hadoop生态之sqoop
Posted 运维Linux和python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop生态之sqoop相关的知识,希望对你有一定的参考价值。
序言
在使用大数据的时候,各种不同的数据都要将数据采集同步到数据仓库中,一个是属于业务系统的RDBMS系统,也就是各种关系型数据库,一个是hadoop生态的存储,中间用于传输的数据的工具可以使用sqoop,也就是sql to hadoop。
在数据进入数仓的ODS层的时候,使用sqoop,在进入hadoop之后,就可以使用其他的计算框架进行分析,例如hive,MR,spark等。
sqoop
1 sqoop所处的位置
sqoop是一个用于数据传输的工具,是连接RDBMS和数仓ODS的桥梁:
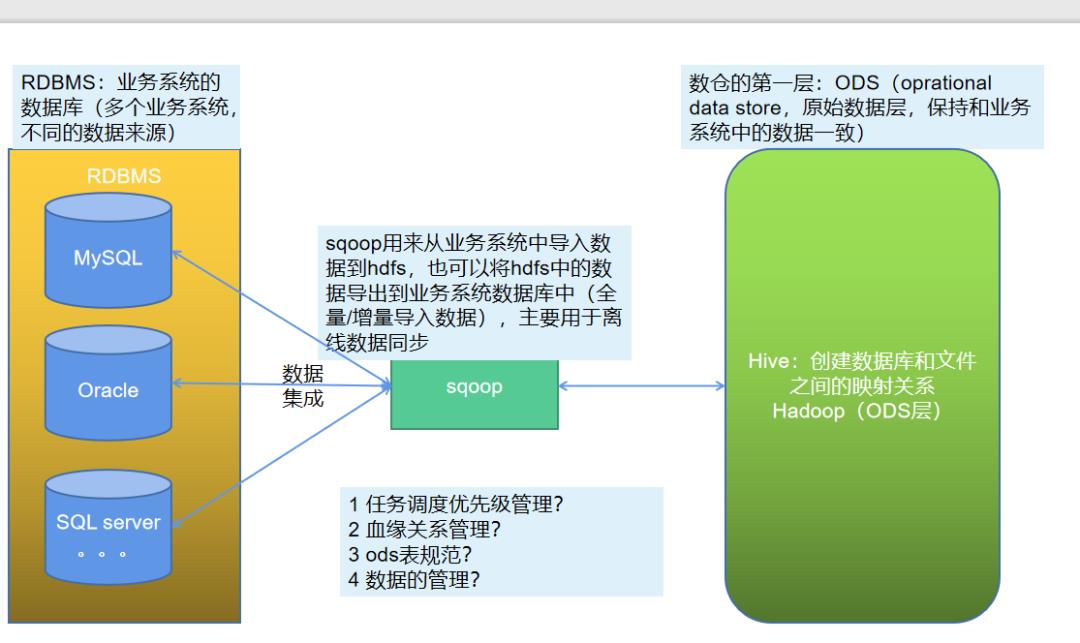
sqoop是将结构化数据同步到hdfs中,也可以是hive和hbase等,支持不同的数据库,只要将相关的连接数据库驱动放到安装sqoop的lib库中即可,从而能连接,进行数据的导入导出操作。
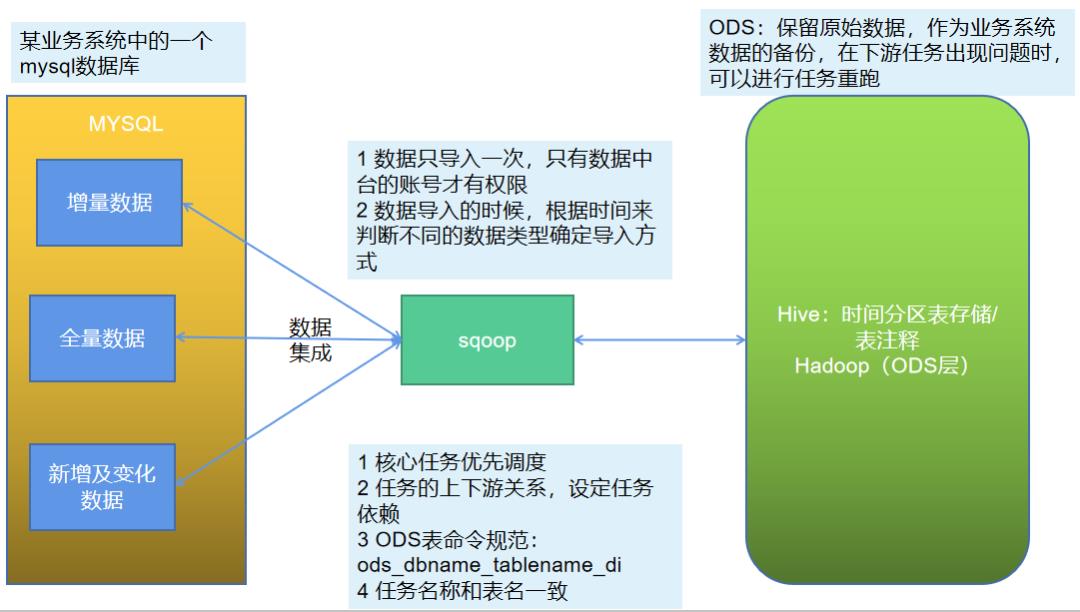
在进行使用sqoop的时候,考虑到任务数量的众多,需要从不同的业务系统中同步数据,而业务系统使用的数据库又是多种多样的,从数仓的建立来说,需要确定相关的指标,从而需要首先规划好哪些数据库,哪些数据需要同步,任务数量多,从而需要考虑任务的优先级管理,任务的优先级决定了指标的产出时间,可以划分核心指标,从而得到核心任务,也就是需要优先产出的任务,从而定义好相应的任务。
血缘关系,也就是sqoop数据导入任务才是第一步,后面还有数仓中的各种数据清洗,数据统计分析的任务,从而需要划分好任务依赖。
为了方便问题的排查,也就是对于sqoop的导入数据任务来说,每个导入使用一个导入job来实现。
ODS作为第一层,保持业务数据的一致性,基本不会对数据进行任何处理,直接保存在数仓中。从而表命名可以使用ods_databasename_tablename_di,ods表示表所在的层级,数据库名称表示数据的来源,而表名和业务系统一致,di表示每日增量day increase,全量的就不需要标注了,对于任务名称来说,也可以使用表名一致的方式,从而便于问题的排查,见名知意。
2 数据分类
在业务系统的表里面的数据,可以分为三类数据,一种是全量数据,这种表示同步的时候,只要全部同步就好,数据量比较少,而且变化的频率不高,像用户,地区这种维度表。

对于增量数据,也就是这个表里面的数据只会存在insert操作,而不会存在update操作,像交易表,这种只会新增记录,基本不会涉及修改。
对于新增及变化的数据,这种一般就是订单表,不但每天都会有新增的数据,而且会存在修改的动作,也就是修改订单的状态,从而每天都会发生变化。
3 sqoop使用
