数据分析实战 | Pandas交叉列表探寻用户数下降的原因
Posted Dream丶Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析实战 | Pandas交叉列表探寻用户数下降的原因相关的知识,希望对你有一定的参考价值。
大家好,我是丁小杰。
本篇是《数据分析实战》系列第二篇,案例来源为《数据分析实战》一书,书中使用的是 R 语言,接下来一段时间,我会用 Python + Tableau 尽可能的将案例复现出来,以供大家学习。
场景描述
某公司经营的一款 APP 小游戏,游戏的用户数一直维持在一定的水平。然而,从 9 月开始,用户数开始大量减少。根据以往经验尝试做出如下假设。
- 商业推广上存在问题,流失的用户数超过了新增的用户数
- 每月不同主题的游戏活动开始变得很无聊,用户都不爱玩了
- 按用户的性别或者年龄段等属性来划分用户群,可能是其中某个用户群出现了问题
经了解发现
- 同上月相比,商业推广的力度大体没变,新增用户数也大致保持在相同的水平
- 开展的各种游戏活动同上月相比几乎没有变化
因此,只剩下第 3 条假设没能得到验证了。再进一步深挖假设的内容,可以知道用户群通常是按照 性别 、年龄段 等来划分的。于是,首先我们可以考虑是否有某个属性的用户群数量减少了,然后通过和上月的数据加以比较,确认用户数量减少了的用户属性,并思考如何恢复用户数量。
注:由于无法事先猜测问题出现的原因,而是需要通过数据分析来探索原因所在,这种方式称为“探索型数据分析”。
数据描述
DAU(Daily Active User)
每天至少来访 1 次的用户数据,139112 行。
| 字段 | 类型 | 含义 |
|---|---|---|
| log_date | str | 访问时间 |
| app_name | str | 应用名 |
| user_id | numpy.int64 | 用户 ID |
user_info
用户属性数据
| 字段 | 类型 | 含义 |
|---|---|---|
| install_data | str | 首次使用日期 |
| app_name | str | 应用名称 |
| user_id | numpy.int64 | 用户 ID |
| gender | str | 性别 |
| generation | numpy.int64 | 年龄段 |
| device_type | str | 设备类型 |
数据分析
数据读取
读取两个数据集。
import pandas as pd
DAU_data = pd.read_csv('DAU.csv')
user_data = pd.read_csv('user_info.csv')
显示 DAU 数据集前五行。
DAU_data.head()
显示 user_data 数据集前五行。
user_data.head()
将 DAU 与 user_data 以 user_id 为 key 进行合并,取交集。
all_df = DAU_data.merge(user_data, on=['user_id', 'app_name'])
all_df.head()
修改,新增列。
| 列名 | 修改前 | 修改后 |
|---|---|---|
| gender | F/M | 女/男 |
| generation | 10 | 10-19 |
| 新增 log_month | 2013-08-01 | 8 月 |
import numpy as np
