Huffman编码之文件的解/压缩
Posted Xiao__Tian__
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Huffman编码之文件的解/压缩相关的知识,希望对你有一定的参考价值。
问题描述:
生活中文件压缩技术可谓随处可见,在数据的密集型传输中文件压缩是一项重要的实用性技术。例如:较大文件的下载,传输等。常见的文件压缩工具有winRAR,2345好压,快压(KuaiZip)等,这些工具已经开发的相当牛逼,但是作为入门级的程序员来说,不能只停留在观摩的立场上,扮演使用者的角色。有必要深入了解其底层的基础实现方式,掌握基础的文件压缩原理,所以在此将其视为一个小型项目列出,以供大家交流探讨,相互学习....
★在此之前,先来说说什么是文件压缩,用以抛出一个基础概念。
文件压缩:一个较大的文件经压缩后,产生了另一个较小容量的文件。而这个较小容量的文件,称其是这些较大容量的(可能一个或一个以上的文件)的压缩文件。而压缩此文件的过程称为文件压缩。目前互联网络上大家常用的FTP文件服务器上的文件大多属于压缩文件,文件下载后必须先解压缩才能够使用;另外在使用电子邮件附加文件功能的时候,最好也能事先对附加文件进行压缩处理。
文件压缩的原理:目前压缩技术可分为通用无损数据压缩与有损压缩两大类,但不管是采用何种技术模型,其本质内容都是一样的,即都是通过某种特殊的编码方式将数据信息中存在的重复度、冗余度有效地降低,从而达到数据压缩的目的。比如:“中国”是“中华人民共和国”的简称,但前者的字数是2,后者则是7,但我们都不会对它们俩所要表达的意思产生误解,这是因为前者保留了信息中最“关键点”。同时,作为有思维能力的人类,我们可以根据前后词汇关系和知识积累,就可推断出其原来的全部信息。压缩技术也一样,在不影响文件的基本使用的前提下,只保留原数据中一些“关键点”,去掉了数据中的重复的、冗余的信息,从而达到压缩的目的。这就是文件压缩技术所要遵循的最基本原理。
★在这里运用的是基于Huffman编码的方式实现文件的压缩和解压缩。
Huffman算法:哈夫曼是一种常用的压缩方法,是1952年为文本文件建立的,其基本原理是频繁使用的数据用较短的代码代替,很少使用的数据用较长的代码代替,每个数据的代码各不相同。这些代码都是二进制码,且码的长度是可变的。如: 有一个原始数据序列,ABACCDAA则编码为A(0),B(10),C(110),(D111),压缩后010011011011100。产生霍夫曼编码需要对原始数据扫描两遍,第一遍扫描要精确地统计出原始数据中的每个值出现的频率,第二遍是建立霍夫曼树并进行编码,由于需要建立二叉树并遍历二叉树生成编码,因此数据压缩和还原速度都较慢,但简单有效,因而得到广泛的应用。 哈夫曼算法在改变任何符号二进制编码引起少量密集表现方面是最佳的。
※Hufman压缩的特性:1.该算法是依赖于原始数据的,并且Huffman树为每一个节点生成的对应的Huffman编码是唯一的;2.其每个字符的编码长度是根据其出现的频率决定的,也就是说出现频率高的字符其编码短,频率低的字符其编码长。
▲有关于Huffman树的建立,编码等一系列相关过程的基础讲解在此就不做赘述了,后面会陆续更新博文。
主要一共四个模块: 1.建 树:创建Huffman树。
2.编 码:根据Huffman树实现编码,将编码结果和对应数据建立映射关系。
3.解 码:根据Huffman编码逆向获取解码信息。
4.文件操作:文件的打开和关闭。
废话不多说,直接上代码:
1.Huffman树的建立:
/****************************** HuffmanTree.h *****************************************************
************ 该文件是Huffman树的建立,为了增强其传参时的健壮性,在此使用了C++中的模板用以实现. ************
****************************************************************************************************************/
#pragma once
#include "Heap.h"
#include<assert.h>
template<class T>
struct HuffmanTreeNode
HuffmanTreeNode<T>* _left;
HuffmanTreeNode<T>* _right;
HuffmanTreeNode<T>* _parent;
T _weight;
HuffmanTreeNode(const T& x)
:_weight(x)
, _left(NULL)
, _right(NULL)
, _parent(NULL)
;
template<class T>
class HuffmanTree
typedef HuffmanTreeNode<T> Node;
public:
HuffmanTree()
:_root(NULL)
~HuffmanTree()
Destory(_root);
template <class T>
struct NodeCompare
bool operator()(Node *l, Node *r)
return l->_weight < r->_weight;
;
public:
void CreatTree(const T* a, size_t size, const T& invalid)
assert(a);
Heap<Node*, NodeCompare<T>> minHeap;
for (size_t i = 0; i < size; ++i)
if (a[i] != invalid)
Node* node = new Node(a[i]);
minHeap.Push(node);
while (minHeap.Size() > 1)
Node* left = minHeap.Top();
minHeap.Pop();
Node* right = minHeap.Top();
minHeap.Pop();
Node* parent = new Node(left->_weight + right->_weight);
