zone watermark水位控制
Posted Loopers
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zone watermark水位控制相关的知识,希望对你有一定的参考价值。
本节我们来分析下zone的水位控制,在zone那一节中,我们将重点放在了free_area中,故意没有分析zone中的水位控制,本节在重点分析zone中的水位控制。
struct zone
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
enum zone_watermarks
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
;
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])每个zone中存在三个水位值。MIN水位,LOW水位,HIGH水位。比如下图的NORMAL_ZONE中存在HIGH,LOW,MIN水位三个值
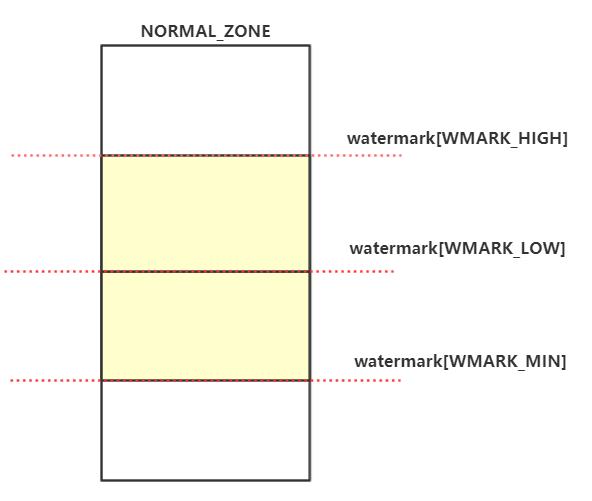
那HIGH,LOW,MIN三个水位值是如何计算出来的呢? 先来看如下几个字段的含义
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;- spanned_pages: 代表的是这个zone中所有的页,包含空洞,计算公式是: zone_end_pfn - zone_start_pfn
- present_pages: 代表的是这个zone中可用的所有物理页,计算公式是:spanned_pages-hole_pages
- managed_pages: 代表的是通过buddy管理的所有可用的页,计算公式是:present_pages - reserved_pages
- 三者的关系是: spanned_pages > present_pages > managed_pages
可以看下我手上的机器的zoneinfo信息
root:/ # cat /proc/zoneinfo
pages free 87512
min 2702
low 10899
high 11574
spanned 2094976 ==> spanned_pages
present 1959807 ==> present_pages
managed 1911161 ==> managed_pages
protection: (0, 0)知道上述了三个值之后,我们来看源代码分析下HIGH,MIN,LOW水位的值是如何设置的
min_free_kbytes
在知道HIGH,MIN,LOW水位是如何获得的,先要知道min_free_kbytes值的含义
kernel/msm-4.19/Documentation/sysctl/vm.txt
min_free_kbytes:
This is used to force the Linux VM to keep a minimum number
of kilobytes free. The VM uses this number to compute a
watermark[WMARK_MIN] value for each lowmem zone in the system.
Each lowmem zone gets a number of reserved free pages based
proportionally on its size.
Some minimal amount of memory is needed to satisfy PF_MEMALLOC
allocations; if you set this to lower than 1024KB, your system will
become subtly broken, and prone to deadlock under high loads.
Setting this too high will OOM your machine instantly.从上面的话得出了以下几点:
- min_free_kbyes代表的是系统保留空闲内存的最低限
- watermark[WMARK_MIN]的值是通过min_free_kbytes计算出来的
我们来看下代码是如何计算的:
unsigned long nr_free_buffer_pages(void)
return nr_free_zone_pages(gfp_zone(GFP_USER));
此函数计算DMA_ZONE和NORAML_ZONE中超过高水位页的个数
static unsigned long nr_free_zone_pages(int offset)
struct zoneref *z;
struct zone *zone;
/* Just pick one node, since fallback list is circular */
unsigned long sum = 0;
struct zonelist *zonelist = node_zonelist(numa_node_id(), GFP_KERNEL);
for_each_zone_zonelist(zone, z, zonelist, offset)
unsigned long size = zone->managed_pages;
unsigned long high = high_wmark_pages(zone);
if (size > high)
sum += size - high;
return sum;
对每个zone做计算,将每个zone中超过high水位的值放到sum中。超过高水位的页数计算方法是:managed_pages减去watermark[HIGH], 这样就可以获取到系统中各个zone超过高水位页的总和
int __meminit init_per_zone_wmark_min(void)
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (new_min_free_kbytes > user_min_free_kbytes)
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
else
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\\n",
new_min_free_kbytes, user_min_free_kbytes);
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