sqoop的安装很简单,只要下载之后,修改一下简单的配置就可以使用,但是由于sqoop需要使用hadoop的map任务,从而需要提前安装好hadoop,在这个基础上安装sqoop(注意将连接数据库的驱动放到sqoop的lib目录中)。
[root@KEL1 conf]# cat sqoop-env.sh
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.2
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/module/apache-hive-1.2.2
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
[root@KEL1 conf]# which hadoop
/opt/module/hadoop-2.7.2/bin/hadoop
全量导入(使用--query的方式):
#!/bin/bash
SQOOP=/opt/module/sqoop/bin/sqoop
JOB_DATE=$(date -d '-1 day' +%F)
if [[ -n "$2" ]];then
JOB_DATE=$2
fi
export_date()
$SQOOP import \\
--connect "jdbc:mysql://kel1:3306/shop?useUnicode=true&characterEncoding=utf-8" \\
--username root \\
--password root \\
--target-dir /user/root/shop/$1/$JOB_DATE \\
--delete-target-dir \\
--query "$2 and \\$CONDITIONS" \\
--num-mappers 1 \\
--fields-terminated-by ',' \\
--null-string '\\\\N' \\
--null-non-string '\\\\N'
#connect表示连接的mysql数据库的url地址,username表示用户名#passowrd表示连接数据库的密码,target-dir表示保存在hdfs的哪个路径
#delete-target-dir表示删除已经存在的目录,否则如果目录存在报错
#query表示查询导入的sql语句,num-mappers表示使用的map个数
#fields-terminated-by表示在hdfs上用什么分割字段
#null-string和null-non-stinrg表示在hdfs统一用\\N存储
export_date s_auction "select * from s_auction where 1=1"
全量导出:
#!/bin/bash
SQOOP=/opt/module/sqoop/bin/sqoop
JOB_DATE=$(date -d '-1 day' +%F)