parent->_left = left;
parent->_right = right;
left->_parent = parent;
right->_parent = parent;
minHeap.Push(parent);
_root = minHeap.Top();
Node* GetRootNode()
return _root;
void Destory(Node* root)
if (root)
Destory(root->_left);
Destory(root->_right);
delete root;
root = NULL;
private:
HuffmanTreeNode<T>* _root;
;
2.建堆及调整:
/****************************** Heap.h ****************************************************
************ 该文件是利用堆的相关特性,因为其数据成员中有数组,size,以及容量(capacity) ************
************ 所以在此直接使用C++中Vector用以实现. ************
***********************************************************************************************************/
#pragma once
#include <vector>
#include<assert.h>
// 小堆
template<class T>
struct Less
bool operator() (const T& l, const T& r)
return l < r;
;
template<class T>
struct Greater
bool operator() (const T& l, const T& r)
return l > r;
;
template<class T, class Compare = Less<T>>
class Heap
public:
Heap()
Heap(const T* a, size_t size)
for (size_t i = 0; i < size; ++i)
_arrays.push_back(a[i]);
// 建堆
for (int i = (_arrays.size() - 2) / 2; i >= 0; --i)
AdjustDown(i);
void Push(const T& x)
_arrays.push_back(x);
AdjustUp(_arrays.size() - 1);
void Pop()
assert(_arrays.size() > 0);
swap(_arrays[0], _arrays[_arrays.size() - 1]);
_arrays.pop_back();
AdjustDown(0);
T& Top()
assert(_arrays.size() > 0);
return _arrays[0];
bool Empty()
return _arrays.empty();
int Size()
return _arrays.size();
void AdjustDown(int root)
size_t child = root * 2 + 1;
Compare com;
while (child < _arrays.size())
if (child + 1<_arrays.size() &&
com(_arrays[child + 1], _arrays[child]))
++child;
if (com(_arrays[child], _arrays[root]))
swap(_arrays[child], _arrays[root]);
root = child;
child = 2 * root + 1;
else
break;
void AdjustUp(int child)
int parent = (child - 1) / 2;
while (child > 0)
if (Compare()(_arrays[child], _arrays[parent]))
swap(_arrays[parent], _arrays[child]);
child = parent;
parent = (child - 1) / 2;
else
break;
void Print()
for (size_t i = 0; i < _arrays.size(); ++i)
cout << _arrays[i] << " ";
cout << endl;
public:
/*T* _array;
size_t _size;
size_t _capacity;*/
vector<T> _arrays;
;
3.建立用于文件操作的文件:
/****************************** FileCompress.h *****************************************************
*********************** 该文件是用来实现具体的文件操作,其中有许多需要注意的小点. **************************
*****************************************************************************************************************/
#pragma once
#include"HuffmanTree.h"
#include<algorithm>
#include<windows.h>
#include<string.h>
using namespace std;
typedef long long Longtype;//为了扩大其范围,int型能处理的范围已经不能满足,所以定义Long Long型予以表示
struct FileInfo
unsigned char _ch;//这里必须为unsigned,否则会造成截断,所以从-128~127调至0~255.
