漫谈C语言指针
Posted 半岛铁盒里的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了漫谈C语言指针相关的知识,希望对你有一定的参考价值。
更多博文,请看音视频系统学习的浪漫马车之总目录
C内存与指针:
漫谈C语言内存管理
漫谈C语言指针(一)
漫谈C语言指针(二)
漫谈C语言指针(三)
上一篇漫谈C语言指针(二) 主要讲了指针和数组的关系、字符串指针、指针变量作为函数参数,就像电影最后进入高潮一样,接下来,指针的内容将进入深水区,大家坐稳扶好,马上出发~
今天要讲的内容有:二级指针、二维数组、指针数组、函数指针、函数指针数组、结构体指针。为什么说的深水区呢?因为前面的2篇只要看懂概念基本就能学会,但是这一章,概念开始变绕,不再平坦,甚至有点花俏,所以需要消费一些脑细胞才可以理解,不过不用担心,我对我的表达有自信(看不懂也勿喷。。)
二级指针
二级指针,顾名思义,就是指针的指针,一个指针指向另一个指针,即指针存放的数值是另一个指针的地址。
假设有一个 int 类型的变量 a,p1是指向 a 的指针变量,p2 又是指向 p1 的指针变量,它们的关系如下图所示:

用代码定义就是:
int a =5;
int *p1 = &a;
int **p2 = &p1;
以此类推还有多级指针,但一般用到二级指针,更多级的指针很少用到。
那二级指针的作用是什么呢?
在函数内部修改函数外部一个指针的指向:
在漫谈C语言指针(一) 中的“通过指针在函数内部修改函数外部变量值”章节讲过,要在函数内改变函数外定义的变量的数值,要通过指针来传参,那以此类推,二级指针的一个作用就是通过二级指针传参,在函数内部修改函数外部一个指针的指向。
比如:
void secondPointer(int **a)
int *p = static_cast<int *>(malloc(sizeof(int)));//用malloc保证离开函数后内存不会释放
*p = 5;
*a = p;//改变a函数外传入的二级指针指向的指针的指向
printf("secondPointer *a %#X\\n", *a);
int main()
int i = 10;
int *a = &i;
printf("before secondPointer a %#X\\n", a);//改变a之前的指向之前a的指向地址
secondPointer(&a);
printf("after secondPointer a %#X\\n", a);//改变a之后的指向之前a的指向地址
printf("after secondPointer *a %d\\n", *a);//改变a之前的指向之前a的指向地址
运行结果:
before secondPointer a 0X62FE1C
secondPointer *a 0XDB1C40
after secondPointer a 0XDB1C40
after secondPointer *a 5
可以看到通过secondPointer函数的处理,a成功指向了5(即函数中p指向的变量),地址也发生了改变。
二维数组
二级指针的另一个常用的作用,就是对二维数组的操作。
先说下二维数组,简单来说就是数组的数组,每个数组元素都是一个数组,在概念上是二维的,有行和列,但在内存中所有的数组元素都是连续排列的,它们之间没有“缝隙”。以下面的二维数组 a 为例:
int a[3][4] = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 ;
从概念上理解,a 的分布像一个矩阵:
0 1 2 3
4 5 6 7
8 9 10 11
但在内存中,a 的分布是一维线性的,整个数组占用一块连续的内存:

C语言中的二维数组是按行排列的,也就是先存放 a[0] 行,再存放 a[1] 行,最后存放 a[2] 行;每行中的 4 个元素也是依次存放。数组 a 为 int 类型,每个元素占用 4 个字节(假设当前环境int占用4字节),整个数组共占用 4×(3×4) = 48 个字节。
首先要引入数组指针的概念,即指向数组的指针,定义如下:
int (*p)[4] = &a;//数组指针p指向数组a
与数组名不同的是,数组名在表达式中表示的是数组第一个元素的首地址,所以对数组名算术运算的步长是数组元素的长度,而数组指针的步长是真整个数组的大小(如果对步长不理解,请看:漫谈C语言指针(一) 指针算术运算一节):
int a[] = 1,2,3,4,5,6;
int (*p)[6] = &a;
printf("secondPointer sizeof(int) %d\\n", sizeof(int));
printf("secondPointer p %#X\\n", p);
printf("secondPointer p+1 %#X\\n", p+1);
运行结果:
secondPointer sizeof(int) 4
secondPointer p 0X62FE00
secondPointer p+1 0X62FE18
注意到 p+1比p大了24字节(10进制),刚好是6个int类型元素的大小。
C语言允许把一个二维数组分解成多个一维数组来处理。对于数组 a,它可以分解成三个一维数组,即 a[0]、a[1]、a[2]。每一个一维数组又包含了 4 个元素,例如 a[0] 包含 a[0][0]、a[0][1]、a[0][2]、a[0][3]。
假设数组 a 中第 0 个元素的地址为 1000,那么每个一维数组的首地址如下图所示:

在漫谈C语言指针(二) 中说过,一维数组a的数组名在表达式中指向数组首元素首地址,指向的类型是数组元素类型。以此类推,上图的二维数组a,a指向第一个元素(即数组a[0],这里a[n]表示第n个数组(第n行)),因为a作为指针指向的类型为数组,所以步长为数组的长度,在这里即为4*sizeof(int)。而因为a[n]表示第n个数组,所以a[n]本身可以看作第n个数组的数组名,即a[n]本身是一个指向第n个数组的首元素首地址的指针,指向的类型为第n个数组的元素类型,所以步长为数组元素类型大小,在这里即为sizeof(int)。
int a[3][4] = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 ;
printf("sizeof(*(a)):%d\\n", sizeof(*a));//求出a指向的数据的大小
printf("a:%d\\n", a);
printf("a+1%:d\\n", a+1);//求a的步长(其实和sizeof(*a)一样大)
printf("sizeof(*a[0]):%d\\n", sizeof(*a[0]));//求出a[0]指向的数据的大小
printf("a[0]:%d\\n", a[0]);
printf("a[0]+1:%d\\n", a[0]+1);//求a[0]的步长(其实和sizeof(*a[0])一样大)
printf("&a:%d\\n", &a);//要记得数组名在&符号的时候不会转化为指针,所以是对数组取地址
printf("&a+1:%d\\n", &a+1);//看下&a的步长
运行结果:
sizeof(*(a)):16
a:6487536
a+1%:d
sizeof(*a[0]):4
a[0]:6487536
a[0]+1:6487540
&a:6487536
&a+1:6487584
可以看出,a和a[0]指向的地址都是整个二维数组第一个数组的第一个元素的首地址,但是a步长是16,即指向的类型是int[4],而a[0]步长为4,即指向类型为int。
根据结果可以进一步可以推导出,a+n指向的是第n+1个数组的首元素首地址,指向的类型是一个一维数组,所以(a+n)表示的是一个数组。a[x]+y指向的是第x+1数组第y+1个元素首地址,指向类型是一个数组元素,又因为之前讲过a[x]等同于(a+x),又因为a[x]+y相当于一维数组a[x]偏移了y个步长,即a[x]+y等价于*((a+x)+y),表示的是一个数组元素**。
总结下就是:
a[i] ==(a+i)
a[i][j] == * (a[i]+j) == * (*(a+i)+j)
从而进一步可以优化二维数组的遍历:
int a[3][4] = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 ;
for(int i=0; i<3; i++)
for(int j=0; j<4; j++)
printf("value :%d\\n",*(*(a+i)+j));
另外从运行结果可以看出,&a+1的地址比&a大了48,正好是12*sizeof(int),也就是整个数组a占用的空间大小,这个和漫谈C语言指针(二) 说的一维数组一致
指针数组
指针数组,顾名思义,指针的数组,即数组的元素为指针。
首先要注意的是指针数组的定义:
前面将的数组指针的定义是:
int (*p)[2];
这里因为[]优先级高于 ,所以加了(),让和p先结合成一个指针,然后才和[]结合使指针指向数组。
而指针数组的定义为:
int *p[2];
没错,只是少了个(),概念就完全不同,让p先和[]结合,所以p是个数组,然后和*结合,指明数组元素类型为指针。
指针数组可以定义如下:
int a = 1, b = 2, c = 3;
//定义一个指针数组
int *arr[3] = &a, &b, &c;//创建一个指针数组
之前我们说数组名在表达式中会转化为指向数组首元素的指针,那指针数组的数组名也一样会在表达式中转化为指针,该指针自然也是指向数组首元素,而数组首元素是指针,所以这个数组名转化的指针就顺理成章成为了一个二级指针。
因为数组名arr转化为二级指针,所以要加2个**来取值:
int a = 1, b = 2, c = 3;
//定义一个指针数组
int *arr[3] = &a, &b, &c;//创建一个指针数组
printf("%d, %d, %d\\n", **(arr+0), **(arr+1), **(arr+2));//因为数组名arr转化为二级指针,所以要加2个**来取值
运行结果:
1, 2, 3
指针数组常用的一个地方莫过于和字符串数组的使用:
char *str[3] =
"man",
"woman",
"pig"
;
记住这里str必须是一个指针数组,因为在字符串本身存储在常量区,在表达式中会转化为一个指向char的指针(首字符地址)。
所以在读取字符创数组的某个字符串的某个字符的时候,往往使用二级指针去操作,比如打印出上面str中第二个字符串的第4个字符:
printf("%c\\n", *(*(str+1)+3));//*(str+1)是得到"woman"的首地址,*(*(str+1)+3))是"woman"的首地址偏移3个char之后,再取值,即‘a’。
运行结果:
a
函数指针
一个数组占用一段连续的内存区域,一个函数同样也占用一段连续的内存区域,在C语言的设计中,也和数组一样,函数名也可以代表函数的首地址~~那么,让一个指针去持有函数的首地址也变得顺理成章了,这个指针,理所当然就叫做函数指针。
函数指针的定义如下:
int(*p)(int, int);
这个语句就定义了一个指向函数的指针变量 p。首先它是一个指针变量,所以要有一个“ * ”,即( * p);
其次前面的 int 表示这个指针变量可以指向返回值类型为 int 型的函数;后面括号中的两个 int 表示这个指针变量可以指向有两个参数且都是 int 型的函数。所以合起来这个语句的意思就是:定义了一个指针变量 p,该指针变量可以指向返回值类型为 int 型,且有两个整型参数的函数。
该指针p指向的类型就是int (int,int)函数(是的,把函数也看做一个类型,由入参和返回值决定)
总结下通用格式就是:
函数返回值类型 ( 指针变量名) (函数参数列表);*
那么函数指针的意义是什么呢?
熟悉Java的童鞋一定知道回调接口这个东西,当我们在一个方法或者类中有一段逻辑需要由外部传入的时候,经常会用回调接口,熟悉kotlin的童鞋一定知道函数在kotlin中是可以作为成员变量和参数的,那么在C中函数指针的作用是很类似的。
比如calculate是一个计算的函数,但是具体怎么计算需要外部传入,这里函数指针p作为这个传入的参数表示某一个计算具体逻辑:
/**
* 加法运算
* @param a
* @param b
* @return
*/
int plus(int a,int b)
return a+b;
/**
* 减法运算
* @param a
* @param b
* @return
*/
int sub(int a,int b)
return a-b;
/**
* 计算函数,但具体方式由传入的函数p决定
* @param a
* @param b
* @param p
* @return
*/
int calculate(int a,int b,int (*p)(int,int))
return p(a,b);
int main()
int a = 2;
int b = 1;
//此时决定calculate具体的计算方式
printf("calculate plus %d\\n", calculate(a,b,plus));
printf("calculate plus %d\\n", calculate(a,b,sub));
运行结果:
calculate plus 3
calculate plus 1
结构体指针:
在看过前面几篇文章之后,这个其实就是指向一个结构体对象的指针,和Java的引用如出一辙,很容易理解。
假如有一只猫的结构体:
struct Cat
int head;//猫头
int tail;//猫尾
;
Cat cat;
cat.head = 5;
Cat* c = &cat;
printf("c->head: %d\\n", c->head);
(其实也没什么好讲的,只是把基本类型改为结构体类型,这对熟悉面向对象语言的童鞋来说太easy了~~)
不过这里重点要讲个有意思的东西,这也是解释为什么指针是个强大而危险的工具的一个例子:
原本cat.tail是int类型,但是假如我们闲的蛋疼试试这样强转cat.tail的指针类型,然后再对转化后的指针取值获取其head的值,会发生什么事呢:
((Cat*)&(cat.tail))->head=12;
printf("&(cat.head): %d\\n", &(cat.head));//为了更好说明,打印出head地址
printf("&(cat.tail): %d\\n", &(cat.tail));//为了更好说明,打印出tail地址
printf("cat.head: %d\\n", cat.head);
printf("cat.tail: %d\\n", cat.tail);
运行结果:
&(cat.head): 6487572
&(cat.tail): 6487576
cat.head: 0
cat.tail: 12
为什么打印出来会是cat.head: 0,cat.tail: 12?明明是给head赋值了12的。
结果是不是有点神奇,再缕下我们做了啥。
((Cat*)&(cat.tail))->head=12;
这行代码中,首先我们给了计算机一个猫尾巴(cat.tail),然后又告诉计算机,把这尾巴当做一个猫来看待!再给这只猫的头赋值12,然后计算机开始晕车了,猫头猫尾早已分不清。。
如果你真的理解了漫谈C语言指针(一) 中谈到的指针步长,那应该不难知道原因。因为其实计算机根本不管你给的是猫还是狗,它只管内存,这里给的结构体Cat,对于计算机来说就是开辟了一段内存空间,而计算机当然也不会理解head和tail是什么,只知道这是Cat开辟的内存内部的2段内存空间,
通过观察运行结果中head和tail的地址,可以看出,head和tail是在一块连续的内存中的,像这样:

当&(cat.tail)操作是,指针指向是这样的:
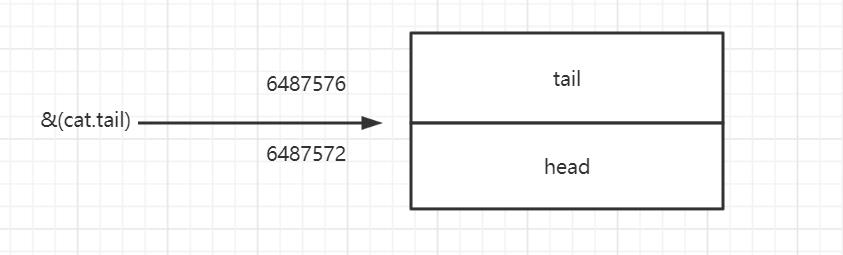
关键点来了,当强转指针类型的时候,(Cat*)&(cat.tail),计算机把Cat当做上方蓝色部分的:
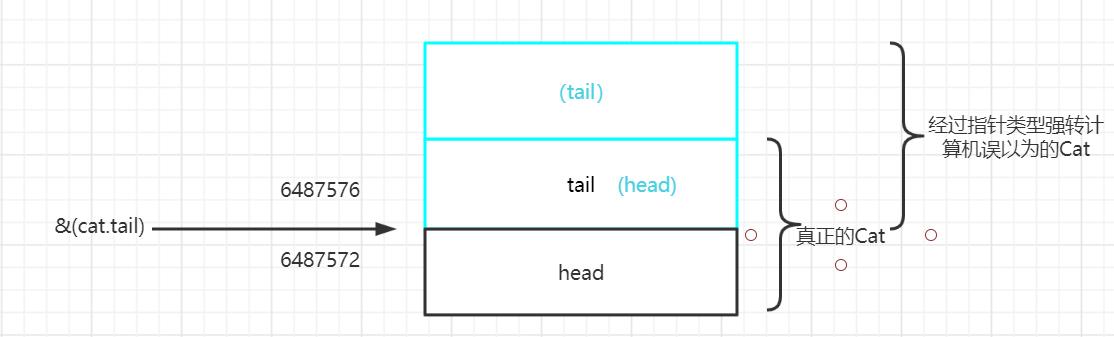
此时执行((Cat*)&(cat.tail))->head=12;,计算机已经把真正的tail当做head了,所以表面上是赋值给head,其实那是假的,真正的Cat是赋值给了tail,所以printf(“cat.tail: %d\\n”, cat.tail);打印出来才是12。
类似的例子还可以看下数组:
int arr[5];
arr[3] = 1 << 16;
**((short*)arr)[6] = 2;**//关键,对arr指针进行强转为short类型,然后指针往前偏移6个步长
printf("arr[3]: %d\\n", arr[3]);
打印结果怎样呢?
运行结果:
arr[3]: 65538
经过了结构体的例子,大家应该可以推测出原因了。
在运行了arr[3] = 1 << 16;之后,在内存中的状态是:

而执行了((short*)arr)[6] 指针强转之后,在计算机眼里,arr变成了:
(当前环境是小端模式)

执行了((short*)arr)[6] = 2;之后:

执行printf(“arr[3]: %d\\n”, arr[3]);的时候,上图的2个小格子又合并起来,得到结果为65538(小端模式,所以右边的小格子是高位)
当然因为C语言数组是不做越界检查的,所以非常自由,还可以做如下骚操作:
int i = *(((short*)(&arr[-1]))+4);
这个大家基于上岸的例子应该能想到答案吧~~
之所以讲了上面几个骚味十足的操作,目的在于让大家可以真正从内存的角度看待指针,不要被表面所迷惑,一定要根据漫谈C语言指针(一) 中指针算术运算小节最后讲的灵魂拷问去研究指针相关问题,真正从本质理解指针。
关于C语言的博文暂时到这里,下一篇开始C++的博文:初尝C++的世界
以上是关于漫谈C语言指针的主要内容,如果未能解决你的问题,请参考以下文章