Spark算子执行流程详解之二
Posted 亮亮-AC米兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark算子执行流程详解之二相关的知识,希望对你有一定的参考价值。
4.count
| def count(): Long = sc.runJob(this, Utils.getIteratorSize_).sum |
计算数据总量,每个分区各自计算自己的总数,然后汇总到driver端,driver端再把每个分区的总数相加统计出对应rdd的数据量,其流程如下:
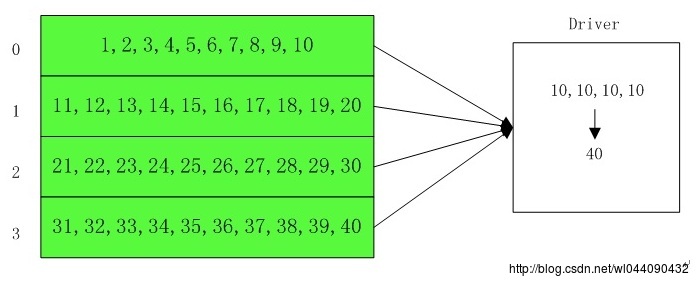
5.countApprox
在一定的超时时间之内返回rdd元素的个数,其rdd元素的总数分布符合正态分布,其分布因子为confidence,当超过timeout时,返回一个未完成的结果。
| /** //定义在excutor端计算总数的函数 //定义在driver端的一个监听回调函数,当task完成的时候,会触发里面的merge操作,当超时时间到之后或者任务提前完成的话,会取里面的当前状态,即currentResult //提交任务 |
继续往下看,看看evaluator是如何执行的:
| def runApproximateJob[T,U, R]( // cleanedFunc就是countElements,evaluator就是CountEvaluator,超时时间为timeout |
继续看runApproximateJob的实现:
| def runApproximateJob[T,U, R]( //定义一个监听器,当有任务完成的时候触发taskSucceeded,当超时时间到的时候返回CountEvaluator的当前值 //提交任务 //等待计算结果 |
因此其超时计算总数的逻辑主要在ApproximateActionListener里面,请看ApproximateActionListener:
| private[spark] classApproximateActionListener[T, U, R]( //当某个分区完成的时候触发taskSucceeded回调函数 //更新CountEvaluator的当前值 //退出等待 //等待计算结果 |
其中如果在超时时间之内没有完成的话,evaluator.currentResult()会返回符合总数符合正态分布的一个近似结果,感兴趣的同学可以继续研究下去:
| private[spark] classCountEvaluator(totalOutputs: Int, confidence: Double) |
因此countApprox的计算过程大致如下:1)excutor端不断的计算分区的总数然后上报给driver端;2)driver端接受excutor上报的总数进行统计,如果在超时时间之内没有全部上报完成的话,则强制退出,返回一个其总数符合正态分布的值,如果在超时时间之内计算完成的话,则返回一个准确值。
6.countApproxDistinct
作用是对RDD集合内容进行去重统计,该统计是一个大约的统计,参数relativeSD控制统计的精确度。relativeSD越小,结果越准确。
| /** |
采用的是HyperLogLog in Practice算法,原理比较深奥,有兴趣的可以深究。
实例如下:
| object CountApproxDistinct def main(args: Array[String]) val conf = new SparkConf().setAppName("spark-demo").setMaster("local") val sc = new SparkContext(conf) /** * 构建一个集合,分成20个partition */ val a = sc.parallelize(1 to 10000 , 20) //RDD a内容复制5遍,其中有50000个元素 val b = a++a++a++a++a //结果是9760,不传参数,默认是0.05 println(b.countApproxDistinct()) //结果是9760 println(b.countApproxDistinct(0.05)) //8224 println(b.countApproxDistinct(0.1)) //10000 println(b.countApproxDistinct(0.001))
|
7.collect
| def collect(): Array[T] = withScope |
获取Rdd的所有数据,然后缓存在Driver端,其流程如下:
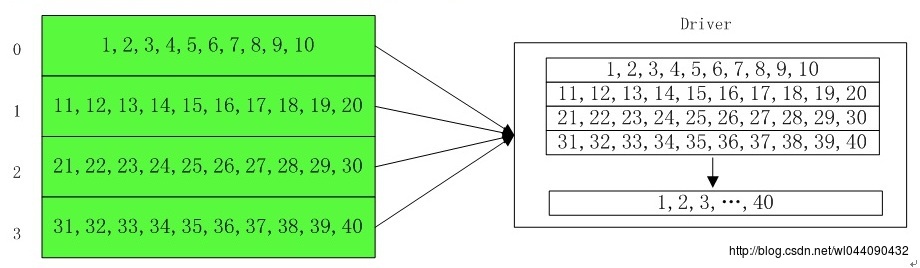
如果RDD数据量很大的话,请谨慎使用,因为会缓存该RDD的所有数据量。
8.toLocalIterator
返回一个保护所有记录的迭代器
| /** //针对每个分区触发一次action //调用flatMap将所有记录组装起来返回单个迭代器 |
即:
| scala> val rdd = sc.parallelize(1 to 10,2) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24 scala> val it = rdd.toLocalIterator it: Iterator[Int] = non-empty iterator scala> while(it.hasNext) | println(it.next) | 1 2 3 4 5 6 7 8 9 10 |
9.takeOrdered
takeOrdered函数用于从RDD中,按照默认(升序)或指定排序规则,返回前num个元素。
| def takeOrdered(num: Int)(implicitord: Ordering[T]): Array[T] = withScope //先在excutor端进行排序,按照ord排序规则,转化为前num个优先队列 //将分区的计算结果传送给driver,转化为数组,进行排序取前num条记录 |
例如:
| List<Integer> data = Arrays.asList(1,4,3,2,5,6); 打印 1 2 |
其执行流程如下:
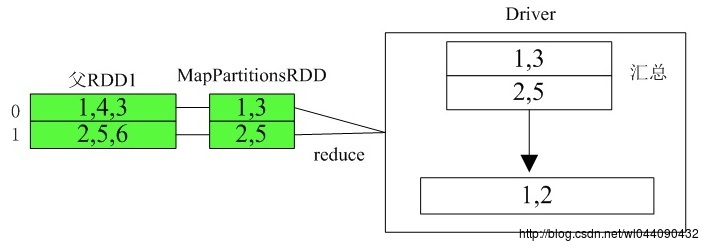
以上是关于Spark算子执行流程详解之二的主要内容,如果未能解决你的问题,请参考以下文章