Kafka的Java客户端-生产者
Posted z啵唧啵唧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka的Java客户端-生产者相关的知识,希望对你有一定的参考价值。
文章目录
Kafka的Java客户端-生产者(常见配置和概念)
Java连接kafka
1.引入kafka依赖
<dependency>
<groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version>
</dependency>
2.生产者发送消息的基本实现
//消息的发送⽅
public class MyProducer
private final static String TOPIC_NAME = "my-replicated-topic"; public static void main(String[] args) throws ExecutionException,
InterruptedException
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093,localhost:9094");
//把发送的key从字符串序列化为字节数组
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//把发送消息value从字符串序列化为字节数组
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<String, String>(props);
Order order = new Order((long) i, i);
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, order.getOrderId().toString(), JSON.toJSONString(order));
//等待消息发送成功的同步阻塞⽅法
RecordMetadata metadata = producer.send(producerRecord).get();
//=====阻塞=======
System.out.println("同步⽅式发送消息结果:" + "topic-" + metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" +
metadata.offset());
3.发送消息到指定的分区
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, 0, order.getOrderId().toString(), JSON.toJSONString(order))
4.未指定分区,则会通过业务key的hash运算,算出消息往那个分区发送
//未指定发送分区,具体发送的分区计算公式:hash(key)%partitionNum ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME
, order.getOrderId().toString(), JSON.toJSONString(order));
消息的同步和异步发送
1.生产者同步发送消息

1.ack应答机制
2.如果生产者发送消息没有收到ack,生产者会阻塞,阻塞到3s的时间,如果还没有收到消息,会进行重试,重试次数为3次.
//等待消息发送成功的同步阻塞⽅法
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("同步⽅式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" +metadata.offset());
2.生产者异步发送消息
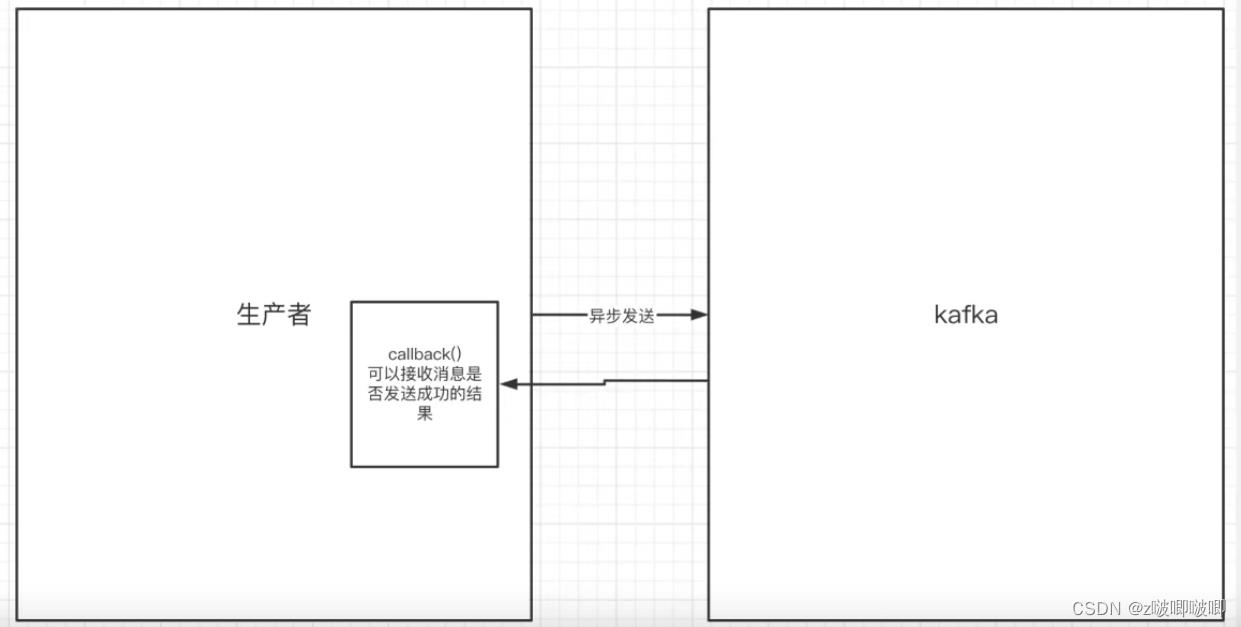
异步发送,生产者发送完消息之后就可以执行相应的业务,broker在收到消息之后异步调用生产者提供的callback回调方法.