Longtype _count;
string _code;
FileInfo(unsigned char ch = 0)
:_ch(ch)
, _count(0)
FileInfo operator+(FileInfo& file)
FileInfo tmp;
tmp._count = this->_count + file._count;
return tmp;
bool operator < (FileInfo& file)
return this->_count < file._count;
bool operator != (const FileInfo& file)const
return this->_count != file._count;
;
template<class T>
class FileCompress
public:
FileCompress()
for (int i = 0; i < 256; ++i)
_arr[i]._ch = i;
public:
bool Compress(const char* filename)
//1.打开文件,统计文件字符出现的次数
long long Charcount = 0;
assert(filename);
FILE* fOut = fopen(filename, "rb");//"rb"为以二进制方式读取文件,这里的b就是binary。"wb"为以二进制方式写入文件
assert(fOut);
char ch = fgetc(fOut);
while (ch != EOF)
_arr[(unsigned char)ch]._count++;
ch = fgetc(fOut);
Charcount++;
//2.生成对应的huffman编码
GenerateHuffmanCode();
//3.文件压缩
string compressFile = filename;
compressFile += ".compress";
FILE* fwCompress = fopen(compressFile.c_str(), "wb");
assert(fwCompress);
fseek(fOut, 0, SEEK_SET);
ch = fgetc(fOut);
char inch = 0;
int index = 0;
while(!feof(fOut))
string& code = _arr[(unsigned char)ch]._code;
for (size_t i = 0; i < code.size(); ++i)
inch = inch << 1;
if (code[i] == '1')
inch |= 1;
if (++index == 8)//对于形成的长串字符编码的切割,每8个bit为一个字节,便于读取
fputc(inch, fwCompress);
inch = 0;
index = 0;
ch = fgetc(fOut);
if (index)//考虑到可能会有切割完,剩余的字符码不够填充8个bit位的情况
inch = inch << (8 - index);
fputc(inch, fwCompress);
//4.配置文件,方便后续的解压缩;在日常的压缩解压时,有时我们会看到有.configure类型的配置文件,就是这个了,其实就是压缩和解压缩的中转站
string configFile = filename;
configFile += ".config";
FILE *fconfig = fopen(configFile.c_str(), "wb");
assert(fconfig);
char CountStr[128];
_itoa(Charcount >> 32, CountStr, 10);
fputs(CountStr, fconfig);
fputc('\\n', fconfig);
_itoa(Charcount & 0xffffffff, CountStr, 10);
fputs(CountStr, fconfig);
fputc('\\n', fconfig);
FileInfo invalid;
for (int i = 0; i < 256; i++)
if (_arr[i] != invalid)
fputc(_arr[i]._ch, fconfig);
fputc(',', fconfig);
fputc(_arr[i]._count + '0', fconfig);
fputc('\\n', fconfig);
fclose(fOut);
fclose(fwCompress);
fclose(fconfig);
return true;
//文件的解压
bool UnCompresss(const char* filename)
string configfile = filename;
configfile += ".config";
FILE* outConfig = fopen(configfile.c_str(), "rb");
assert(outConfig);