if [[ -n "$2" ]];then
JOB_DATE=$2
fi
export_date()
$SQOOP export \\
--connect "jdbc:mysql://kel1:3306/shop?useUnicode=true&characterEncoding=utf-8" \\
--username root \\
--password root \\
--table $1 \\
--input-fields-terminated-by "," --fields-terminated-by ',' \\
--map-column-java gmt_create=java.sql.Date \\
--export-dir /user/hive/warehouse/ods_shop.db/$1/ds=$JOB_DATE
#注意数据类型的转换,从而使用了参数--map-column-java
export_date $1
执行之后,可以看到map程序的执行结果:
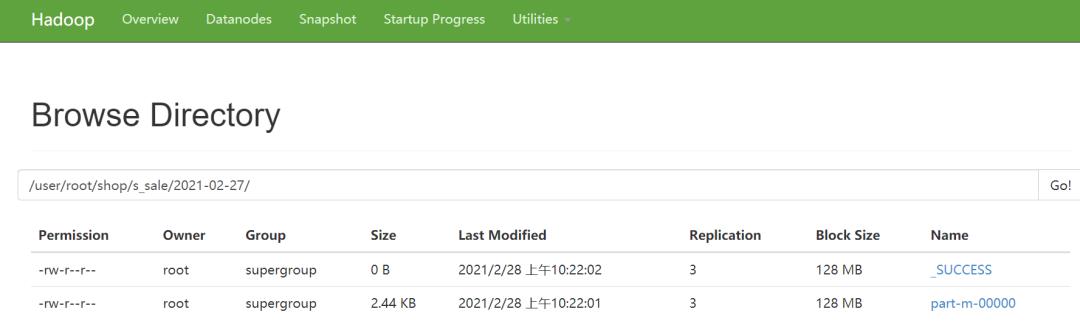
从文件名也可以看到只有map阶段,查看结果:

使用table的参数进行全量导入:
[root@KEL1 jobscript]# cat ods_shop_s_sale.sh
#!/bin/bash
SQOOP=/opt/module/sqoop/bin/sqoop
JOB_DATE=$(date -d '-1 day' +%F)
if [[ -n "$2" ]];then
JOB_DATE=$2
fi
export_date()
$SQOOP import \\
--connect "jdbc:mysql://kel1:3306/shop?useUnicode=true&characterEncoding=utf-8" \\
--username root \\
--password root \\
--target-dir /user/root/shop/$1/$JOB_DATE \\
--delete-target-dir \\
--num-mappers 1 \\
--fields-terminated-by ',' \\
--null-string '\\\\N' \\
--null-non-string '\\\\N' \\
--table s_sale
export_date s_sale
在使用--query的时候,可以指定你想要的列进行导入数据,也就是select指定具体的字段,从而可以进行导入。
在导出的时候,注意字段的对应关系,如果字段不对应,可能导致数据错位从而导致数据错误。
增量导入:
#!/bin/bash
SQOOP=/opt/module/sqoop/bin/sqoop
JOB_DATE=$(date -d '-1 day' +%F)
if [[ -n "$2" ]];then
JOB_DATE=$2
fi
export_date()
