一次因为kafka分区的leader不为优先副本导致的消费堆积问题的原因排查及问题解决方法
Posted worldchinalee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次因为kafka分区的leader不为优先副本导致的消费堆积问题的原因排查及问题解决方法相关的知识,希望对你有一定的参考价值。
一次因为kafka分区的leader不为优先副本导致的消费堆积问题的原因排查及问题解决方法
问题描述
首先,收到了消息堆积的报警,查看监控发现延迟如下: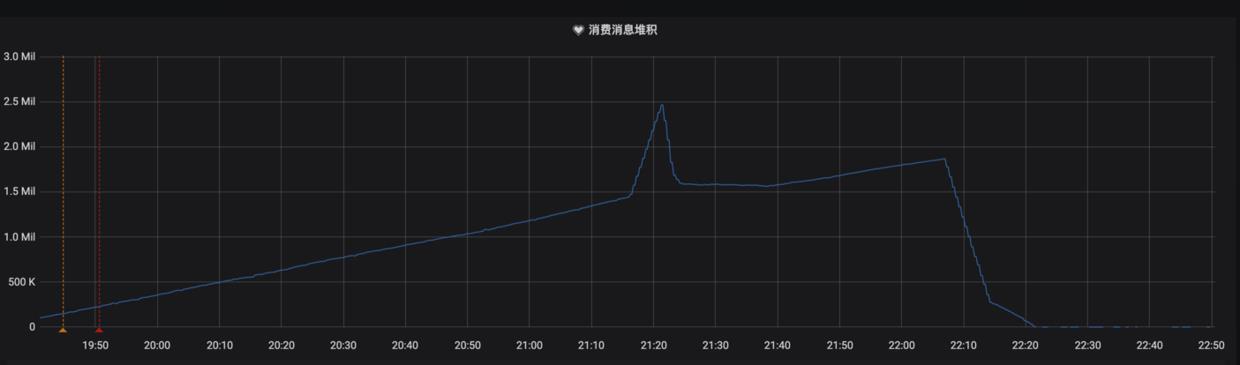
接下来用kafka客户端脚本工具,查看具体延迟信息: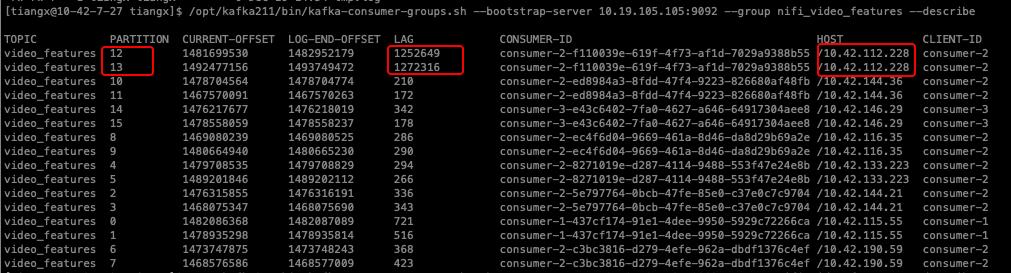
发现延迟发生在2个partition(12,13)上,且消费者为同一台机器10.42.112.228
问题排查过程
消费端问题?
因为延迟partition的消费者在同一台机器,所以开始怀疑是否消费端存在问题?