char ch;
long long Charcount = 0;
string line = ReadLine(outConfig);
Charcount = atoi(line.c_str());
Charcount <<= 32;
line.clear();
line = ReadLine(outConfig);
Charcount += atoi(line.c_str());
line.clear();
while (feof(outConfig))
//feof()遇到文件结束,函数值为非零值,否则为0。当把数据以二进制的形式进行存放时,可能会有-1值的出现,所以此时无法利用-1值(EOF)做为eof()函数判断二进制文件结束的标志。
line = ReadLine(outConfig);
if (!line.empty())
ch = line[0];
_arr[(unsigned char)ch]._count = atoi(line.substr(2).c_str());
line.clear();
else
line = '\\n';
HuffmanTree<FileInfo> ht;
FileInfo invalid;
ht.CreatTree(_arr, 256, invalid);
HuffmanTreeNode<FileInfo>* root = ht.GetRootNode();
string UnCompressFile = filename;
UnCompressFile += ".uncompress";
FILE* fOut = fopen(UnCompressFile.c_str(), "wb");
string CompressFile = filename;
CompressFile += ".compress";
FILE* fIn = fopen(CompressFile.c_str(), "rb");
int pos = 8;
HuffmanTreeNode<FileInfo>* cur = root;
ch = fgetc(fIn);
while ((unsigned char)ch != EOF)
--pos;
if ((unsigned char)ch &(1 << pos))
cur = cur->_right;
else
cur = cur->_left;
if (cur->_left == NULL && cur->_right == NULL)
fputc(cur->_weight._ch, fOut);
cur = root;
Charcount--;
if (pos == 0)
ch = fgetc(fIn);
pos = 8;
if (Charcount == 0)
break;
fclose(outConfig);
fclose(fIn);
fclose(fOut);
return true;
protected:
string ReadLine(FILE* fConfig)
char ch = fgetc(fConfig);
if (ch == EOF)
return "";
string line;
while (ch != '\\n' && ch != EOF)
line += ch;
ch = fgetc(fConfig);
return line;
void GenerateHuffmanCode()
HuffmanTree<FileInfo> hft;
FileInfo invalid;
hft.CreatTree(_arr, 256, invalid);
_GenerateHuffmanCode(hft.GetRootNode());
void _GenerateHuffmanCode(HuffmanTreeNode<FileInfo>* root)
if (root == NULL)
return;
_GenerateHuffmanCode(root->_left);
_GenerateHuffmanCode(root->_right);
if (root->_left == NULL && root->_right == NULL)
HuffmanTreeNode<FileInfo>* cur = root;
HuffmanTreeNode<FileInfo>* parent = cur->_parent;
string& code = _arr[cur->_weight._ch]._code;
while (parent)
if (parent->_left == cur)
code += '0';
else if (parent->_right == cur)
code += '1';
cur = parent;
parent = cur->_parent;
reverse(code.begin(), code.end());
private:
FileInfo _arr[256];
;
void TestFileCompress()
FileCompress<FileInfo> fc;
int begin1 = GetTickCount();
