论文导读Causal Machine Learning:A Survey and Open Problems
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文导读Causal Machine Learning:A Survey and Open Problems相关的知识,希望对你有一定的参考价值。
最新的arXiv上的综述 迅速过一遍
2022.7.13
【历史】C1已看完(三页)
ML面临挑战:
(1)当数据分布发生变化时,泛化性能大幅下降
(2)缺乏对生成模型样本的精细控制
(3)有偏见的预测加强了对某些子群体的不公平歧视
(4)过度抽象和与问题无关的可解释性概念
(5)强化学习方法对现实世界问题的不稳定转化
本文逻辑:
1. 我们对完全独立的因果关系中的关键概念进行了最低限度的介绍(第 2 章)。我们不假设任何因果关系的先验知识。在整个过程中,我们给出了如何应用这些概念来帮助进一步理解直觉的例子。
2. 我们将现有的 CausalML 工作分类为因果监督学习(第 3 章)、因果生成建模(第 4 章)、因果解释(第 5 章)、因果公平性(第 6 章)、因果强化学习(第 7 章)。对于每个问题类别,我们比较现有方法并解决未来工作的途径。
3. 我们回顾了计算机视觉、自然语言处理和图形表示学习(第 8 章)和因果基准(第 9 章)中特定于模态的应用。
4. 我们讨论好的、坏的和丑陋的:我们对 CausalML 与非因果 ML 方法(好的)相比可能给我们带来什么好处的看法,人们必须为这些方法(坏的)付出什么代价,以及什么我们警告从业者不要(丑陋的)风险(第 10 章)。
【目标】看完C2
【笔记】:
C2主要讲的是基础的因果分析的一些知识点
2.1 贝叶斯网络
1.基础概念:
有向无环图、路径、有向路径、parent、child、descent、ancestors、圈、有向圈
2.“用图表示联合分布的分解”
这个角度对因果图、或者说贝叶斯网络总结的很好,通常来说,当我们想要研究一个联合分布的时候,我们能利用的工具是chain rule,如作者引用Pearl教授的例子: 
这个分解中需要研究每个变量和其余N-1个的关系,因此随着变量数量的增多 很快就intractable了
但是,如果我们已知这样的因果图:
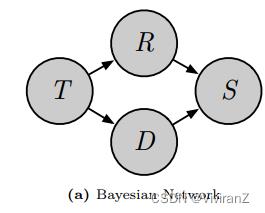
 那么,原本复杂的chain rule就能很轻松变为
那么,原本复杂的chain rule就能很轻松变为
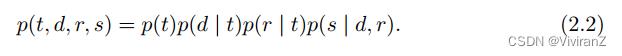
原文对于贝叶斯网络的总结为:
 2.2 因果贝叶斯网络
2.2 因果贝叶斯网络
【intervention】介入
因果贝叶斯相比原始贝叶斯:用invention代替单纯的conditional possibility:
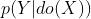 代替
代替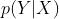

也就是说我们只care把X set为x时候的输出Y的概率。如考虑洒水车X对地面滑倒Y的影响,P(Y|X)会受到季节的影响(夏天热可能洒水车出门的概率会增高),但是P(Y|do(X))是直接设置X,因此季节等(X的父节点)不会对这个do-calculus造成影响。

