模型无关方法
Posted 上下求索.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型无关方法相关的知识,希望对你有一定的参考价值。
第6章 模型无关方法
将解释与机器学习模型(=与模型无关的解释方法)分开有一些优势(Ribeiro、Singh 和 Guestrin 20161)。与模型无关的解释方法相比特定模型的解释方法的最大优势在于它们的灵活性。当解释方法可以应用于任何模型时,机器学习开发人员可以自由使用他们喜欢的任何机器学习模型。任何建立在机器学习模型解释上的东西,例如图形或用户界面,也变得独立于底层机器学习模型。通常,不仅要评估一种,而且要评估多种类型的机器学习模型来解决任务,并且在根据可解释性比较模型时,使用与模型无关的解释更容易,因为相同的方法可用于任何类型的模型。
与模型无关的解释方法的替代方法是仅使用可解释的模型,与其他机器学习模型相比,这通常具有很大的缺点,即预测性能会丢失,并且你将自己限制在一种类型的模型中。另一种选择是使用特定于模型的解释方法。这样做的缺点是它还将你绑定到一种模型类型,并且很难切换到其他模型类型。
与模型无关的解释系统的理想方面是(Ribeiro、Singh 和 Guestrin 2016):
- 模型灵活性:解释方法可以与任何机器学习模型一起使用,例如随机森林和深度神经网络。
- 解释的灵活性:你不限于某种形式的解释。在某些情况下,使用线性公式可能很有用,在其他情况下,使用具有特征重要性的图形。
- 表示灵活性:解释系统应该能够使用不同的特征表示作为被解释的模型。对于使用抽象词嵌入向量的文本分类器,最好使用单个词的存在来进行解释。
更大的图景
让我们从高层次上看一下与模型无关的可解释性。我们通过收集数据来捕捉世界,并通过学习使用机器学习模型预测数据(用于任务)来进一步抽象它。可解释性只是帮助人类理解的另一层。
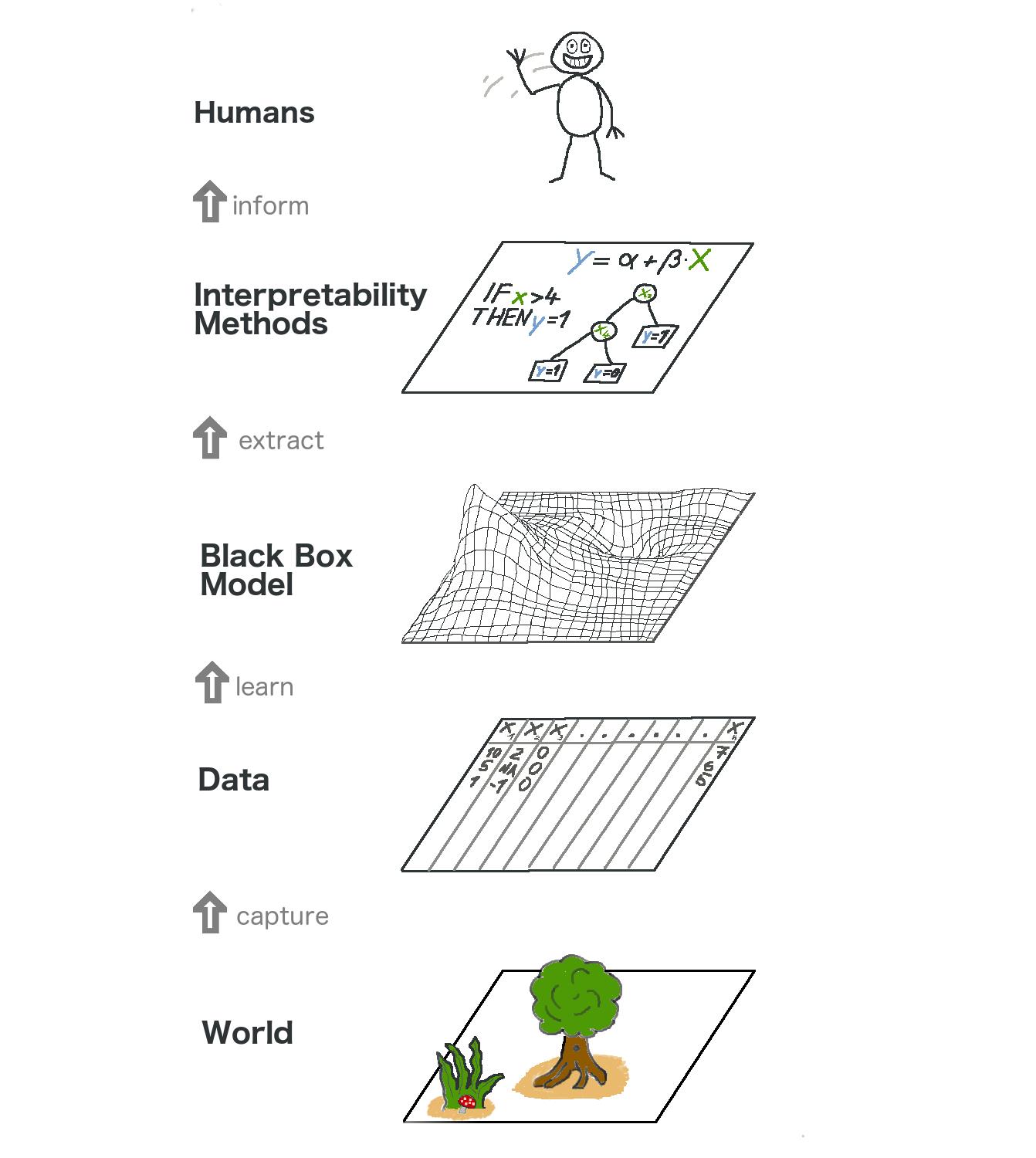
图 6.1:可解释机器学习的大图。现实世界在以解释的形式到达人类之前要经过许多层。