$SQOOP import \\
--connect "jdbc:mysql://kel1:3306/shop?useUnicode=true&characterEncoding=utf-8" \\
--username root \\
--password root \\
--target-dir /user/root/shop/$1/$JOB_DATE \\
--num-mappers 1 \\
--fields-terminated-by ',' \\
--null-string '\\\\N' \\
--null-non-string '\\\\N' \\
--table s_sale \\
--incremental append \\
--check-column id \\
--last-value 42
export_date s_sale
确定增量的时候,主要是根据你给的字段来进行判断是否为insert,从而每次也需要一个last-value来确定一个比较的值,最后会把增量的数据放在单独的文件中。
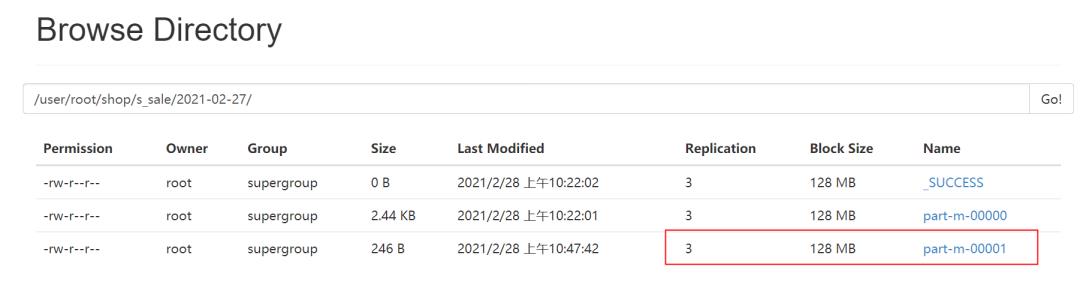
其中的内容则是新增的数据:

注意在使用这种增量数据导入的时候,数据库中id的类型,否则会报错,无法执行:
#使用增量导入的时候,checkcolumn必须是自增的rowid,否则导入报错
21/02/28 10:40:04 INFO tool.ImportTool: Maximal id query for free form incremental import: SELECT MAX(`id`) FROM `s_sale`
21/02/28 10:40:04 ERROR tool.ImportTool: Import failed: Character column (id) can not be used to determine which rows to incrementally import.
后续的值可以用来重新生成任务:

变化及新增:
#!/bin/bash
SQOOP=/opt/module/sqoop/bin/sqoop
JOB_DATE=$(date -d '-1 day' +%F)
if [[ -n "$2" ]];then
JOB_DATE=$2
fi
export_date()
$SQOOP import \\
--connect "jdbc:mysql://kel1:3306/shop?useUnicode=true&characterEncoding=utf-8" \\
--username root \\
--password root \\
--target-dir /user/root/shop/$1/$JOB_DATE \\
--num-mappers 1 \\
--fields-terminated-by ',' \\
--null-string '\\\\N' \\
