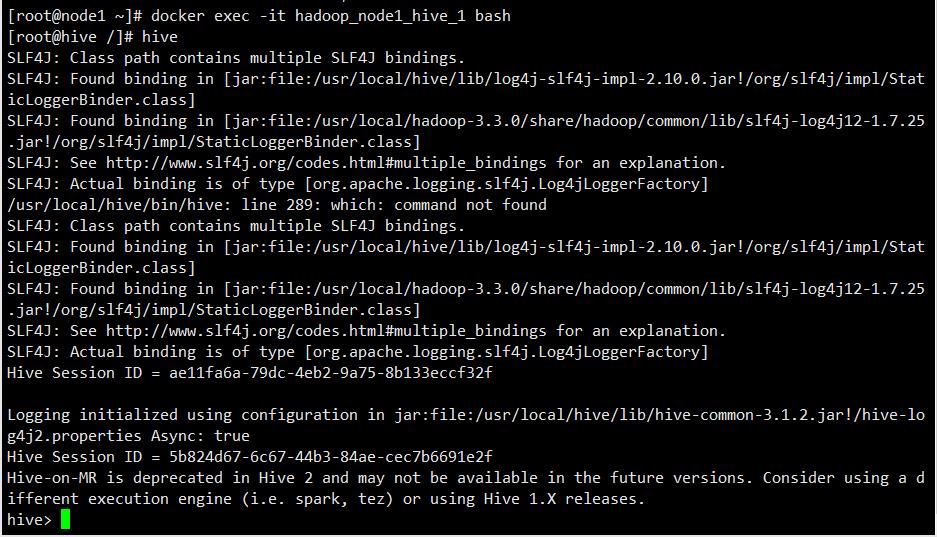
可以看到构建的比较成功
但使用docker构建集群还是有一些很难解决的问题
- 配置文件修改需要重新编译docker
- 高可用hadoop集群难以构建
- 需要手动配置nat转发和路由
- 等等。。。
但我相信docker作为生产环境中普遍使用的工具,现在一定有更多优秀的解决方案。待我学会之后,会再次补充。
以上是关于构造业务需要的docker()的主要内容,如果未能解决你的问题,请参考以下文章