Spark SQL 自适应执行优化引擎
Posted DataFlow范式
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL 自适应执行优化引擎相关的知识,希望对你有一定的参考价值。

在本篇文章中,笔者将给大家带来 Spark SQL 中关于自适应执行引擎(Spark Adaptive Execution)的内容。
在之前的文章中,笔者介绍过 Flink SQL,目前 Flink 社区在积极地更新迭代 Flink SQL 功能和优化性能,尤其 Flink 1.10.0 版本的发布,在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。但是在 SQL 功能完整性和生产环境的实践应用等方面,Spark SQL 还是更胜一筹,至于 SQL 批处理方面性能优劣,则需要笔者亲自去实践。
不过,在超大规模集群和海量数据集上,Spark SQL 目前仍然在稳定性和性能方面遇到一些挑战。为了应对这些挑战,Spark 社区进行了改进并引入了自适应执行引擎,它可以在运行时动态地处理任务并行度、join 策略优化和数据倾斜,确保使用运行时统计信息选择最佳执行计划。笔者参考 Haifeng Chen 分享的主题《 Spark Adaptive Execution Unleash the Power of Spark SQL 》,再结合实际情况进行梳理。
挑战
我们首先来看一下,Spark SQL 在实际生产案例中遇到的一些挑战。
挑战 1:并行度问题
在日常的 Spark SQL 开发中,我们通过设置 spark.sql.shuffle.partitions 参数来调整 partition 数量,默认值是200。即 Shuffle partition 数量需要手动调整才可以获得相对理想的性能。

虽然我们可以设置 shuffle partition 数量,但是无法给出一个对所有任务来说都是最优的值,因为每个 task 处理的的数据量以及 shuffle 策略也可能不同。
Shuffle partition 太大或太小都会带来问题:
partition 数量太大
可能会需要处理大量小的 task,导致增加 task 调度开销以及资源调度开销。另外,如果该 Stage 最后要输出存储,造成很多小的 IO 操作,还会造成在 HDFS 上存储大量的小文件。
partition 数量太小
可能会导致每个 task 处理大量的数据,处理效率低下,无法有效利用集群资源的并行处理能力,甚至导致 OOM 的问题。
目前 shuffle partition 数量无法根据每个任务动态调整,只能针对不同的任务进行多次的优化调整,才能得到较为合理的值,但是往往作业的数据量是逐日累增的,所以之前优化的值可能不再适合后续的作业。
因此理想情况下,为了获取最佳的性能,Spark 能够实现在作业执行过程中根据数据量大小动态设置合适的 shuffle partition 数量。
总结一下并行度问题带来的挑战:
数据规模是动态变化的,很难准确评估
单一的 partition 配置不可能适合所有的 partition 以获得最佳性能
挑战 2:Join 策略选择问题
针对不同数据量大小的场景,Spark 支持三种 join 策略以获取最佳的性能:
Sort Merge Join
Shuffle Hash Join
Broadcast Hash Join

既然 Spark 有三种 join 策略,那么实际会带来哪些挑战:
join 策略的选择是基于静态信息的,比如执行计划阶段的表大小
对于复杂查询,中间操作的结果集数据大小变化频繁,很难评估

因此,很多时候,运行的作业可能没有选择最有效的 join 执行策略。
挑战 3:数据倾斜
数据倾斜是指某一个 partition 的数据量远远大于其它 partition 的数据,导致该任务的运行时间远远大于其它任务,因此导致整个 SQL 的运行效率变差。

我们使用的 MapReduce、Spark 和 Flink 都会存在数据倾斜的问题,而且在实际需求开发中(比如使用 join 和 group by 操作),数据倾斜问题也是出现频率比较高的,大部分作业卡在 99% 进度的罪魁祸首。

数据倾斜引起的原因很多,比如:
源表本身就有倾斜的数据
中间操作(比如 outer join)可能生成倾斜数据
简单总结一下产生数据倾斜的问题:
通常无法提前预测
作业运行过程被单个 task 拖垮
可能引起 OOM
在 Spark SQL 实践中,处理数据倾斜的常见手段有:
1. 增加 shuffle partition 数量
通过调整 shuffle partition 数量来避免某个 partition 数据量特别大,将该 partition 数据分散到多个 partition 中。
2. 加盐处理倾斜的 key
增加 shuffle partition 数量的方法,对于同一个海量数据倾斜的 key 来说,不起作用。不过,我们可以对该数据倾斜的 key 通过加盐方式来打散数据,然后再借助 shuffle partition 的功能。
3. 使用 Broadcast Hash Join
在某些场景下,可以把 Sort Merge Join 转化成 Broadcast Hash Join,从而避免 shuffle 产生的数据倾斜。比如,如果两个 join 的表中有一个表是小表,可以优化成Broadcast Hash Join 来消除 shuffle 引起的数据倾斜问题。
但是上面这些解决方案都是针对单一任务进行调优,没有一个解决方案可以有效的解决所有的数据倾斜问题。
Spark Adaptive Execution
Spark SQL Execution 介绍