--null-non-string '\\\\N' \\
--table s_sale \\
--incremental lastmodified \\
--check-column starts \\
--last-value "2018-01-01 00:00:00" \\
--mergy-key id
export_date s_sale
这个执行的时候,最好starts能根据数据的改变自动修改时间,这样就能进行一个时间的对比,并且按照mergykey的设定来进行数据的合并。
总体看来,如果表里面有两个时间字段,那么还是使用--query的形式来选择时间方便点。
3 导入到hive
如果是需要导入到hive里面,也有相关的参数可以用,做了两部分内容,一部分是创建hive的表结构,第二部分是导入数据;如果任务是导入到hdfs,那么还有一个手动load的过程。
在从hive里面导出的时候,需要手动建表,例如mysql里面的表需要提前创建好。
4 可能出现的问题
a 查找相关日志
导入数据的时候,使用sqoop的时候,不会显示详细的报错日志,如下所示,只能看到是export的任务失败,至于失败原因就不清楚了:
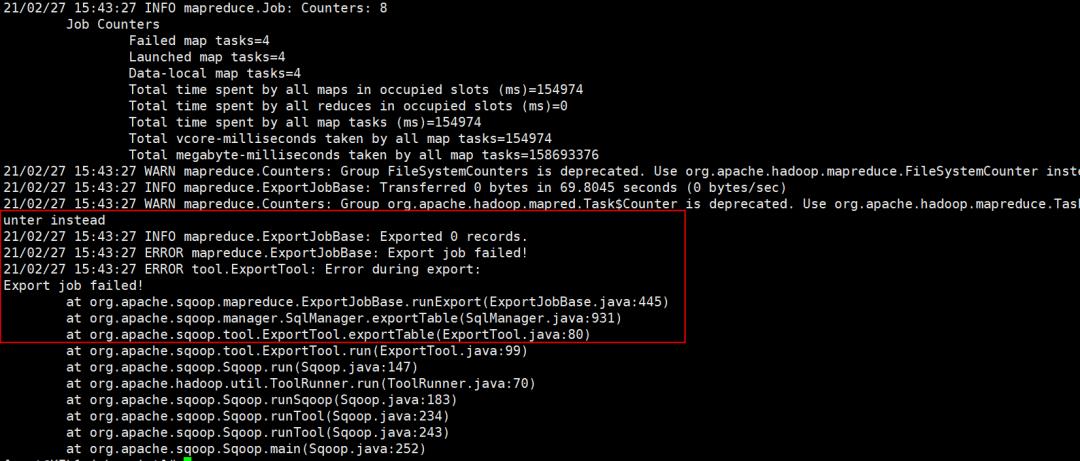
可以找到jobhistory的web页面,对比相关的任务号,在sqoop的日志中有相应的打印信息:

点击其中的job id,从而进入到job的详情页面,在application master处点击对应的log信息:
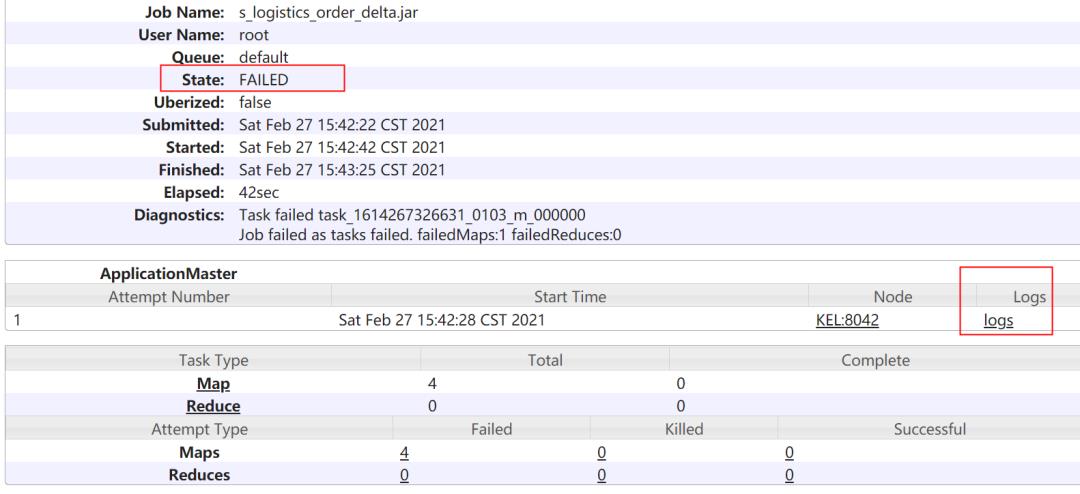
在日志的页面中,可以看到部分日志,需要再次找到full的日志,点击如下的here查看全部日志信息:
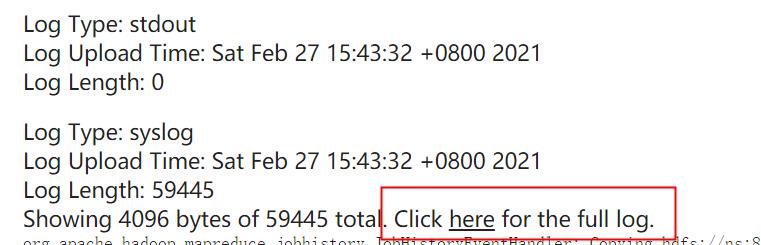
可以看到是因为日期的转换出现问题:
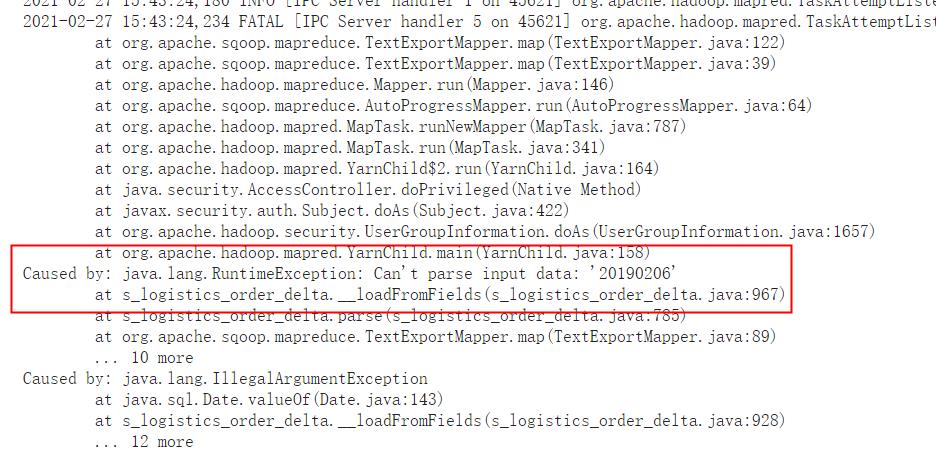
在对20190206转换成yyyy-mm-dd的时候,出现错误。
b 任务执行失败,jobhistory服务未启动
2021-02-25 23:30:50,336 Stage-1 map = 0%, reduce = 0%
java.io.IOException: java.net.ConnectException: Call From KEL1/192.168.1.99 to KEL:10020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at org.apache.hadoop.mapred.ClientServiceDelegate.invoke(ClientServiceDelegate.java:343)
at org.apache.hadoop.mapred.ClientServiceDelegate.getJobStatus(ClientServiceDelegate.java:428)