这只是第一步简化,在Thm2.1.1的基础上把确定为0的部分概率去掉。
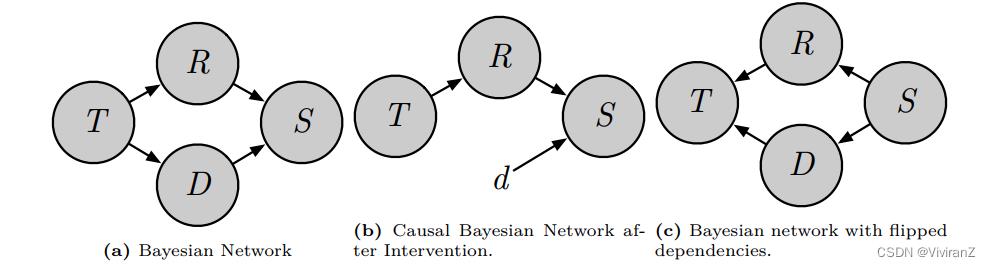
但是,只有条件独立性可能会得出完全相反的因果图,如上图(a)为真实因果关系,(c)与(a)表示的因果关系完全相反、但是他们可以产生相同的独立性关系
【一个例子】
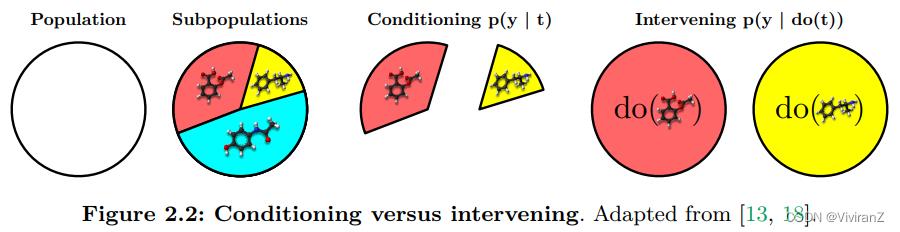
医疗 [18]:想象一个数据集,其中每个观察 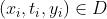 代表医院患者的病史记录
代表医院患者的病史记录 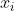 、分子图形式的处方药物治疗
、分子图形式的处方药物治疗 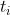 和健康结果
和健康结果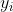 。 图 2.2 说明了在此设置中,干预
。 图 2.2 说明了在此设置中,干预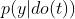 是如何指的是所有具有病史特征 x 的患者都接受治疗 t 的情况,而条件分布
是如何指的是所有具有病史特征 x 的患者都接受治疗 t 的情况,而条件分布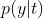 将我们的注意力限制在 收到 t 的 X 的子群体。
将我们的注意力限制在 收到 t 的 X 的子群体。
【counterfactual】反事实推理:
有个人在洒水车经过的时候啪嚓摔断了胳膊,经理问可怜的程序猿:如果没有洒水车,这个人还是摔倒的概率有多大?
那么就是说其他情况不变的时候,只改变洒水车对结果的影响。因为这件事不是真实存在的,我们称为——反事实推理 
在已知结果的基础上进行反事实推理:
p(x | o, do(b 0 )) 与 p(xb 0 | x, o, b) 有何不同? 如果我们从前一个分布中采样图像,根据它的方差,我们可能会得到一组非常多样化的图像,它们分别具有对象和背景特征 o、b。 如果我们从后者中采样,我们期望采样的图像除了背景之外看起来相同。
【我们应该利用后者的方法进行采样】
因果之梯:
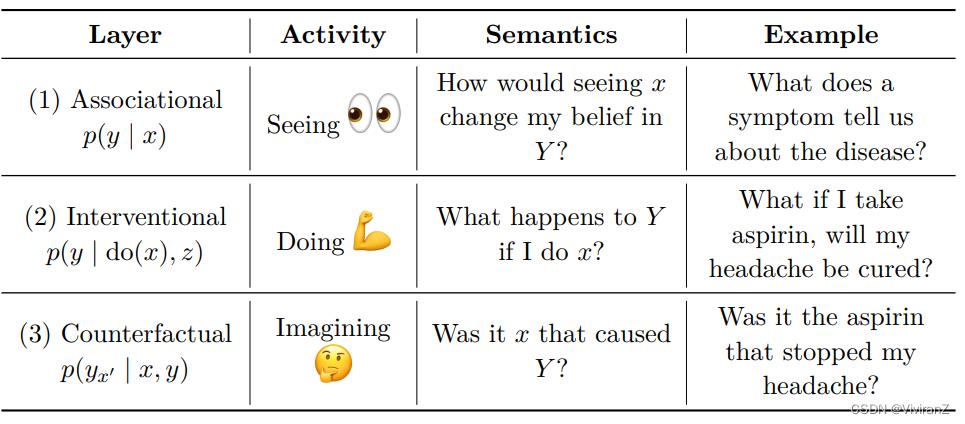 2.3结构化因果模型(SCM)
2.3结构化因果模型(SCM)
Structural Causal Models
causal BN 不足够用来结构化表达反事实推理,因此还要引入新的工具——SCM

在SCM中,嵌入了DAG,并且马尔可夫性质合理嵌入
论文中强调,反事实和干预主要是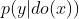 和
和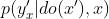 的区别
的区别