最底层是世界。这实际上可能是自然本身,例如人体的生物学及其对药物的反应,但也可能是更抽象的事物,例如房地产市场。世界层包含所有可以观察到的和感兴趣的内容。最终,我们想了解世界并与之互动。
第二层是数据层。我们必须将世界数字化,以使其可用于计算机处理并存储信息。数据层包含图像、文本、表格数据等任何内容。
通过基于数据层拟合机器学习模型,我们得到了黑盒模型层。机器学习算法使用来自现实世界的数据进行学习以进行预测或查找结构。
黑盒模型层之上是可解释性方法层,它帮助我们处理机器学习模型的不透明性。特定诊断的最重要特征是什么?为什么金融交易被归类为欺诈?
最后一层由人类占据。看!它向你挥手是因为你正在阅读这本书并帮助为黑盒模型提供更好的解释!人类最终是解释的消费者。
这种多层抽象还有助于理解统计学家和机器学习从业者之间的方法差异。统计学家处理数据层,例如计划临床试验或设计调查。他们跳过黑盒模型层,直接进入可解释性方法层。机器学习专家还处理数据层,例如收集皮肤癌图像的标记样本或爬取维基百科。然后他们训练一个黑盒机器学习模型。解释方法层被跳过,人类直接处理黑盒模型预测。可解释的机器学习融合了统计学家和机器学习专家的工作,这很酷。
当然,这张图并不能捕捉到一切:数据可能来自模拟。黑盒模型还输出甚至可能无法到达人类的预测,而只能提供给其他机器,等等。但总的来说,理解可解释性如何成为机器学习模型之上的新层是一个有用的抽象。
与模型无关的解释方法可以进一步区分为局部方法和全局方法。本书也是按照这种区别组织的。[全局方法]](#global-methods)描述了特征如何均等地影响预测。相反,局部方法旨在解释个体预测。
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Model-agnostic interpretability of machine learning.” ICML Workshop on Human Interpretability in Machine Learning. (2016). ↩︎
以上是关于模型无关方法的主要内容,如果未能解决你的问题,请参考以下文章