hive之编译源码
Posted 运维Linux和python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive之编译源码相关的知识,希望对你有一定的参考价值。
序言
使用maven来进行源码,真的是靠运气,特别是你网络很差的情况下,再特别是你没有本地库的时候,靠运气吃饭。。。
本来不想编译的,奈何在hive中执行show create table table_name的时候显示为乱码。。。当一切都很顺利的时候,就能很简单的解决一个问题,当一切不顺利的时候,就感觉很难了,耗费的就是时间。。。是一个耐心加坚持的过程,就看你在什么时候放弃。。。
hive源码编译
1 问题现象
在创建数据仓库的时候,总是要写上各种注释,这样才好去追寻血缘关系,这样好知道每个数据库干啥的,每个表干啥的,每个任务干啥的,这样才能把数据作为资产进行管理,所谓的让数据用起来,让数据动起来。
使用hive1.2.2,使用hadoop2.7.2,使用jdk1.8.0.

2 配置基本环境
由于是在linux上进行编译,重新要进行依赖库的安装:
yum install -y openssl openssl-devel svn ncurses-devel zlib-devel libtool
yum install -y snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop autoconf automake
yum -y install glibc-headers gcc-c++ make cmake openssl-devel ncurses-devel
安装protobuf:
cd /opt/module/protobuf-2.5.0/
./configure
make
make check
make install
ldconfig
进行验证:
[root@KEL1 software]# protoc --version
libprotoc 2.5.0
2 使用maven进行编译
在使用linux的时候,进行依赖的安装就是一件痛苦的事,有了yum之后生活幸福感大大提高,要是手动去安装依赖,并且追查依赖关系。。。真是浪费人生时光。
在使用maven的时候,你会发现这玩意儿也是为了解决依赖关系,也是。。。相当痛苦的过程,尤其是不熟悉的时候。
先替换仓库地址,毕竟墙外面的花儿香,但是不能越鱼池一步:
//下载的依赖jar包都爱此目录之下
[root@KEL1 repository]# pwd
/root/.m2/repository
//使用yum进行安装的maven配置文件目录
[root@KEL1 repository]# ls -l /etc/maven/settings.xml
-rw-r--r-- 1 root root 10476 Feb 25 01:47 /etc/maven/settings.xml
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://maven.aliyun.com/nexus/content/groups/pulic</url>
</mirror>
3 修改代码进行编译
修改显示的代码,使用UTF-8编码:
//文件存在路径
[root@KEL1 exec]# pwd
/root/jdbcjar/apache-hive-1.2.2-src/ql/src/java/org/apache/hadoop/hive/ql/exec
//文件名称
[root@KEL1 exec]# vim DDLTask.java
//将1925行的代码改成如下形式,注意方法名称是write,你要是只改了后面编译不过
outStream.write(createTab_stmt.toString().getBytes("UTF-8"));
//将2110行的代码改成如下形式
outStream.write(createTab_stmt.render().getBytes("UTF-8"));
进行编译:
//进入解压的源码目录,执行编译打包命令
[root@KEL1 apache-hive-1.2.2-src]# pwd
/root/jdbcjar/apache-hive-1.2.2-src
[root@KEL1 apache-hive-1.2.2-src]# mvn clean package -DskipTests -Phadoop-2 -Pdist
接下来就是靠运气了,运气好,一个小时结束,运气不好,三天。。。
[root@KEL1 apache-hive-1.2.2-src]# find ./* -name "*.jar"|grep exec
./ql/target/hive-exec-1.2.2-tests.jar
./ql/target/hive-exec-1.2.2-core.jar
./ql/target/original-hive-exec-1.2.2.jar
./ql/target/hive-exec-1.2.2.jar
//找到对应的hive-exec-1.2.2.jar,替换掉hive里面的jar包
4 验证
创建一个表,用中文注释即可:
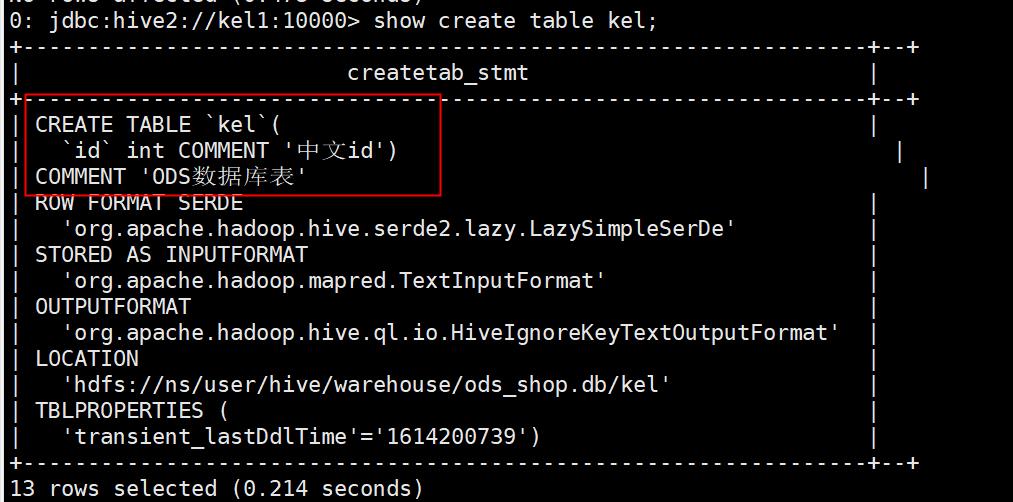
5 可能出现的问题
在进行编译的时候,可能出现内存不足OOM,需要进行设定jvm参数:
//报错内存不足导致OOM
The system is out of resources.
