由 excel 转换为 markdown,及收获
Posted younggift
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由 excel 转换为 markdown,及收获相关的知识,希望对你有一定的参考价值。

1. 问题
构建之法(现代软件工程)东北师大站[http://www.cnblogs.com/younggift/]的每周学生作业成绩,执行教学团队[https://home.cnblogs.com/u/xinz]要求,发布在 cnblogs 上。作业中包括每位同学在作业单项中取得的分数、累加、按比例分配、线性映射等数据,本学期约17次作业成绩或排序统计,产生约70个表格。成绩公布后学生申诉教师修改成绩时,这些表格需要重新计算,再次发布。每次作业申诉数量大约5次左右。

Emacs是我平时的主要工作环境,所以优选熟悉的工具。上学期第一次成绩发布使用了 org-mode 中的表格,发布为html源代码,粘贴到 cnblogs上。成绩累加、变更后的重新计算非常麻烦,org-mode主要是大纲写作工具,不是电子表格。使用的感觉类似于在word的表格中计算。
Excel适合记录、计算、数据变更后再计算,cnblogs使用纯文本、html 或markdown格式。其中 markdown 格式语法简洁,支持大纲式写作和表格,所以适合成绩发布和变更后再次发布。因此,上学期除最初一两次,以及本学期大部分作业成绩发布,先在excel下记录和计算,然后转换为 markdown 格式。
本文回顾我使用的三种方法,由 excel 文件转为 markdown,及收获。
2. 方案1,FFL 的 exceltk.exe
推荐使用此方案。在本学期大多发布中,我都使用了这一工具。没有使用的几次是在等待升级,采用了临时方案。
exceltk 最初是小牛同学拷给我的,说这个非常方便。后来 FLL 老师做过升级,其中对公式的支持、支持移动设备上查看cnblogs上的表头不变形、小数点保留位数这几次升级都很有帮助。
FFL 老师对 exceltk.exe 的介绍在
[http://www.cnblogs.com/math/p/exceltk.html]。
源码:https://github.com/fanfeilong/exceltk
下载:http://files.cnblogs.com/files/math/exceltk0.0.9.7
我的使用方法类似
exceltk.exe -t md -p 2 -xls 构建之法作业成绩debug.xls把excel中的每个 sheet 导出成 markdown,小数点保留两位精度。
3. 方案2,sed
exceltk有一段时间不支持 excel 公式计算结果,我换用了临时方案,等待exceltk升级后切换回来。
3.1 为什么需要公式
我的excel中使用了 vlookup, match 等函数,以方便学生申诉以后的成绩变更。
比如个人作业单项变更,需要因此变更的字段有 个人作业总和、个人作业映射到占本周总成绩20%、本周成绩总和、数周累积、数周累积排序、数周累积去除负分同学排序、数周累积映射到[50,100];再如团队成绩单项变更,需要因此变更的字段有 该团队总分、该团队总分映射到本周总成绩的30%、该团队所有成员的团队成绩、该团队所有成员的本周总成绩、该团队所有成员的数周累积以及排序和映射到[50,100]。诸如此类。由每周作业的单项数目不同,所以公式不宜用固定列的序号,比如"=SUM(B4:L4)",而采用了vlookup & match 函数对字段寻址。
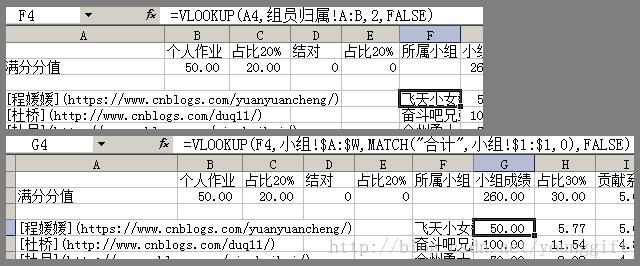
vlookup & match 函数类似这样:
=VLOOKUP(F4,小组!$A:$W,MATCH("合计",小组!$1:$1,0)+1,FALSE)含义是
(1) F4单元格所在列是"所属小组",每行一人,随行变化。此例中的值为
"=VLOOKUP(A4,组员归属!A:B,2,FALSE)",求值结果 "飞天小女警"。
(2) 取"飞天小女警"的"合计。"取 名为"小组"的工作表 中,表头 (第一行)写
作"合计"的那列的数据,要求 A列的值为 F4的那行,即"飞天小女警"。
(3) 总结,姓名 -> 组员归属 -> 小组成绩.