笔者简单说一下,SQL 语句首先通过 Parser 模块被解析为语法树,称为 Unresolved Logical Plan,接着 Unresolved Logical Plan 通过 Analyzer 模块借助于 Catalog 中的表信息解析为 Logical Plan,然后 Optimizer 再通过各种优化策略进行深入优化,得到 Optimized Logical Plan,Planner 模块再将优化后的逻辑计划根据预先设定的映射逻辑转换为 Physical Plan,最后物理执行计划做 RDD 计算,提交 Spark 集群运算,最终向用户返回数据。
Adaptive Execution 想法
基于社区的工作,Intel 大数据技术团队创建了 Adaptive Execution 项目,对 Adaptive Execution 做了重新的设计,实现了一个更为灵活的自适性执行框架,来解决主要的性能问题。
Adaptive Execution 项目的想法是:

当一个 stage 的 map 任务在 runtime 完成时,我们利用 map 输出大小信息,对并行度、join 策略和倾斜处理进行相应的调整。
Adaptive Execution 框架

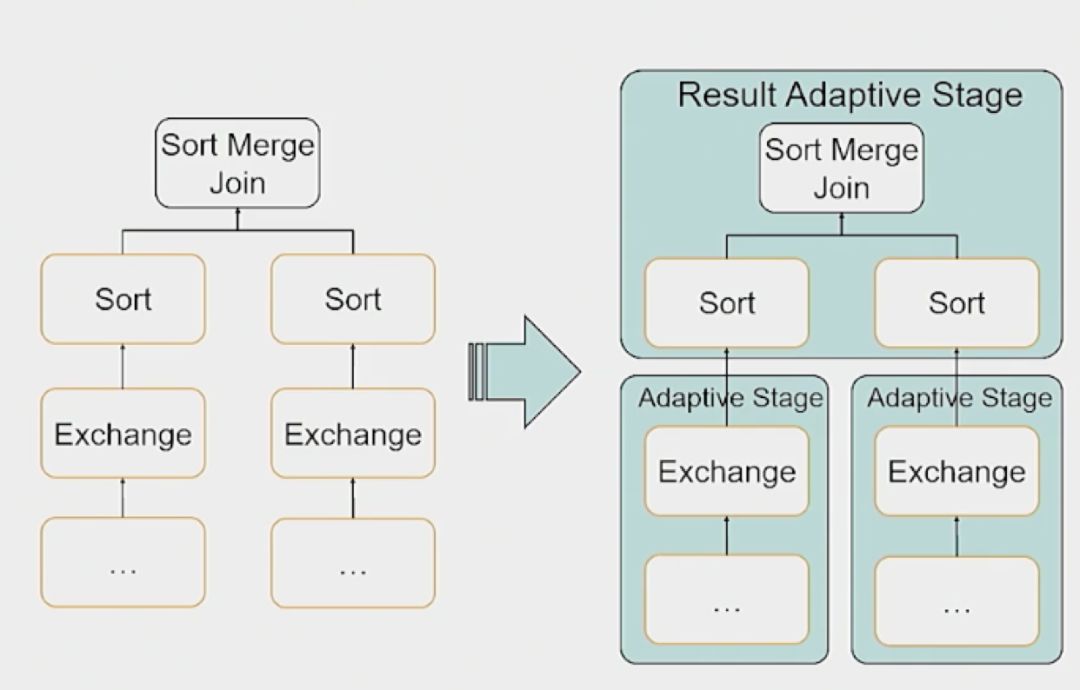
当一个 Adaptive Stage 执行时,它会急切地执行它所有的子 Adaptive Stage
当所有的子 Adaptive Stage 执行完成后,它将拥有所有的 map 输出大小,用于优化决策。
并行度优化
通过使用 map 输出大小的信息,我们可以在运行时对并行度进行调整。

如上图所示,假设我们设置初始 shuffle partition 数量为 8,在 map stage 结束之后,可以看到每一个 Partition(1-8)的大小分别是20M、30M、10M、20M、35M、45M、10M 和 70M。假设设置每一个 reducer 处理的目标数据量(target input size)是 64M,那么在运行时,我们实际使用 4 个 reducer,即第一个 reducer 处理 Partition 1-3,共 60M,第二个 reducer 处理 Partition 4-5,共 55M,第三个 reducer 处理 Partition 6-7,共 55M,第四个 reducer 处理 Partition 8,即 70M。整个作业需要 4 个 task 运行,而不是 8 个 task。
一般情况下,一个 partition 是由一个 task 来处理的。经过优化,我们可以安排一个 task 处理多个 partition,这样,我们就可以保证各个分区相对均衡,不会存在大量数据量很小的 partition。
开启 Adaptive Execution 特性的方式:
spark.sql.adaptive.enabled=true
配置:
spark.sql.adaptive.shuffle.targetPostShuffleInputSize
动态调整 reduce 个数的 partition 大小依据。如设置 64MB,则 reduce 阶段每个 task 最少处理 64MB 的数据。默认值为 64MB。
spark.sql.adaptive.shuffle.targetPostShuffleRowCount
动态调整 reduce 个数的 partition 条数依据。如设置 20000000,则 reduce 阶段每个 task 最少处理 20000000 条的数据。默认值为 20000000。
spark.sql.adaptive.minNumPostShufflePartitions
reduce 个数区间最小值。
spark.sql.adaptive.maxNumPostShufflePartitions
reduce 个数区间最大值。
Join 策略优化