at org.apache.hadoop.mapred.YARNRunner.getJobStatus(YARNRunner.java:572)
at org.apache.hadoop.mapreduce.Cluster.getJob(Cluster.java:184)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:593)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:591)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.JobClient.getJobUsingCluster(JobClient.java:591)
at org.apache.hadoop.mapred.JobClient.getJobInner(JobClient.java:601)
at org.apache.hadoop.mapred.JobClient.getJob(JobClient.java:631)
sqoop连接10020端口,将相关日志发送到jobhistory服务器。

c 导入的目录已经存在
//导入的目录已经存在 --delete-target-dir
21/02/26 02:15:21 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
21/02/26 02:15:22 ERROR tool.ImportAllTablesTool: Encountered IOException running import job: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://ns/user/root/BUCKETING_COLS already exists
d 默认4个map任务,无法进行分割,split-by指定,或者使用1一个map任务
//到处的表没有主键,要么使用-m 1来指定一个map任务,要么使用split-by
21/02/26 02:12:14 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/e4ea9c1fb8c56a292e224d796c6812f8/COMPLETED_TXN_COMPONENTS.jar
21/02/26 02:12:14 ERROR tool.ImportAllTablesTool: Error during import: No primary key could be found for table COMPLETED_TXN_COMPONENTS. Please specify one with --split-by or perform a sequential import with '-m 1'.