这样,当小组成绩变更以后,该团队所有成员的小组成绩、本周总成绩、数据累积等都会自动变化。我只要修改变更的单项,然后再把excel导出成 markdown发布就行了。不使用公式,每次变更需要顺序修改、复制粘贴若干次,时间长工作量大,每个单项都要消耗30分钟左右,还担心出错。使用公式后成绩变更一次几分钟。
3.2 excel -> csv -> markdown
sed 是 perl 的灵感来源之一,另一个是 awk。它们专门辅助 shell 脚本,awk做计算,sed做文本替换。
我用的临时方案脚本,在这里[https://coding.net/u/younggift/p/xls2md/]。
3.2.1 excel -> csv, vba
我把 excel 导出为 csv 格式,这样完成了公式的计算,也成为了文本格式,sed才能处理。
使用了 stackoverflow 上的 vbs 脚本,稍作修改,按数据表名导出。
----脚本开始
if WScript.Arguments.Count < 2 Then
WScript.Echo "Please specify the source and the destination files. Usage: ExcelToCsv <xls/xlsx source file> <csv destination file>"
Wscript.Quit
End If
csv_format = 6
Set objFSO = CreateObject("Scripting.FileSystemObject")
src_file = objFSO.GetAbsolutePathName(Wscript.Arguments.Item(0))
dest_file = objFSO.GetAbsolutePathName(WScript.Arguments.Item(1))
rem msgbox(dest_file)
Dim oExcel
Set oExcel = CreateObject("Excel.Application")
Dim oBook
Set oBook = oExcel.Workbooks.Open(src_file)
oBook.Worksheets(1).Activate
oBook.SaveAs dest_file+"\\个人", csv_format
oBook.Worksheets(2).Activate
oBook.SaveAs dest_file+"\\结对", csv_format
oBook.Worksheets(3).Activate
oBook.SaveAs dest_file+"\\小组", csv_format
oBook.Worksheets(5).Activate
oBook.SaveAs dest_file+"\\本周", csv_format
oBook.Worksheets(8).Activate
oBook.SaveAs dest_file+"\\数周排序-去除负分", csv_format
oBook.Worksheets(9).Activate
oBook.SaveAs dest_file+"\\数周累积负分", csv_format
oBook.Close False
oExcel.Quit
----脚本结束调用的时候,在bat中,如下。
----bat片段开始
chcp 936
set filename=构建之法作业成绩beta-review.xls
xls2csv.vbs %filename% .
----bat片段结束3.2.2 cvs -> mark down, sed
根据不同数据表的格式不同,我写了不同的 sed 脚本。"应该"把某些 sed 脚本抽象合并到同一个文件中,不过考虑到复用次数不多、可预见的复用增长不大、以及懒,所以就复制粘贴,然后分别修改了。
所以 shell 脚本看起来这样,里面的 c1_head 与 c1, c2_head 与 c2 长得很像,抽象优化强迫症患者可能感觉不好。
----shell脚本片段开始
sed -f c1_head.sed 本周.csv | sed -f c2_head.sed > 本周.md
sed -f c1.sed 数周排序-去除负分.csv | sed -f c2.sed > 数周排序-去除负分.md
