hadoop:HA场景下 java客户端远程访问hdfs配置
Posted 花和尚也有春天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop:HA场景下 java客户端远程访问hdfs配置相关的知识,希望对你有一定的参考价值。
当hadoop namenode是HA集群时,客户端远程访问hdfs有两种实现方法:
方法1:将所有关于namenode的参数写入Configuration对象中。
代码:
package com.lx;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class Demo
private static void uploadToHdfs() throws Exception
//本地文件地址
String localSrc = "d:/PowerDesigner15_Evaluation.rar";
//存放在hdfs的目的地址
String dest = "/user/PowerDesigner15_Evaluation.rar";
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
//得到配置对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ns1");
conf.set("dfs.nameservices", "ns1");
conf.set("dfs.ha.namenodes.ns1", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.ns1.nn1", "hadoop1:9000");
conf.set("dfs.namenode.rpc-address.ns1.nn2", "hadoop2:9000");
conf.set("dfs.client.failover.proxy.provider.ns1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
//文件系统
FileSystem fs = FileSystem.get(new URI("hdfs://ns1"), conf, "hadoop");
//输出流
OutputStream out = fs.create(new Path(dest));
//连接两个流,形成通道,使输入流向输出流传输数据
IOUtils.copyBytes(in, out, 4096, true);
public static void main(String[] args) throws Exception
// TODO Auto-generated method stub
uploadToHdfs();
方法2:将hadoop集群配置文件core-site.xml和hdfs-site.xml文件拷贝到项目的src目录下。 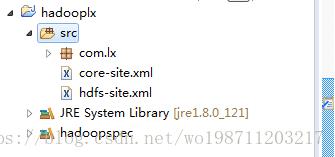
代码:
package com.lx;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class Demo2
public static void main(String[] args) throws Exception
// TODO Auto-generated method stub
String src="d:/RoseHA.rar";
String dst="/user/RoseHA.rar";
InputStream in=new BufferedInputStream(new FileInputStream(src));
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(new URI("hdfs://ns1"), conf, "hadoop");
OutputStream out=fs.create(new Path(dst));
IOUtils.copyBytes(in, out, 4096, true);
参考以上方式一:
springboot继承hdfs成功,集群+HA 我的具体配置为:
https://blog.csdn.net/weixin_38750084/article/details/107630955
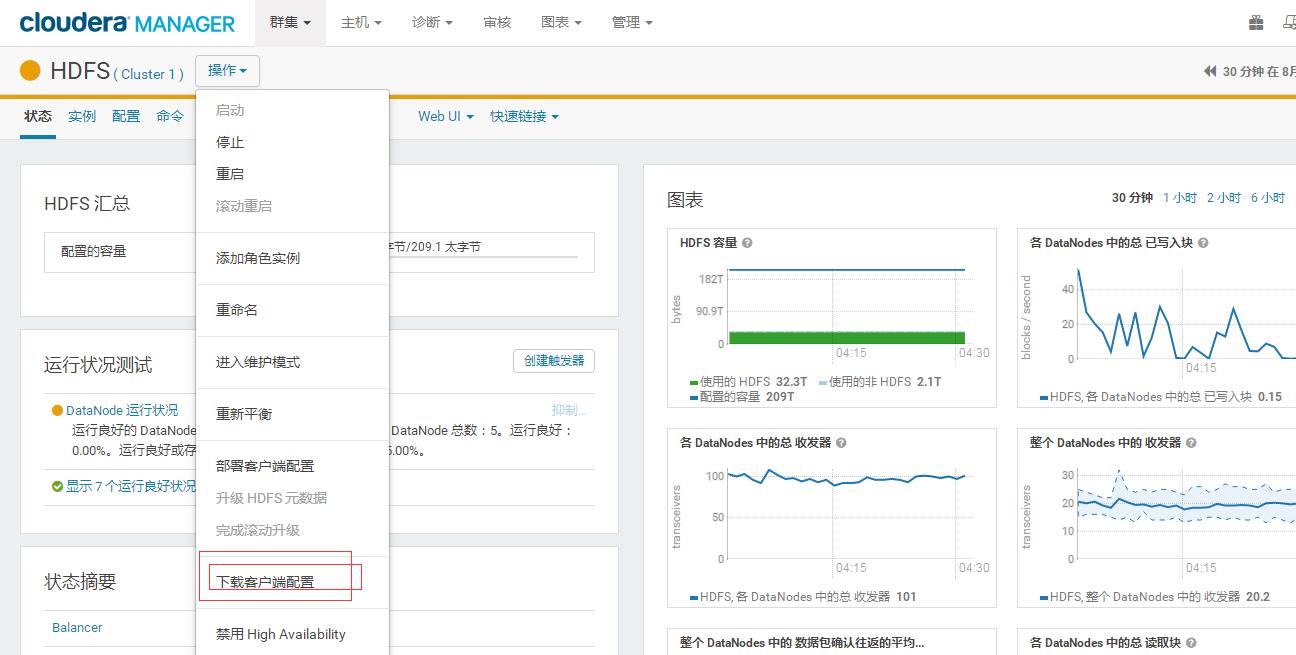
如果使用方式二,那些需要配置的属性在hdfs-site.xml和core-site.xml中都可以找到,以下是cdh下载配置文件的方法:
进入cdh的web页面,点击HDFS,点击操作,下载客户端配置。
以上是关于hadoop:HA场景下 java客户端远程访问hdfs配置的主要内容,如果未能解决你的问题,请参考以下文章