Momentum Contrast for Unsupervised Visual Representation Learning
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Momentum Contrast for Unsupervised Visual Representation Learning相关的知识,希望对你有一定的参考价值。
Motivation
已有的利用contrastive learning做unsupervised visual representation learning要么受限于GPU不能使用大batch,要么不能保证query和key一致
因此本文提出了Momentum Contrast (MoCo),利用队列和moving-averaged encoder构建一个动态字典
Review Unsupervised/self-supervised
Pretext tasks
首先做无监督CV的表示学习,需要想一个pretext,比如NLP中的完形填空:抽取小说中一段话,随机扣除一个词,预测出改词。
CV中pretext有
- 去噪:原图加一些噪声送入网络输出去噪后的图
- 上色:将原图变成灰度图送入网络输出上色后的图
- 旋转图片预测角度
- 扣除原图的某一个patch,要求网络补出来
- 将图片切分几块后打乱,要求给出每块正确的位置
- 打乱一段视频帧给出正确的顺序或者判断一段视频帧是否被打乱过
- GAN中数据生成
- 对图片进行随机augmentation(crop,颜色抖动等等),然后判断一对图片是否来自于同一张图片,本文采用的该pretext
- 等等
Loss functions
- L1 or L2 losses:比如pretext去噪上色等任务都可以用
- cross-entropy or margin-based losses:比如pretext给出打乱图片块的正确位置
- Adversarial losses:测量两个分布的差异,常用于GAN,无监督数据生成
- Contrastive losses:测量一对样本在表示空间里的相似度,起源于Yann LeCun “Dimensionality Reduction by Learning an Invariant Mapping”
主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
有很多形式,原文中提供了如下的形式:
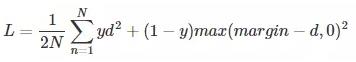 ,margin是一个超参
,margin是一个超参