----shell脚本片段开始每行分成两个sed执行,用管道连接,重定向到指定名称的md即markdown文件中。分成两个sed执行是必要的,因为 sed 不支持对刚刚粘贴来的行通过引用行号编辑。或者是因为我没有做出足够好的正则表达式 (@典同学,@marverick@柳园bbs) ,考虑sed/正则表达式的处理能力,此处应该不涉及类似括号匹配的上下文无关文法。
3.3 sed解读
3.3.1 测试用例
(1) cvs的前几行
列之间用","分隔。在我的临时sed脚本中,没有处理转义","的情况,解决的方案是在xls中避免使用半角逗号。
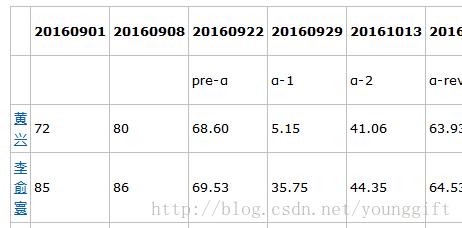
,20160901,20160908,20160922,20160929,20161013,20161020,20161027,20161103,20161110,累积,映射至[100,60],映射至[100,50]
,,,pre-α,α-1,α-2,α-review,β-1,β-2,β-review,,,
[黄兴](http://www.cnblogs.com/huangxman),72.00 ,80.00 ,68.60 ,5.15 ,41.06 ,63.93 ,60.60 ,69.60 ,78.03 ,538.97 ,100.00 ,100.00
[李俞寰](http://www.cnblogs.com/li-yuhuan/),85.00 ,86.00 ,69.53 ,35.75 ,44.35 ,64.53 ,41.20 ,31.20 ,78.63 ,536.19 ,99.79 ,99.73
[张金生](https://www.cnblogs.com/jx8zjs/),93.00 ,94.00 ,72.47 ,-1.00 ,66.06 ,-1.53 ,39.60 ,63.88 ,88.41 ,514.89 ,98.14 ,97.67
[程媛媛](https://www.cnblogs.com/yuanyuancheng/),61.00 ,76.00 ,-7.60 ,13.27 ,41.23 ,94.67 ,69.40 ,75.20 ,86.51 ,509.68 ,97.73 ,97.17 (2) markdown的前几行
形如"|:--|"的文字,用于分隔出表头。
||20160901|20160908|20160922|20160929|20161013|20161020|20161027|20161103|20161110|累积|映射至[100,60]|映射至[100,50]|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|[黄兴](http://www.cnblogs.com/huangxman)|72.00 |80.00 |68.60 |5.15 |41.06 |63.93 |60.60 |69.60 |78.03 |538.97 |100.00 |100.00 |
|[李俞寰](http://www.cnblogs.com/li-yuhuan/)|85.00 |86.00 |69.53 |35.75 |44.35 |64.53 |41.20 |31.20 |78.63 |536.19 |99.79 |99.73 |
|[张金生](https://www.cnblogs.com/jx8zjs/)|93.00 |94.00 |72.47 |-1.00 |66.06 |-1.53 |39.60 |63.88 |88.41 |514.89 |98.14 |97.67 |
|[程媛媛](https://www.cnblogs.com/yuanyuancheng/)|61.00 |76.00 |-7.60 |13.27 |41.23 |94.67 |69.40 |75.20 |86.51 |509.68 |97.73 |97.17 |
|[张政](https://www.cnblogs.com/regretless/)|90.00 |98.00 |71.27 |5.07 |65.48 |-2.73 |20.00 |68.38 |92.91 |508.38 |97.63 |97.04 |3.3.2 把 , 转成 |
# , => |
s/,/|/g;
s/^/|/g;
s/$/|/g;(1) s是substitute.