因此,基本断定partition12、13所在的kafka服务端存在问题。
-
查看该消费端机器10.42.112.228的cpu、内存、磁盘等状态,未发现明显异常
-
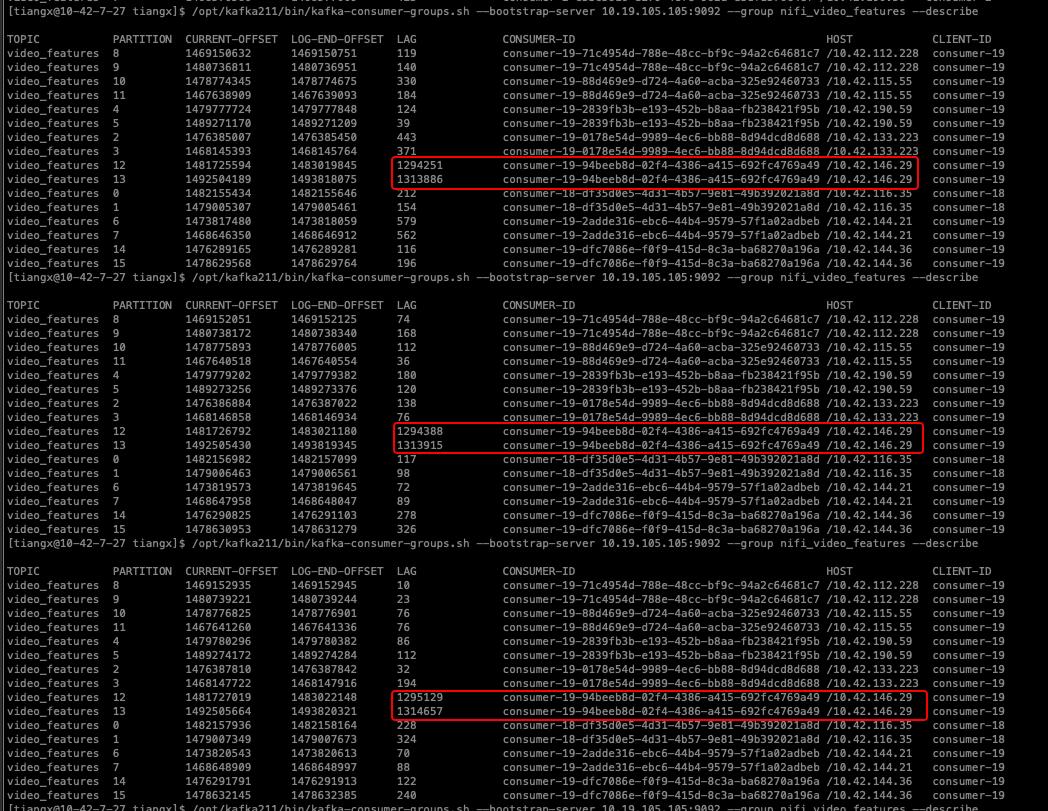
重启该消费任务,发现2个延迟严重的partition被分配到了其他机器,且继续观察后发现,消费延迟在继续增大,进一步确认大概率非客户端问题(下图)
-
-
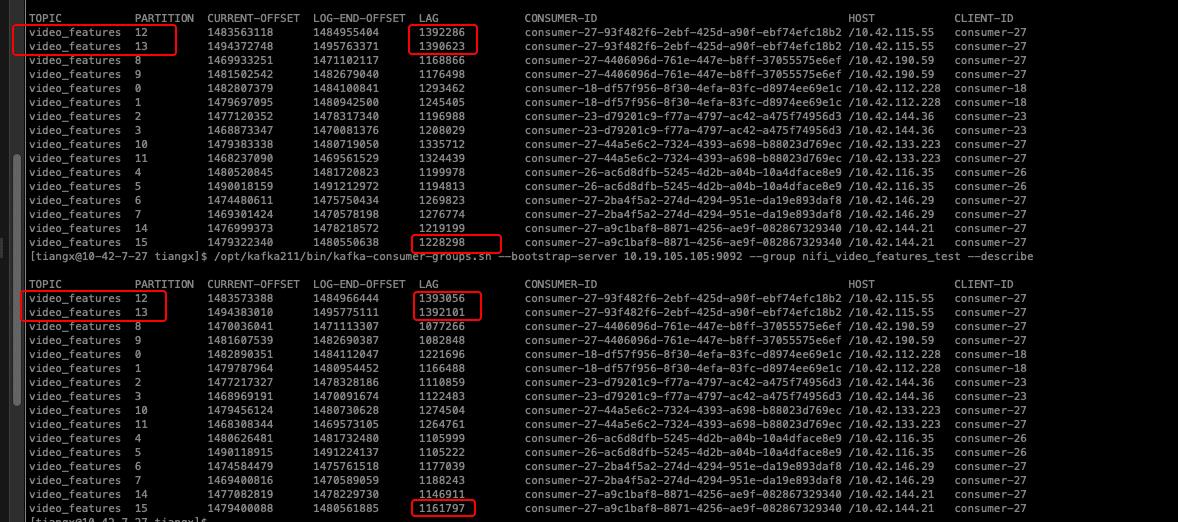
重新启动一个消费任务,从topic的最早消息开始消费,任务启动后,发现partition12、13的消费速度明显慢于其他分区(下图):
kafka服务端问题
查看kafka服务端日志未发现明显异常
查看partition12、13所在节点的机器监控,也未发现异常:
查看topic的状态: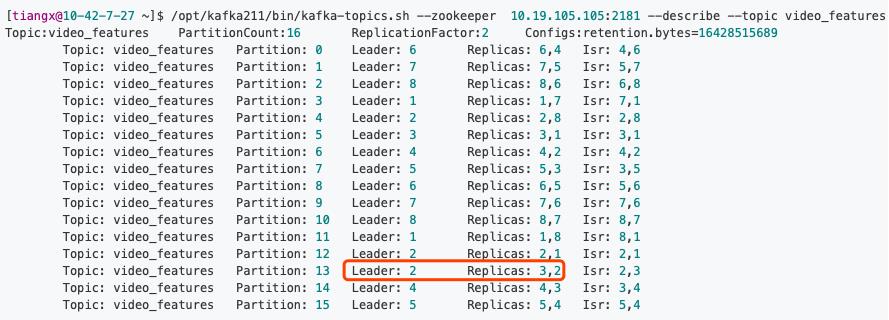
直接使用上面的脚本,会把集群中所有topic的所有分区都执行一遍重新平衡,如果集群中需要重平衡的副本较多,则会对客户端带来一定的影响,所以一般生产环境中在使用脚本kafka-perferred-replica-election.sh 的时候会加参数path-to-json-file来指定一个json文件,以对部分分区进行leader重平衡。
我们只对topic video_features的分区12、13进行优先副本选举,需要编写一个json文件test1.json:
发现,partition13的优先副本是3(AR集合列表为Replicas: 3,2),但是实际leader为2,如此一来,节点2的负载变高,节点3的负载变低,原本均衡的负载就失衡了,可能会直接导致消费延迟。
解决方法
Kafka 中 kafka-perferred-replica-election.sh 脚本提供了对分区 leader 副本进行重平衡的功能。
