VCIP2021:利用解码信息进行超分辨率
Posted Dillon2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VCIP2021:利用解码信息进行超分辨率相关的知识,希望对你有一定的参考价值。
本文来自VCIP2021《CNN-based Super Resolution for Video Coding Using Decoded Information》

简介
随着高分辨率视频的增多,给带宽受限的情况下视频传输带来了巨大的挑战。为了解决这个问题,可以采用重采样的编码方法,如Fig.1,视频在编码前先进行下采样,然后编码低分辨率的视频,解码端在解码后再进行上采样恢复原来的分辨率。AV1中就存在对下采样的帧进行编码在解码端再进行上采样的模式。VVC中也支持RPR。
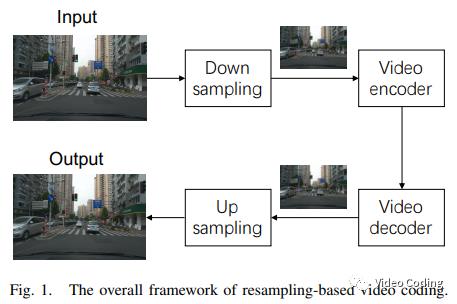
随着基于CNN的超分辨(SR)的发展,它在视频编码中有巨大潜力。论文提出了在视频编码中结合编码信息的SR。在已有的研究中SR和编码器通常都是作为相互独立的部分,而论文提出在SR中不仅使用重建信息还使用了预测信息、QP等编码信息。
模型设计
由于亮度和色度的不同特点,为亮度和色度分别设计SR模型。
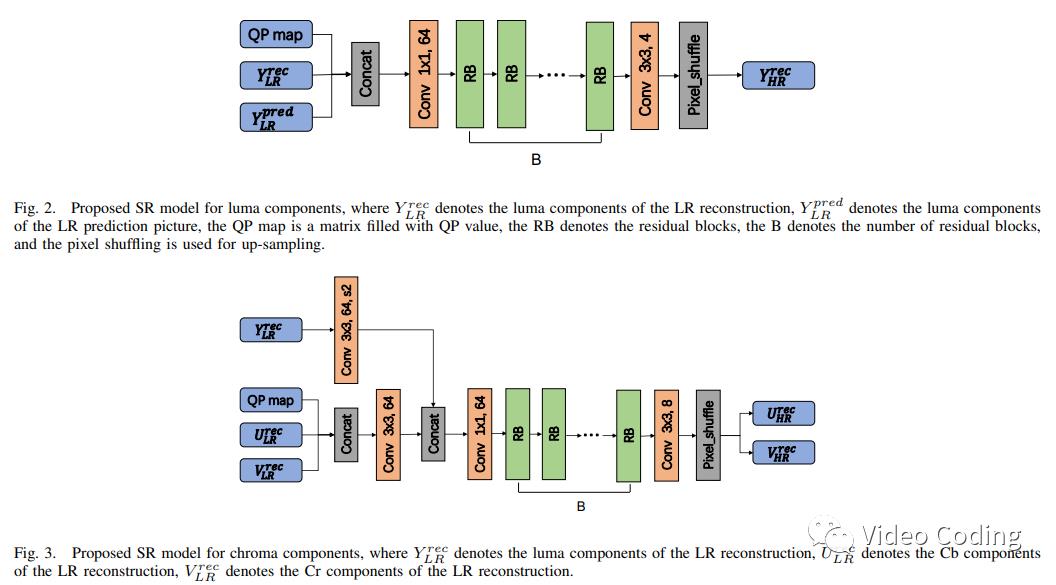
Fig.2是亮度模型的结构,输入包括重建信息、预测信息和QP map,基准模型选择single-scale EDSR,由于每个卷积层仅有64个特征通道所以模型没有残差缩放层。图中RB是残差块结构,共有16个。最后一个卷积层有4个通道,然后通过shuffle层生产高分辨率重建图像。
Fig.3是色度模型的结构,和亮度模型的主要区别在于输入,为了充分利用纹理信息亮度重建信息也作为输入。其中亮度重建信息要通过步长为2的卷积层下采样到和色度同样的分辨率。模型输入还包括色度U的重建信息、色度V的重建信息以及QP map,输入中并不包含预测信息。
实验结果
数据集
使用DIV2K数据集训练模型,图像转换为YUV420格式,使用VTM11.0在RPR配置下编码,QP=22,27,32,37,42,训练图像在编码前先进行2倍下采样,然后用解码后的低分辨率图像及对应的原始分辨率图像训练。
实验配置
使用PyTorch框架训练模型,采用Tesla V-100 GPU训练,mini-batch size设置为16,使用Adam优化器学习率为le-4,每200轮按0.5的衰减因子缩小学习率。
实验结果
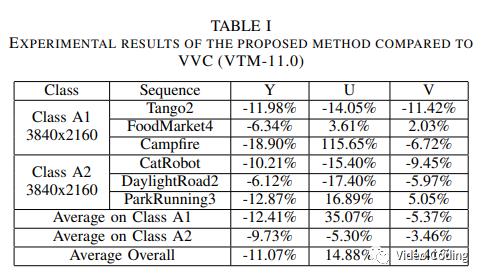
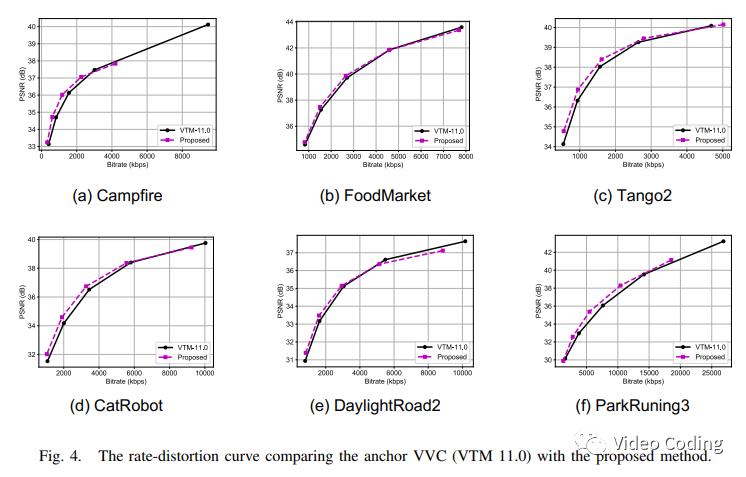
编码器采用All Intra配置,QP=22,27,32,37,42,结果如表1所示,Fig.4是各序列的RD曲线。增益主要来自低码率部分,这表明该方法对于低带宽场景效果更好。
感兴趣的请关注微信公众号Video Coding

以上是关于VCIP2021:利用解码信息进行超分辨率的主要内容,如果未能解决你的问题,请参考以下文章