(2) s / 原来的文字 / 替换成的文字 / 全局
(3) ^表示行首,$表示行尾。
总的效果是,把所有逗号换成竖线,行首行尾各加一条竖线。
3.3.3 表头 |:--|
数据流是这样的 (cvs) -> c1_head -> c2_head -> (md),其中括号里的是产物,没括号的是加工。
在 c1_head.sed 中:
# table head, copy & paste
1h
1G在 c2_head.sed 中:
2s/[^|]//g
2s/|/|:--/g
2s/|:--$/|/g(1) 1h 复制第1行,1G粘贴在当前位置。得到
||20160901|20160908|20160922|20160929|20161013|20161020|20161027|20161103|20161110|累积|映射至[100,60]|映射至[100,50]|
||20160901|20160908|20160922|20160929|20161013|20161020|20161027|20161103|20161110|累积|映射至[100,60]|映射至[100,50]|(2) c2_head.sed中几行的作用,是对只转换第2行,不是对全局影响。
(3) 2s/[^|]//g,除了竖线以外,去除所有字符。
||20160901|20160908|20160922|20160929|20161013|20161020|20161027|20161103|20161110|累积|映射至[100,60]|映射至[100,50]|
||||||||||||||(4) 2s/|/|:--/g,把第2行的所有竖线,转换为 |:--
||20160901|20160908|20160922|20160929|20161013|20161020|20161027|20161103|20161110|累积|映射至[100,60]|映射至[100,50]|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--(5) 2s/|:--$/|/g,把第2行行尾前的 :-- 转换为 竖线。
||20160901|20160908|20160922|20160929|20161013|20161020|20161027|20161103|20161110|累积|映射至[100,60]|映射至[100,50]|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|之所以采用复制粘贴-替换的方法,是因为sed不会计数。
3.3.4 空行 ||||||||||||||
原始 cvs 形如:
---cvs片段开始
姓名,继续迭代,PSP,进度条,代码堆积图,博客字数堆积图,beta发布评论,加分事项,加分分值,合计,占比20%
满分分值,,5,5,5,5,5,,,25,20.00
[程媛媛](https://www.cnblogs.com/yuanyuancheng/),,5,5,5,5,5,,,25,20.00
[杜桥](http://www.cnblogs.com/duq11/),,5,5,5,5,5,,,25,20.00
---cvs片段结束期待修改为形如下面的样子。"||||||||||||||"一行,用于建立空行,目的是造成两行表头的效果。
||个人作业|占比20%|结对|占比20%|所属小组|小组成绩|占比30%|贡献系数(4人分配4*20)|占比30%|特别加分事由|特别加分数值|本周得分|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|满分分值|25.00 |20.00 |10|20||35.00 |30.00 |5*N|30.00 |||100.00 |
||||||||||||||
|[程媛媛](https://www.cnblogs.com/yuanyuancheng/)|25.00 |20.00 |0|0|飞天小女警|37.00 |31.71 |5.80 |34.80 |||86.51 |
|[杜桥](http://www.cnblogs.com/duq11/)|25.00 |20.00 |0|0|奋斗吧兄弟|32.00 |27.43 |5.00 |30.00 |||77.43 |
|[杜月](http://www.cnblogs.com/qianhuihui/)|24.00 |19.20 |0|0|金州勇士|48.00 |41.14 |5.12 |30.72 |||91.06 |
|[宫成荣](http://www.cnblogs.com/gongcr/)|25.00 |20.00 |0|0|新蜂|19.00 |16.29 |6.00 |36.00 |||72.29 |在 c1_head.sed 中:
# table head, copy & paste
1h
1G
# blank line, copy & paste
3G在 c2_head.sed 中:
4d
5s/[^|]//g(1) 在 c1_head中 复制第1行,另粘贴到第3行一份。此时文本文件仍维持原有
的行号,新粘贴的文字不能使用行号引用,因此不能进一步编辑。
||个人作业|占比20%|结对|占比20%|所属小组|小组成绩|占比30%|贡献系数(4人分配4*20)|占比30%|特别加分事由|特别加分数值|本周得分|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|满分分值|25.00 |20.00 |10|20||35.00 |30.00 |5*N|30.00 |||100.00 |
||个人作业|占比20%|结对|占比20%|所属小组|小组成绩|占比30%|贡献系数(4人分配4*20)|占比30%|特别加分事由|特别加分数值|本周得分|
[程媛媛](https://www.cnblogs.com/yuanyuancheng/),,5,5,5,5,5,,,25,20.00