//异步回调⽅式发送消息
producer.send(producerRecord, new Callback()
public void onCompletion(RecordMetadata metadata, Exception exception)
if (exception != null)
System.err.println("发送消息失败:" +exception.getStackTrace());
if (metadata != null)
System.out.println("异步⽅式发送消息结果:" + "topic-" +
metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" + metadata.offset());
);
关于生产者ack参数配置
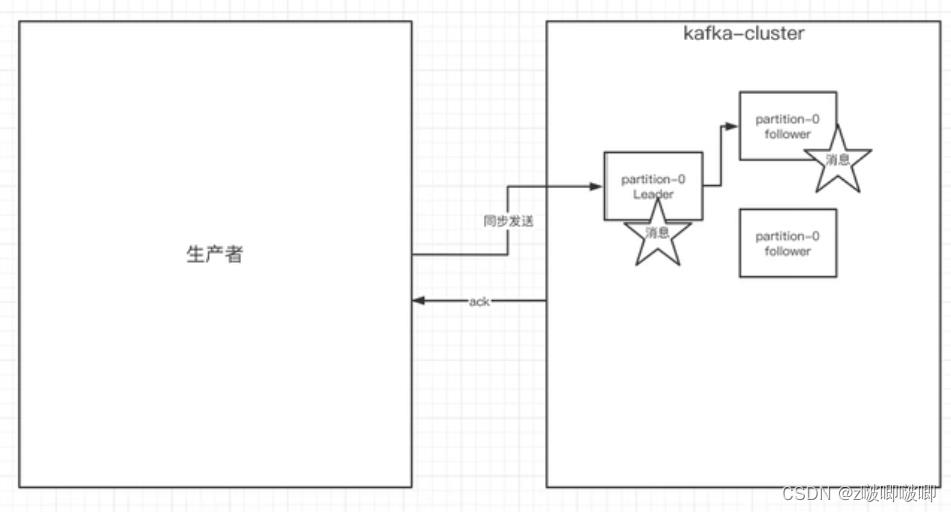
采用同步发送的时候,当生产者发送一条消息必须等待一个ack返回才能进行下一步的执行
对于ack来说会有三个参数配置
- ack = 0 kafka集群不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢失消息,效率是最高的
- ack = 1 多副本之间的leader已经收到消息,并把消息写到本地的log中,才会返回ack给生产者,性能和安全性是最均衡的
- ack = -1/all 里面有一个默认的配置min.insync.replicas=2(默认是1,推荐配置大于等于2) 意思就是不仅需要leader将消息写在本地,而且还要同步到指定个数的副本当中,这个指定个数就为(min.insync.replicas - 1(这个1是leader))这样leader写完,并且同步完毕之后才会返回ack给生产者,当这个配置为1的时候,实际上就是ack = 1这种模式,这中模式是最安全,但是性能最差,
- 下面是关于ack和(如果没有收到ack就开启重试)重试的配置
props.put(ProducerConfig.ACKS_CONFIG, "1");
/*
发送失败会进行重试,默认重试间隔100ms,重试能够把保证消息发送的可靠性,但是因为可能造成消息的重复发送,比如网络抖动,所以需要接收者那边做好消息接收的幂等性处理
*/
props.put.(ProducerConfig.RETRIES_CONFIG, 3);
//间隔设置
props.put(ProducerConfig.RETRY_BACKOFF_MSCONFIG, 300);
发送消息的缓冲区设置

- 无论是同步发送还是异步发送,是有一条就发送一条嘛?加入生产者这边有10万条消息要进行发送,那么我们要和kafka建立10万次会话嘛?显然是不可能的.
- 所以这时候就会存在一个32M的缓冲区,消息会存放在缓冲区当中,这个不是说要等消息将这个32M的缓冲区填满才发送,而是存在一个本地线程会从这个缓冲区当中拉数据,一次拉满16k的数据,拿到16k的数据之后往kafka当中进行发送.当然这个缓冲区大小和本地线程拉满的大小都是可以进行配置的
//缓冲区大小配置
props.put(ProducerConfig.BUFFER_MEMORY, 33554432);
//本地线程一次拉取的数据大小的配置
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384)
- 但是线程存在一个问题就是假如只存在一条消息,不够16k的大小,那么这个时候这个本地线程会不会发送这个消息呢? 这时候有一个机制就是当数据的大小不够16k,那么隔10ms后会发送数据,当然这个10ms也是可以配置的
//配置本地线程拉取数据发送最大的等待时间
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
以上是关于Kafka的Java客户端-生产者的主要内容,如果未能解决你的问题,请参考以下文章