通过使用 map 输出大小的信息,我们可以在运行时对 join 策略进行调整。
在 Shuffle Write 之后,观察两个 Stage 输出的数据量。如果有一个 Stage 数据量明显比较小,可以转换成 Broadcast Hash Join,这样就可以动态的去调整执行计划。

将 Sort Merge Join 转化成 Broadcast Hash Join,此时 join 读取数据是直接从本地读取,没有数据通过网络传输,避开了网络IO的开销,性能会高很多。
开启方式:
spark.sql.adaptive.enabled=true
spark.sql.adaptive.join.enabled=true
配置:
spark.sql.adaptiveBroadcastJoinThreshold
设置了 SortMergeJoin 转 BroadcastJoin 的阈值。如果不设置该参数,该阈值与 spark.sql.autoBroadcastJoinThreshold 的值相等。
是否允许其他的 shuffle
倾斜数据处理
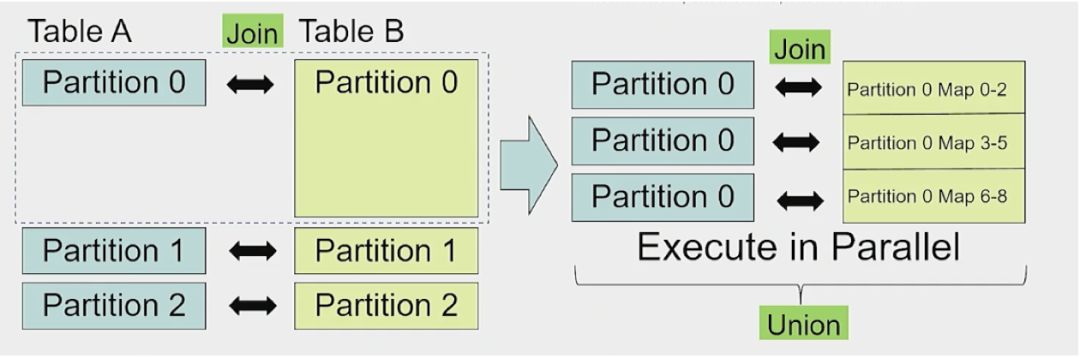
对于大量小数据的 partiiton,可以通过合并来解决问题,即一个 task 处理多个 partition 的数据。
对于数据量特别大的 partition,使用多个 task 来处理该 partition。
开启自动调整数据倾斜功能后,在作业执行过程中,Spark 会自动找出出现倾斜的 partiiton,然后用多个 task 来处理该 partition,之后再将这些 task 的处理结果进行合并。
开启方式:
spark.sql.adaptive.skewedJoin.enabled=true
倾斜处理开关。
spark.sql.adaptive.skewedPartitionMaxSplits
在开启 Adaptive Execution 时,控制处理一个倾斜 partition 的 task 个数上限,默认值为 5。
spark.sql.adaptive.skewedPartitionRowCountThreshold
倾斜的 partition 条数不能小于该值。partition 的条数如果少于这个值,数据量再大也不会被当成是倾斜的partition。默认值为 10000000。
spark.sql.adaptive.skewedPartitionSizeThreshold
倾斜的 partition 大小不能小于该值。默认值为 64MB。
spark.sql.adaptive.skewedPartitionFactor
当一个 partition 的 size 大小大于该值(所有 parititon 大小的中位数)且大于spark.sql.adaptive.skewedPartitionSizeThreshold,或者 parition 的条数大于该值(所有 parititon 条数的中位数)且大于 spark.sql.adaptive.skewedPartitionRowCountThreshold,才会被当做倾斜的 partition 进行相应的处理。默认值为 10。
性能提升
TPC-DS 100TB
大部分查询性能提升 10% ~ 50%,一些查询性能提升超过 50%,甚至达到 200% 以上。另外有一些查询,如果不使用 Adaptive Execution,则无法完成或者失败,而使用 Adaptive Execution 全部通过测试。
Baidu 性能提升分享
50% ~ 200% 性能提升,大部分通过 sort merge join 转变为 broadcast hash join。
Alibaba 性能提升分享
TPC-DS 1TB,总体性能提升 1.38 倍,最大性能达到 3 倍。
国内其他一些公司使用
对于由 outer join 导致的数据严重倾斜的查询,最高可达 10 倍以上的性能提升。
参考
Spark Adaptive Execution Unleash the Power of Spark SQL - Haifeng Chen (Intel)
https://github.com/Intel-bigdata/spark-adaptive
https://issues.apache.org/jira/browse/SPARK-23128

你若喜欢,点个在看哦

以上是关于Spark SQL 自适应执行优化引擎的主要内容,如果未能解决你的问题,请参考以下文章