e 字符串切割出错
// 在sqoop import 后面加参数 -Dorg.apache.sqoop.splitter.allow_text_splitter=true
21/02/26 02:19:42 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`TOKEN_IDENT`), MAX(`TOKEN_IDENT`) FROM `DELEGATION_TOKENS`
21/02/26 02:19:42 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/root/.staging/job_1614267326631_0013
21/02/26 02:19:42 ERROR tool.ImportAllTablesTool: Encountered IOException running import job: java.io.IOException: Generating splits for a textual index column allowed only in case of "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" property passed as a parameter
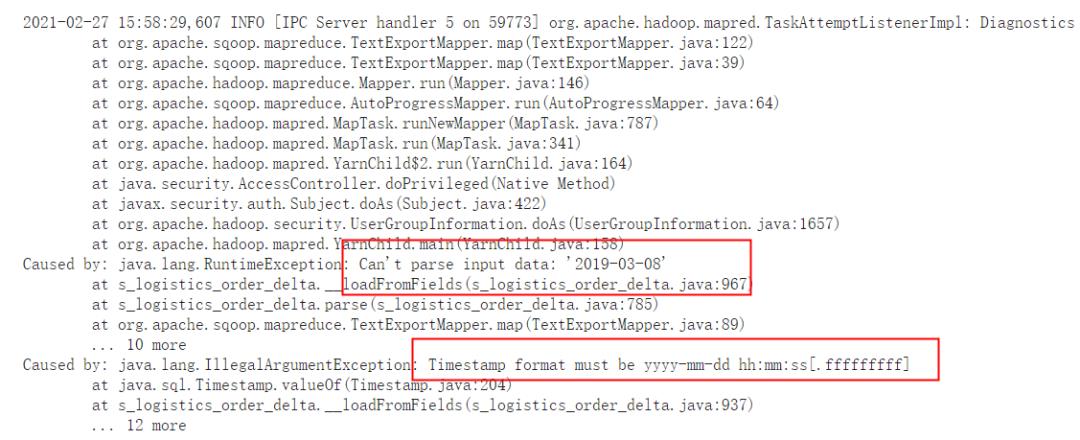
f 转换时间格式
2021-02-26 10:53:49,020 INFO [IPC Server handler 3 on 41321] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Diagnostics report from attempt_1614267326631_0082_m_000003_0: Error: java.io.IOException: Can't export data, please check failed map task logs
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:122)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.RuntimeException: Can't parse input data: '20190308'
at s_auction.__loadFromFields(s_auction.java:1176)
at s_auction.parse(s_auction.java:958)
at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:89)
... 10 more
Caused by: java.lang.IllegalArgumentException
at java.sql.Date.valueOf(Date.java:143)
at s_auction.__loadFromFields(s_auction.java:1029)
... 12 more
在hive中进行时间转换:
insert overwrite table ss_pay_order_delta PARTITION(ds='20210222')
select pay_order_id,total_fee,seller_id,buyer_id,
pay_status,from_unixtime(unix_timestamp(pay_time,'yyyymmdd'),
'yyyy-mm-dd') as pay_time,
from_unixtime(unix_timestamp(gmt_create,'yyyymmdd'),'yyyy-mm-dd')
as gmt_create,refund_fee,confirm_paid_fee
from s_pay_order_delta;
以上是关于hadoop生态之sqoop的主要内容,如果未能解决你的问题,请参考以下文章