Consult the following stack trace for details.
java.lang.OutOfMemoryError: Java heap space
at com.sun.tools.javac.util.Name.append(Name.java:88)
at com.sun.tools.javac.code.Symbol$TypeSymbol.formFullName(Symbol.java:687)
at com.sun.tools.javac.code.Symbol$ClassSymbol.<init>(Symbol.java:950)
at com.sun.tools.javac.code.Symbol$ClassSymbol.<init>(Symbol.java:958)
at com.sun.tools.javac.jvm.ClassReader.defineClass(ClassReader.java:2358)
at com.sun.tools.javac.jvm.ClassReader.enterClass(ClassReader.java:2372)
at com.sun.tools.javac.jvm.ClassReader.includeClassFile(ClassReader.java:2686)
at com.sun.tools.javac.jvm.ClassReader.fillIn(ClassReader.java:2831)
at com.sun.tools.javac.jvm.ClassReader.fillIn(ClassReader.java:2749)
//设定JVM参数
//export MAVEN_OPTS='-Xms256m -Xmx1024m
如果出现编译失败,不要担心,直接再次运行编译命令即可,会在原来的基础上继续进行编译,找那些不存在的symbol。
具体报错内容如下:
466,33] cannot find symbol
[ERROR] symbol: class RangeInputSplit
[ERROR] location: class org.apache.hadoop.hive.accumulo.mr.HiveAccumuloTableInputFormat
[ERROR] /root/jdbcjar/apache-hive-1.2.2-src/accumulo-handler/src/java/org/apache/hadoop/hive/accumulo/mr/HiveAccumuloTableInputFormat.java:[519,31] cannot find symbol
[ERROR] symbol: class RangeInputSplit
[ERROR] location: class org.apache.hadoop.hive.accumulo.mr.HiveAccumuloTableInputFormat
[ERROR] /root/jdbcjar/apache-hive-1.2.2-src/accumulo-handler/src/java/org/apache/hadoop/hive/accumulo/predicate/AccumuloPredicateHandler.java:[85,29] cannot find symbol
[ERROR] symbol: class Range
[ERROR] location: class org.apache.hadoop.hive.accumulo.predicate.AccumuloPredicateHandler
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :hive-accumulo-handler
偶尔也会出现如下的错误:
error in opening zip file
//不用管,再次执行编译命令即可,可能是网络问题导致下载的jar包有问题
在查看依赖的时候,发现很美好,但是编译又靠网络了。。。
//查看依赖情况
mvn dependency:tree -X

爱意随风起,风止爱难平,黄昏与落日,晚风也想你。。。
成功的路千篇一律,失败的路各种各样诡异的问题。。。。好看的人千篇一律,其他的就不知道了。。。一个问题的特殊性太高,或者使用的场景太少,带来的结果就是投入付出比例不均衡,但是这个又说明了你到底是放弃还是坚持,如果放弃,会不会在心里念念不忘。。。也是一个权衡。
规模化才有更大的机会,就像批量脚本一样。
但是有的时候,特殊的问题就像特殊的机会一样,没准你把握住了,也能成就一段人生。。。是矛盾也是一种妥协。
以上是关于hive之编译源码的主要内容,如果未能解决你的问题,请参考以下文章