当y=1时,即认为该pair是匹配的,原本相似的样本,如果在特征空间的欧式距离较大,则说明当前的模型不好,因此加大损失。

当y=0时,即认为该pair不匹配时,样本不相似时,其特征空间的欧式距离反而小的话,损失值会变大:当d>margin时,loss=0,当d=0,loss=margin*margin

下图margin取值1.5,蓝色是不匹配时的函数曲线,红色是匹配时的函数曲线
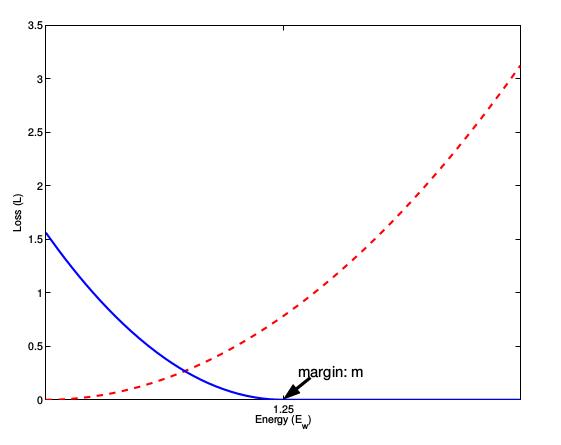
很多CV的无监督也利用这种思想Contrastive Learning
Method
Contrastive Learning as Dictionary Look-up
对于一个query q和一个encoded的样本集合k0,k1…,这其中有一个k+是可以和query匹配的,和上述Contrastive losses达到一样目的的另一种形式InfoNCE:
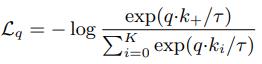
q*ki为点乘相似度,i=0-K,一个正样本和K个负样本。
本文采用了该种Contrastive losses,只有原本匹配的样本更相似,原本不匹配的不相似时,loss才低,如式子所示,q和k+要更相似,和其他key要不相似
备注:此处的匹配对应本文pretext中所说的:该对随机增强的图片c来自于同一个图片
Momentum Contrast
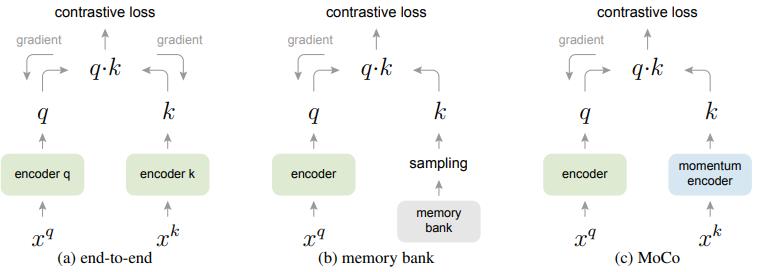
实现上述做法有三种做法
- end2end,q和k的encoder可相同也可不相同,取一个batch,其中1个可以匹配的key,K个不可以匹配的key。但是受限于GPU,batch不可能太大,想尽了办法使用了大batch,又会遇到大batch本身优化难的问题;如果batch小的时候,下一个batch和该batch的参数不一样了,就不能保持一致了
- memory bank,先把所有样本的特征保存下来,仅bp query的encoder,但是这样又会有问题,只有当所有key被sample完以后才会更新memory bank,不同的key在和query是不一致的,因为每一次sample encoder都会更新虽有memory bank后面也加入了momentum,但是是针对sample来的,在更新memory bank时会保留一部分上一轮的特征值