setup_per_zone_lowmem_reserve();
setup_per_zone_inactive_ratio();
return 0;
- lowmem_kbytes: 代表的意思是lowmem中超过高水位的页的总和,这里的单位是kbytes, 这就是lowmem中超过high水位的页乘以4这就是lowmem_kbytes
- new_min_free_kbytes = sqrt(lowmem_kbytes * 16) = √(lowmem_kbytes * 16)
- min_free_kbytes最小不能小于128K,最大不能超过65536K
- 到这里位置我们已经得出了min_free_kbytes的值
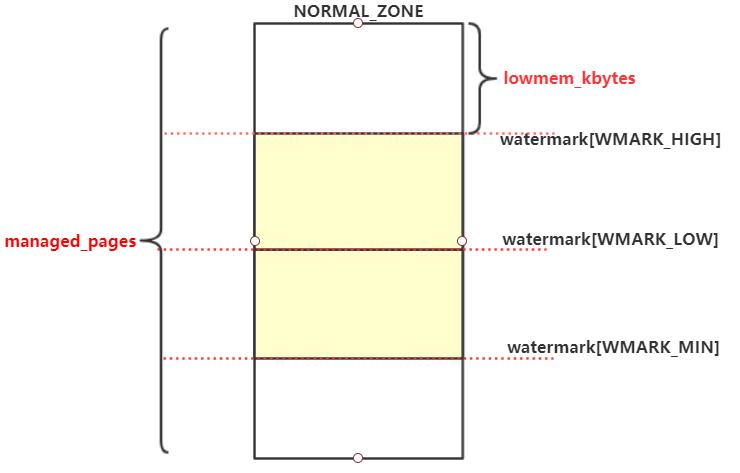
假设当前只有一个NORAML_ZONE,根据上面的公式managed_pages - watermark[WMARK_HIGH]的值就是这个NORMAL_ZONE中空闲的页面,然后经过int_sqrt可以计算出系统中可用空闲页面的最低限
举例:
root:/ # cat /proc/zoneinfo
Node 0, zone Normal
pages free 82075
min 2702
low 10899
high 11574
spanned 2094976
present 1959807
managed 1911161
protection: (0, 0)
root:/ # cat /proc/sys/vm/min_free_kbytes
10811根据上面的数据,我们来推到下min_free_kbytes

lowmem_kbytes = (1911161 - 11574 )*4= 1899587 *4 = 7598348
min_free_kbytes = int_sqrt(7598348 * 16) = 11026 ~= 10811
建立各个zone的水位值
原生的kernel代码,在kernel.org上下载的4.4的代码。
static void __setup_per_zone_wmarks(void)
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone)
if (!is_highmem(zone))
lowmem_pages += zone->managed_pages;
for_each_zone(zone)
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone->managed_pages;
do_div(tmp, lowmem_pages);
if (is_highmem(zone))
/*
* __GFP_HIGH and PF_MEMALLOC allocations usually don't
* need highmem pages, so cap pages_min to a small
* value here.
*
* The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
* deltas control asynch page reclaim, and so should
* not be capped for highmem.
*/
unsigned long min_pages;
min_pages = zone->managed_pages / 1024;
min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
zone->watermark[WMARK_MIN] = min_pages;
else
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->watermark[WMARK_MIN] = tmp;
zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + (tmp >> 2);
zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + (tmp >> 1);
__mod_zone_page_state(zone, NR_ALLOC_BATCH,
high_wmark_pages(zone) - low_wmark_pages(zone) -
atomic_long_read(&zone->vm_stat[NR_ALLOC_BATCH]));
spin_unlock_irqrestore(&zone->lock, flags);
/* update totalreserve_pages */
calculate_totalreserve_pages();
- pages_min = min_free_kbytes >> (PAGE_SHIFT - 10); //将最小保留的内存转化为以page为单位,最小预留的空闲页
- lowmem_pages: 代表的是除过HIGHMEM_ZONE的所有zone的managed_pages
- tmp = (u64)pages_min * zone→managed_pages; //用每个zone的manage_present的页数乘以pages_min的值
- do_div(tmp, lowmem_pages); //取商,得到的值就是min的值
- zone->watermark[WMARK_MIN] = tmp; //设置MIN水位的值
- zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + (tmp >> 2); //LOW水位的值=MIN+MIN/4=125%MIN
- zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + (tmp >> 1); //HIGH水位的值=MIN + MIN/2 = 150%MIN
举例说明:
root@root:~$ cat /proc/zoneinfo //ubuntu机器
Node 0, zone DMA
pages free 3973
min 16
low 20
high 24
spanned 4095
present 3998
managed 3973LOW = MIN + MIN/4 = 16 + 16/4 = 16 + 4 =20
HIGH = MIN + MIN/2 = 16 + 16/2 = 16+8 = 24
Android机器上水位的计算