fc.Compress("C:\\\\Users\\\\Administrator.T47BQSRAR0SRP03\\\\Desktop\\\\Compress.txt");//此处路径是我的桌面路径,写成当前工作目录下的路径也可
int end1 = GetTickCount();//用以测试压缩用时
cout << end1 - begin1 << endl;
int begin2 = GetTickCount();
fc.UnCompresss("C:\\\\Users\\\\Administrator.T47BQSRAR0SRP03\\\\Desktop\\\\Compress.txt");
int end2 = GetTickCount();//用以测试解压用时
cout << end2 - begin2 << endl;
4.main文件,作用就不说了:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
using namespace std;
#include "FileCompress.h"
int main()
TestFileCompress();
return 0;
1.对于从解压文件中获取的是一个很长的字符串,如何对该字符串进行合理切割以便后续的解压缩。按固定比特位切割,若存在剩余字符且无法填满一个字节,解压缩时又该如何处理。解决:按1个byte拥有8个bit位进行存储,若最终有未填满一个byte的字符时,将填充后的位置不断偏移。
2.在需要从文件中读取字符的地方,需借用EOF做为判断文件是否结束的标志位,若该文件的类型为非文本文件的二进制文件时,会存在-1值做为有效值的情形出现,此时EOF无法做为该文件的结束标志。解决:此时应使用feof函数做为文件结束标志。
★测试(Release版本下测试,因为VS2013的Debug和Release的速度相差有些大,当然读者也可两个版本都试下):
测试一:第一个测试文件是创建了一个名称为a,内容为从字母A~Z的文本文档。
 ▲ 可以看到,其压缩和解压缩的时间都是零,因为此文档太小了,所以几乎是瞬时的。
▲ 可以看到,其压缩和解压缩的时间都是零,因为此文档太小了,所以几乎是瞬时的。
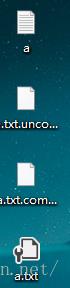 ▲可以看到生成了三个文件,从上往下依次是源文件,解压文件(uncompress),压缩文件(compress),配置文件(configure)。
▲可以看到生成了三个文件,从上往下依次是源文件,解压文件(uncompress),压缩文件(compress),配置文件(configure)。
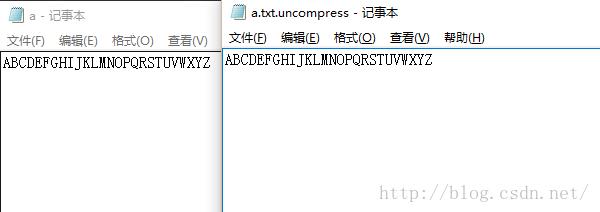 ▲解压文件和源文件的内容相同。
▲解压文件和源文件的内容相同。
测试二:既然小文件是可以的,那么大一点的文件呢?大文件里面不仅有字母数字,还有各类标点,符号,包括汉字等复杂情况。这里测试的第二个大文件是一个名称为compress,大小为6.35MB的文件。其内容为某大段代码,以及简答题等情况,而代码中就包含了数字、标点、各类符号等情况,简单题也包含了汉字等。



★因为文件内容过多,仅截取这几幅图,能够说明情况即可。
 ▲可以看到源文件(由几十byte变为几MB),压缩时间和解压缩时间分别为3.4和2.1秒。
▲可以看到源文件(由几十byte变为几MB),压缩时间和解压缩时间分别为3.4和2.1秒。
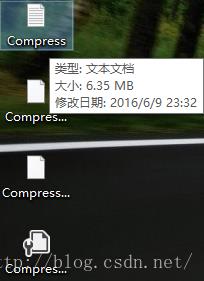 ▲同样能看到生成的压缩文件、解压文件、配置文件,剩下的任务就是核对源文件和解压文件的内容是否一致。
▲同样能看到生成的压缩文件、解压文件、配置文件,剩下的任务就是核对源文件和解压文件的内容是否一致。
★关于源文件和解压文件的比较,首先可以逐行检测,不过这工作量确实有点大;其次可以在源文件中随意挑选几行或十几行,然后到解压文件的对应处进行比对,一般说来,一般解压出错的话,在某一行的某处一旦出错,后续的内容都会出错或者有乱码的情况,所以这样检测也不是为一种方法;最后可以利用相应的文本比较软件,这里推荐使用Beyond Compaer3软件,使用既方便,功能又强大。


★经测试TXT类型以及RTF类型的文件都已成功压缩和解压缩,至于影音文件感兴趣的朋友可以自主尝试下。。
★注:这样此小项目就结束了,而代码依然有能够优化的地方,比如说建堆时考虑优先队列的方式,回溯左右孩子的根节点计算权值时,根节点的权值实际上就等于左右子树的节点权值和,这样的话速度可以提升不少。当然还有其他的地方,网站上下载的那些压缩工具,其中加入了其他的算法,压缩时可以极大地降低空间,比如一个几个G的文件,压缩后只有1,2个G大小,所以说这个小项目只是一个雏形,当然再好的工具,其底层的实现都是基于这个原理的,只要懂得了原理,至于加入什么算法,怎么优化以提高性能,就只是一步步去琢磨,坦白来说这些都不是问题了.....
以上是关于Huffman编码之文件的解/压缩的主要内容,如果未能解决你的问题,请参考以下文章