反事实推断的步骤:归因-行动-预测


2.4因果表示学习(Causal Representation Learning)
表示学习的目标是检索总结我们的高维数据 X 的低维表示 Z,其中 dim(Z)<< dim(X)。 然后,学习的表示有助于解决下游任务,因为感兴趣的特征(例如,图像中的对象)通常不会在粒度输入数据(例如,像素)中明确给出。 然而,这些表示通常依赖于虚假的关联并产生难以解释的纠缠维度 [21、22、23]
【表示学习是信息压缩,尽量用低维度表示高维的信息、甚至是高维蕴含而不是每一维具体的信息】
相比之下,因果表示学习 (CRL) 假设 SCM 在高级因果变量上生成数据 X。 Z 对应于这些典型的潜在因果变量的实例。 通过访问 SCM,我们可以估计干预这些变量后的数据分布,或推断特定数据点的反事实。 ML 研究的两个领域受益于这些:分布外预测 (OOD, out-of-distribution (OOD) prediction)和可控生成(controllable generation)。 在前者中,我们将新的和不可见的领域视为由与我们的训练数据相同的 SCM 管理的干预分布生成。 在后者中,我们将样本视为从干预或反事实分布中生成的.
2.5 confounders & spurious relationship
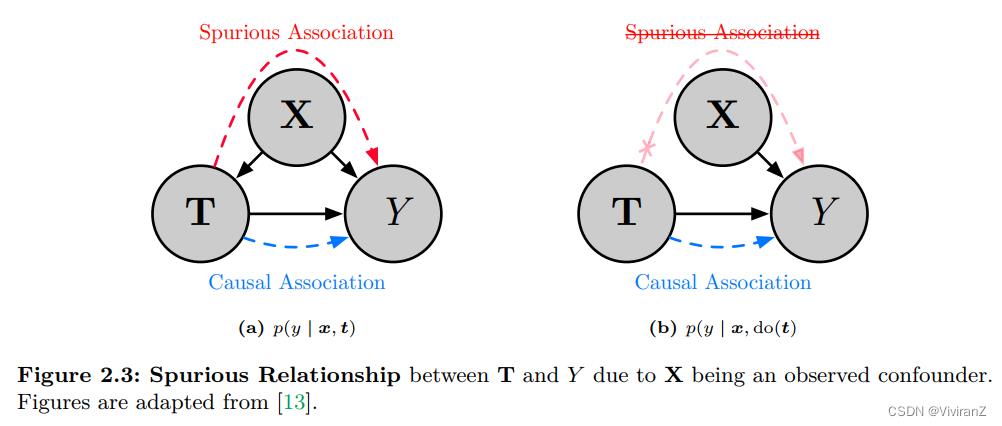
熟悉的block(maybe with d-seperate)

identifiable:所有不同的因果模型,如果因果图一样、表达的所有变量的概率也一样,那么这两个模型中条件概率是一样的。
KEY:两个一样保证uniqueness,也就是说identifiable保证可以从被动观察(概率分布一样)和因果图分析(因果图一样)两个角度分析都是不变的。



总而言之,spurious relationship会导致不本质的因果性关系,如selection bias,在考虑识别狗的时候错误依赖于草坪的因素,会导致实际应用中表现很差(实际上狗不一定在草坪)
2.6 Causal Estimand Identification
因果统计量识别
到目前为止,我们讨论了观察分布和干预分布之间的语义差异以及计算后者的原因。估计后者何时真正可行?因果估计量的识别是指从因果估计量(例如,p (y | do (x)))移动到等效的统计估计量(例如,p (y | x))的过程,然后我们可以根据数据进行估计[13]。
如果可以从纯统计量计算它,我们称它为可识别的因果估计。如果无法识别,那么无论我们拥有多少数据,我们都无法隔离数据中感兴趣的因果关联。
在没有隐藏的混杂因素的情况下,只要我们知道因果图,因果估计是可识别的。例如,假设我们感兴趣的估计是图 2.3a 场景中的平均治疗效果 p(y | do(t)),即治疗的因果效应 t 对所有可能的患者特征 X 进行平均。这里,满足后门标准,这使得 X 成为有效的调整集 [12]。输出统计估计的数学过程也称为后门调整。
一般来说,给定任何因果 DAG(可能包括未观察到的混杂因素),存在图形测试,使我们能够确定特定因果估计的可识别性。除了后门准则,还有一个前门准则。我们在这里不涵盖这些标准,因为就本次调查而言,了解它们的存在就足够了。我们将有兴趣了解更多关于它们的读者引导到 [7, 12, 13, 14] 中的出色解释。
2.7 Causal Influence
除了介入和反事实查询之外,因果推理中另一个常见的兴趣量是一个变量对另一个变量的因果影响。 例如,在第 5 章中,给定一个输入向量 x 和一个带有参数 θ 的黑盒 ML 模型 fθ(·),我们将研究量化输入特征 xi 对模型预测的因果影响 y^ = fθ(x) . 另一个例子将出现在第 7.7 节,我们在多智能体系统中测量智能体的社会影响,例如,一个智能体采取的行动如何影响另一个智能体的后续行动。 Janzing 等人 [26] 假设了一组自然的、直观的要求,因果影响的衡量标准应该满足这些要求。 然后,他们评估各种信息论措施是否满足这些需求。 他们的结论是KL散度是一个合适的度量
7.14 23:13
终于看完了……回顾知识点完成
以上是关于论文导读Causal Machine Learning:A Survey and Open Problems的主要内容,如果未能解决你的问题,请参考以下文章