上面我们详细计算了ubuntu机器上MIN, LOW, HIGH水位的计算方法,我们这里详细描述下android机器上水位的计算,同时也需要了解下android上为啥会出现不一样的算法
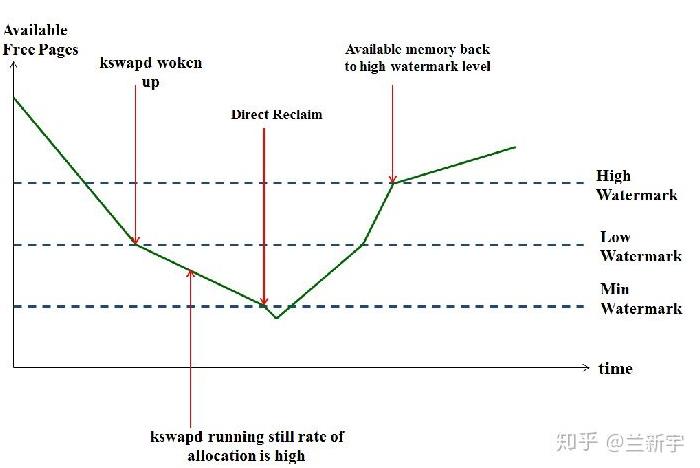
这个图画的非常的清楚很直观
- 我们分配页第一次尝试是从LOW水位开始分配的,当所剩余的空闲页小于LOW水位的时候,则会唤醒Kswapd内核线程进行内存回收
- 如果回收内存效果很显著,当空闲页大于HIGH水位的时候,则会停止Kswapd内核线程回收
- 如果回收内存效果不明显,当空闲内存直接小于MIN水位的时候,则会进行直接的内存回收(Direct-reclaim),这样空闲内存就会逐渐增大
- 当回收效果依然不明显的时候,则会启动OOM杀死进程
明白了上述的背后原理后,我们接着分析下android版本上的水位计算方法
比如上面ubunut的水位,其中min=16, low=20, high=24
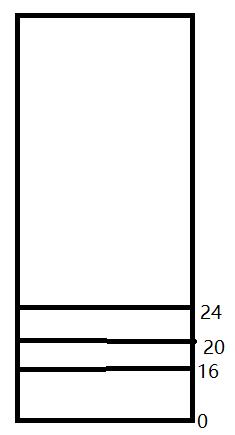
比如当前空闲内存是在LOW水位以下MIN以上,这时候后台会启动Kswaped内核线程在进程内存回收,假设这时候突然有一个很大的进程需要很大的内存请求,这样一来Kswaped回收速度赶不上分配速度,内存一下掉到了MIN水位,这样直接就进行了直接回收,直接回收很影响系统的性能的。这样看来linux原生的代码涉及MIN-LOW之间的间隙太小,很容易导致进入直接回收的情况的。所以在android的版本上增加了一个变量:extra_free_kbytes
static void __setup_per_zone_wmarks(void)
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long pages_low = extra_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone)
if (!is_highmem(zone))
lowmem_pages += zone->managed_pages;
for_each_zone(zone)
u64 min, low;
spin_lock_irqsave(&zone->lock, flags);
min = (u64)pages_min * zone->managed_pages;
do_div(min, lowmem_pages);
low = (u64)pages_low * zone->managed_pages;
do_div(low, vm_total_pages);
if (is_highmem(zone))
/*
* __GFP_HIGH and PF_MEMALLOC allocations usually don't
* need highmem pages, so cap pages_min to a small
* value here.
*
* The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
* deltas control asynch page reclaim, and so should
* not be capped for highmem.
*/
unsigned long min_pages;
min_pages = zone->managed_pages / 1024;
min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
zone->_watermark[WMARK_MIN] = min_pages;
else
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->_watermark[WMARK_MIN] = min;
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
min = max_t(u64, min >> 2,
mult_frac(zone->managed_pages,
watermark_scale_factor, 10000));
zone->watermark_boost = 0;
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) +
low + min;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) +
low + min * 2;
spin_unlock_irqrestore(&zone->lock, flags);
/* update totalreserve_pages */
calculate_totalreserve_pages();
extra_free_kbytes此值就是用来增加MIN和LOW之间的间隙的。我们再来看下android版本下的水位计算
- lowmem_pages += zone→managed_pages; //所有lowmem zone的managed_pages总和
- min = (u64)pages_min * zone→managed_pages;
- do_div(min, lowmem_pages); //min水位的的计算方法一样
- low = (u64)pages_low * zone→managed_pages;
- do_div(low, vm_total_pages); //low水位的值是通过extra_free_kbytes计算的
- zone->_watermark[WMARK_MIN] = min; //min水位
- zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + low + min = 2min + low
- zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + low + 2*min = 3min + low
android手机举例说明:
root:/ # cat /proc/zoneinfo
Node 0, zone Normal
pages free 56198
min 2702
low 10899
high 11574
spanned 2094976
present 1959807
managed 1911161
protection: (0, 0)
root:/ # cat /proc/sys/vm/extra_free_kbytes
30375可以看到min和low之间的距离 已经差的很大了
以上是关于zone watermark水位控制的主要内容,如果未能解决你的问题,请参考以下文章