- MoCo,是以上两者的融合版本,只是把memory bank改成了queue,每sample一个batch key,就从队尾扔掉一个batch, 把最近的batch插入进来,扔掉的batch是最过时的,最古老的encoder参数得到的特征这样就可以把字典做大做大,之前字典大小就是batch大小,计算相似度需要bb,现在是bK,K是队列长度,K可以设置很大了。但是使用队列可以使字典变大,但是它也给反向传播训练key编码器带来了极大的难度(瞎猜:反向过来的梯度很多,更新太大?)所以在encoder的参数出加了momentum,稳定训练。

l_pos是x点乘x的变种计算的相似度,都是匹配的正样本
l_neg是x点乘队列计算的相似度,都是不匹配的负样本
两个cat一块刚好是每个样本都得到一个正例和K个负例,K是队列长度
Trick
为了防止BN泄露batch样本之间的信息,使用了shuffleBN:For the key encoder fk, we shuffle the sample order in the current mini-batch before distributing it among GPUs (and shuffle back after encoding);
Experiments
ImageNet分类任务
K = 65536,m=0.999
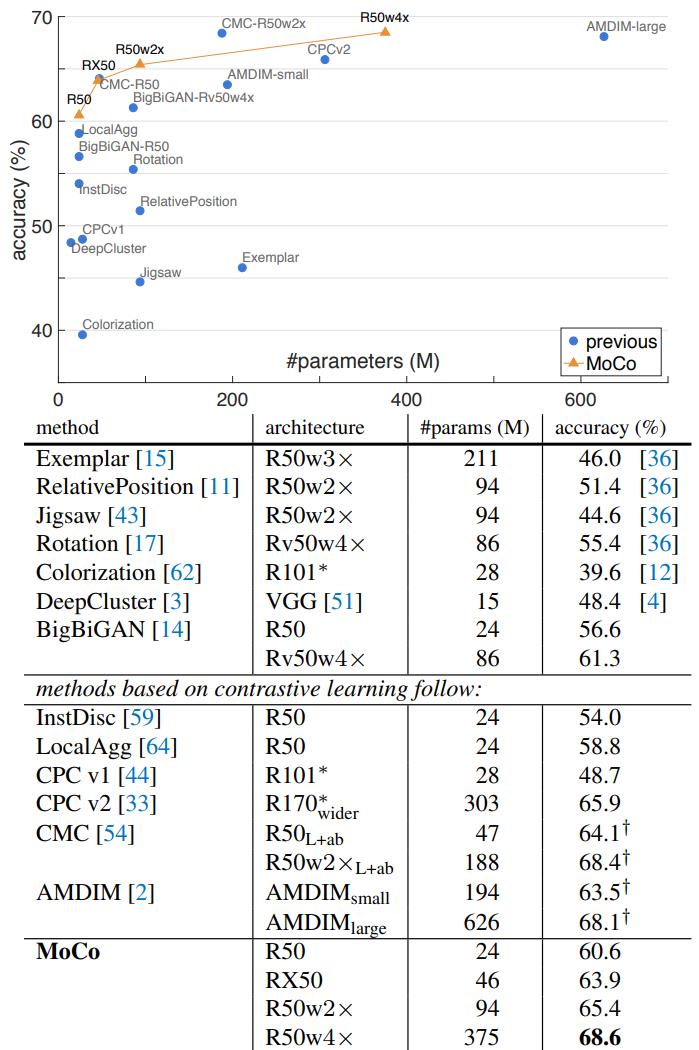
以上都是用ImageNet1M做无监督预训练然后固定特征提取部分,仅训练最后的fc,效果好于其他无监督方法,但是离有监督的还是有点差距。
如果不固定特征部分,可以达到77.0%,是可以超过random init的76.5%,当用IG-1B无监督预训练后再end2end的fine tuning可以达到77.3%。
发现IG-1B的提升效果没有比IN-1M好很多,证明还有很大的空间提升,来更好的利用大数据
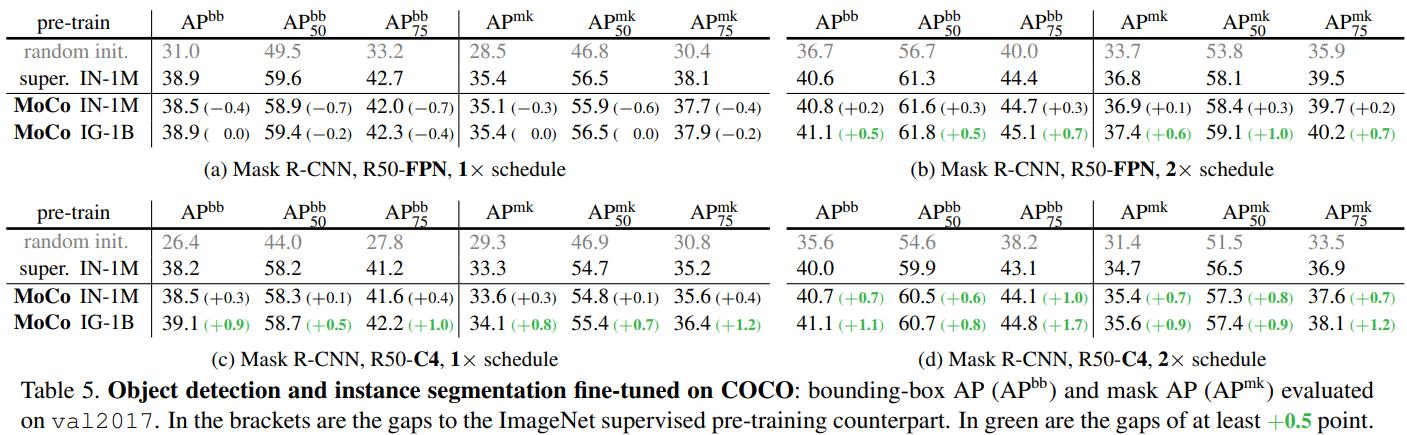
Detection
注意检测时由于batch很小,之前的detectron之类的代码仓库在finetuning时都用affine layer固定bn参数,而本文把采用了synchronized across GPUs
给出的理由时:为了对比公平我们都采用了有监督的超参,但是之前的训练超参都是在有监督的基础上设置的不适合无监督方法,因此我们需要做feature normalization,因此打开了bn
pascal voc

coco
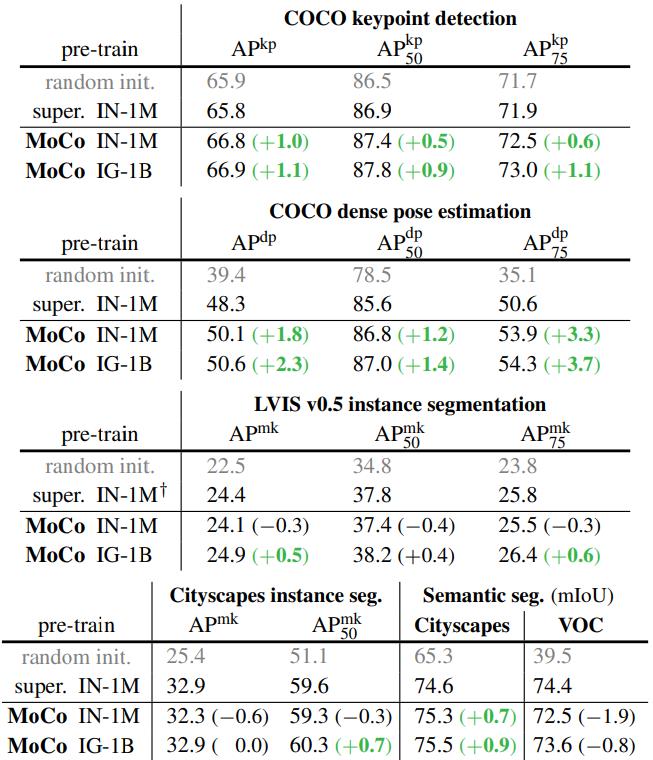
其他Tasks
以上是关于Momentum Contrast for Unsupervised Visual Representation Learning的主要内容,如果未能解决你的问题,请参考以下文章