all_df['gender'] = all_df['gender'].replace('F':'女','M':'男')
all_df['generation'] = all_df['generation'].apply(lambda x:str(x) + '-' + str(x + 9))
all_df['log_month'] = pd.to_datetime(all_df['log_date']).map(lambda x : x.strftime("%m")[1] + '月'
用户性别分析
统计两月中男女用户的人数,看看性别比例是否相差较大。
all_df.pivot_table(index='log_month',
columns='gender',
values='user_id',
aggfunc=np.count_nonzero)
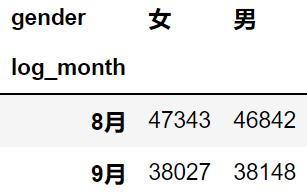
从上表来看,虽然整体上用户数量在较少,但性别比例没有很大变化。因此,用户数量减少的主要原因并不是某一性别用户大量减少。
用户年龄段分析
统计各个年龄段用户数量的变化情况。
all_df.pivot_table(index='log_month',
columns='generation',
values='user_id',
aggfunc=np.count_nonzero)
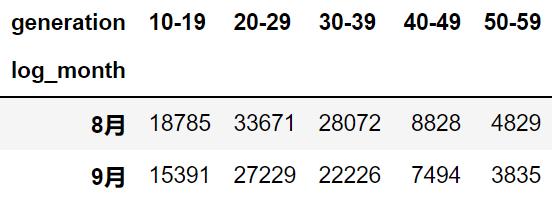
无论哪个年龄段,用户的比例都没有发生大的变化。
用户性别&年龄段分析
进一步细分,看看是否某个性别下某个年龄段的用户数量减少了,下面我们将性别和年龄段组合起来,形成 2 重交叉列表统计。
all_df.pivot_table(index='log_month',
columns=['gender','generation'],
values='user_id',
aggfunc=np.count_nonzero)
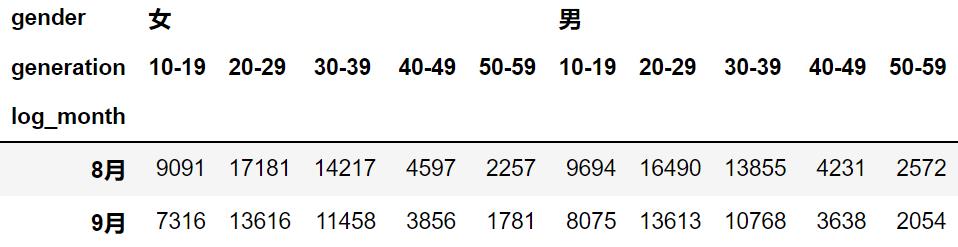
同样的,每个用户群所占的比例基本不变,没有用户群数量大幅减少的情况。
用户设备
最后一个维度,统计用户使用的设备差异。
all_df.pivot_table(index='log_month',
columns='device_type',
values='user_id',
aggfunc=np.count_nonzero)
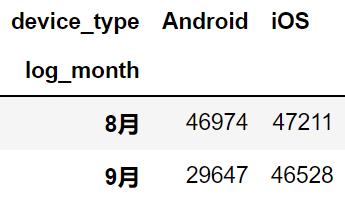
根据上表,明显看到使用 android 的用户大量减少。
下面我们以天为单位,详细看看两种设置使用用户的变化情况。
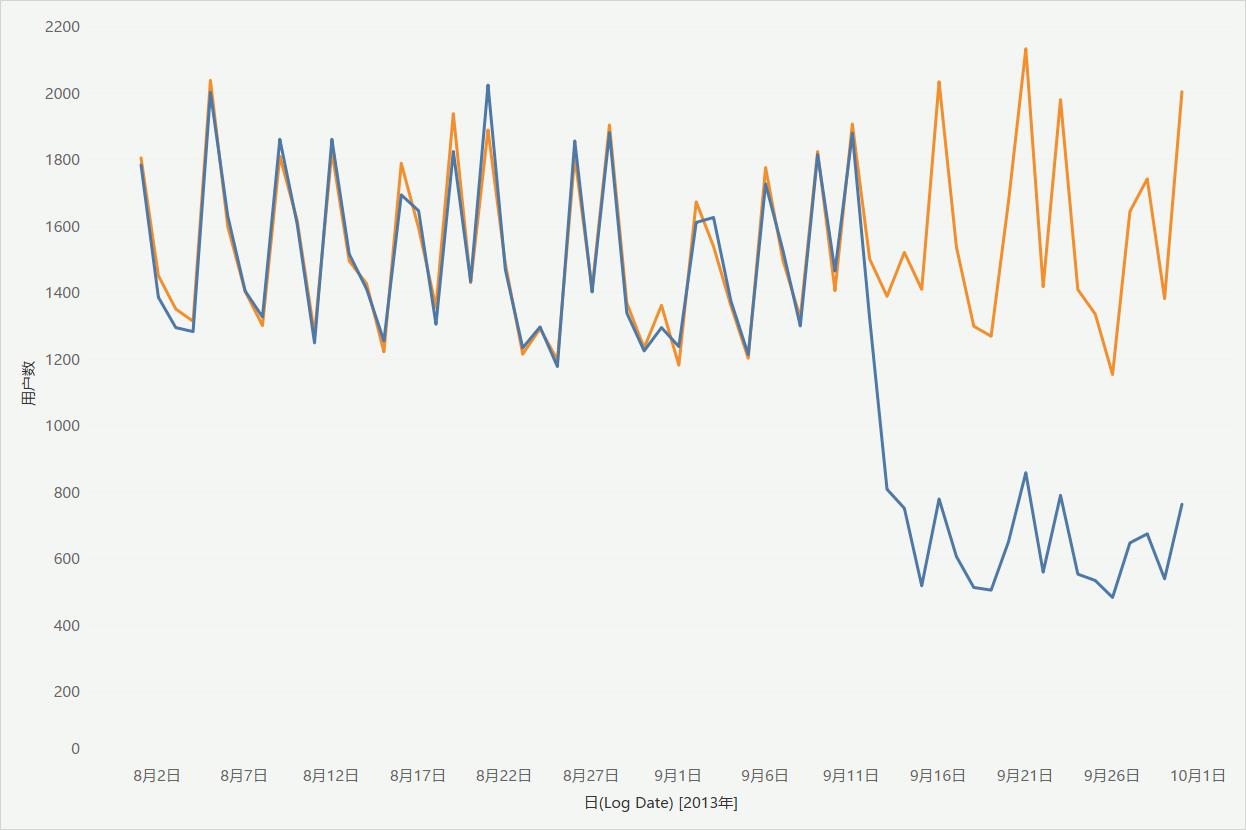
通过上图,可以看到,Android 的用户数从 9 月 13 日开始急剧减少。
那么下一步就是弄清楚 Android 手机端出现的问题,并制定相应的改善策略,使用户数量回到和上月相同的水平,这里就不详细展开了。
这就是今天要分享的内容,我们下期再见!
案例参考
[1]《数据分析实战》 [日] 酒卷隆志 里洋平/著 肖峰/译
对于刚入门 Python 或是想要入门 Python 的小伙伴,可以通过下方小卡片联系作者,一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。另有整理的近千套简历模板,几百册电子书等你来领取哦!
以上是关于数据分析实战 | Pandas交叉列表探寻用户数下降的原因的主要内容,如果未能解决你的问题,请参考以下文章