ZooKeeper架构&CAP理论
Posted 总要冲动一次
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper架构&CAP理论相关的知识,希望对你有一定的参考价值。
Zookeeper架构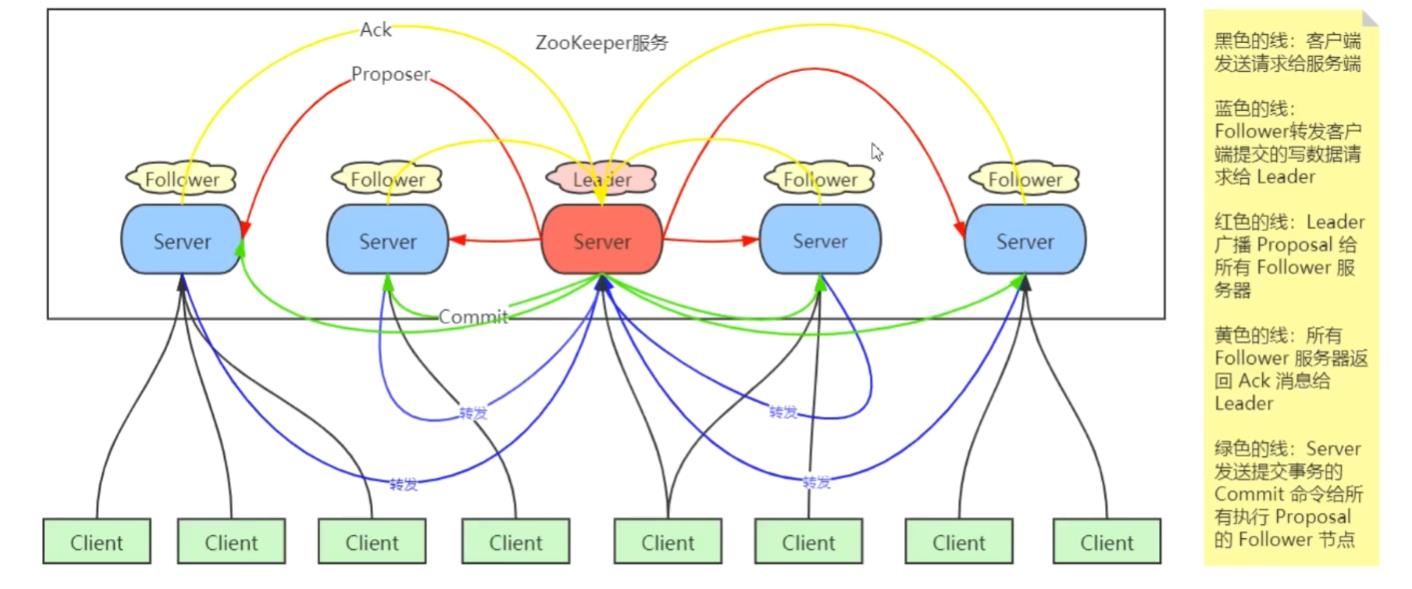
ZooKeeper是一种高性能,可扩展的服务,虽然读取速度比写入快,但是读取和写入操作都设计的极为快速,这样做的原因是在读取的情况下,ZooKeeper可能会提供较旧的数据
为分布式应用提供高效、高可用的分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务
Zab协议是Zookeeper保证数据一致性的核心算法,Zab借鉴了Paxos算法,但又不像Paxos那样,是一种通用的分布式一致性算法,基于该协议,zk实现了一种主备模型(即Leader和Follower模型),保证了事务的最终一致性
数据一致性是靠Paxos算法保证的 Paxos可以说是分布式一致性算法的鼻祖 是ZooKeeper的基础
1,首先客户端所有的写请求都由一个Leader接收,而其余的都是Follower(从者)
2,Leader 负责将一个客户端事务请求,转换成一个 事务Proposal,并将该 Proposal 分发给集群中所有的 Follower(备份) ,也就是向所有 Follower 节点发送数据广播请求(或数据复制)记住这里发送给的不光是数据本身,还有其他的,相当于包装
3,分发之后Leader需要等待所有Follower的反馈(Ack请求),在Zab协议中,只要超过半数的Follower进行了正确的反馈后(也就是收到半数以上的Follower的Ack请求),那么 Leader 就会再次向所有的 Follower发送 Commit 消息,要求其将上一个 事务proposal 进行提交。
CAP理论
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistence) (等同于所有节点访问同一份最新的数据副本)
可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
分区容错性(Network partitioning)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
对于zookeeper来说,它实现了A可用性、P分区容错性、C中的写入强一致性,丧失的是C中的读取一致性。
如果客户端A将znode / a的值从0设置为1,则告诉客户端B读取/ a,则客户端B可以读取旧值0,这取决于它连接到的服务器。如果客户端A和客户端B读取相同的值很重要,则客户端B应该在执行读取之前从ZooKeeper API方法调用sync()方法。
原文参考:https://www.icode9.com/content-4-1124915.html
以上是关于ZooKeeper架构&CAP理论的主要内容,如果未能解决你的问题,请参考以下文章