[杜桥](http://www.cnblogs.com/duq11/),,5,5,5,5,5,,,25,20.00 (2) c2_head.sed中的4d,删除第4行空白行 (在c1_head中的第3行) 。
||个人作业|占比20%|结对|占比20%|所属小组|小组成绩|占比30%|贡献系数(4人分配4*20)|占比30%|特别加分事由|特别加分数值|本周得分|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|满分分值|25.00 |20.00 |10|20||35.00 |30.00 |5*N|30.00 |||100.00 |
||个人作业|占比20%|结对|占比20%|所属小组|小组成绩|占比30%|贡献系数(4人分配4*20)|占比30%|特别加分事由|特别加分数值|本周得分|
[程媛媛](https://www.cnblogs.com/yuanyuancheng/),,5,5,5,5,5,,,25,20.00
[杜桥](http://www.cnblogs.com/duq11/),,5,5,5,5,5,,,25,20.00 (3) 5s/[^|]//g,把原第5行 (删除第4行后显示为第4行,仍计数第5行)改为 ||||||||||||||
||个人作业|占比20%|结对|占比20%|所属小组|小组成绩|占比30%|贡献系数(4人分配4*20)|占比30%|特别加分事由|特别加分数值|本周得分|
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|满分分值|25.00 |20.00 |10|20||35.00 |30.00 |5*N|30.00 |||100.00 |
||||||||||||||
|[程媛媛](https://www.cnblogs.com/yuanyuancheng/)|25.00 |20.00 |0|0|飞天小女警|37.00 |31.71 |5.80 |34.80 |||86.51 |
|[杜桥](http://www.cnblogs.com/duq11/)|25.00 |20.00 |0|0|奋斗吧兄弟|32.00 |27.43 |5.00 |30.00 |||77.43 |
|[杜月](http://www.cnblogs.com/qianhuihui/)|24.00 |19.20 |0|0|金州勇士|48.00 |41.14 |5.12 |30.72 |||91.06 |
|[宫成荣](http://www.cnblogs.com/gongcr/)|25.00 |20.00 |0|0|新蜂|19.00 |16.29 |6.00 |36.00 |||72.29 |

Emacs是我平时使用的工具,所以本学期最初的转换,当需要公式,因此由 cvs转成 markdow 还没有被 ffl 支持时,自然地想到用 elisp 作为临时方案。
elisp是上下文无关文法 (或者更强?)的语言,因此可以计数,得以避免使用复制粘贴-修改这样的手段生成表头行。col-count用于存储列的数量。
(defun cvs2md-table ()
"replace cvs format to markdown talbe."
(interactive)
; , -> |
(goto-char (point-min))
(replace-string "," "|")
(goto-char (point-min))
(replace-regexp "^" "|")
(goto-char (point-min))
(replace-regexp "$" "|")
; table head
(setq col-count 0)
(goto-char (point-min))
(setq col-count (count-matches "|" (line-beginning-position) (line-end-position)))
(goto-line 2)
(setq head-count 0)
(while (< head-count col-count)
(insert "|:--")
(setq head-count (1+ head-count))
)
(insert "|")
(open-line 1)
; delete "||" in the last line
(goto-char (point-max))
(beginning-of-line)
(kill-line)
)5. 收获
一个技术方案是否能被别人采用,因此具有更帮助更多的人而不仅是自己,取决于多个方面。比如,emacs这类相对小众之下开发的代码,sed这种需要运行环境和只能命令行操作的脚本,对于很多人不算友好。ffl的工具可以复制粘贴,也支持命令行,基于.net运行环境在当今不再是个问题,友好得多。
语言的能力越强,越接近于图灵机,实现通用功能,比如计数、插入某个特定数量的字符,就越容易。所以在DSL中要小心配置文件容易迅速成长为上下文无关文法,然后图灵等价,成为新的语言,专用特性的优势就消失了。能力弱一些的语言,也不见得不能实现,比如把插入特定数量的字符等价为 (事实上这才是原始的需求)复制粘贴再修改某一行。还是要确定自己的问题到底是什么,计算模型和数学模型的选择,然后才是代码。
要清楚--尽可能第一时间发现--语言或工具的限制,比如sed不为刚插入和文本编排行号,因此不能基于行编辑。

------------------------------------------------------------
博客会手工同步到以下地址:
[http://zhuanlan.zhihu.com/younggift]
[https://younggift.net/]
[http://blog.csdn.net/younggift]
[http://giftdotyoung.blogspot.com]
以上是关于由 excel 转换为 markdown,及收获的主要内容,如果未能解决你的问题,请参考以下文章