优先副本的选举过程是一个安全的过程,Kafka 客户端可以自动感知分区 leader 副本的变更。
直接使用上面的脚本,会把集群中所有topic的所有分区都执行一遍重新平衡,如果集群中需要重平衡的副本较多,则会对客户端带来一定的影响,所以一般生产环境中在使用脚本kafka-perferred-replica-election.sh 的时候会加参数path-to-json-file来指定一个json文件,以对部分分区进行leader重平衡。
我们只对topic video_features的分区12、13进行优先副本选举,需要编写一个json文件test1.json:
"partitions":[
"partition":12,
"topic":"video_features"
,
"partition":13,
"topic":"video_features"
]
执行脚本:
[tiangx@10-42-7-27 ~]$ /opt/kafka211/bin/kafka-preferred-replica-election.sh --zookeeper 10.19.23.215:2181 --path-to-json-file test1.json
Created preferred replica election path with video_features-12,video_features-13
Successfully started preferred replica election for partitions Set(video_features-12, video_features-13)重新查看topic状态,发现partition13的leader已经变为优先副本3了: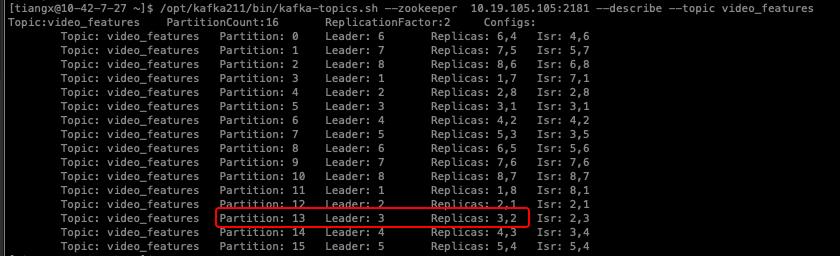
几个常用kafka集群问题排查命令:
# realtime-wh
## 查看leader分区是否为优先分区
/opt/kafka211/bin/kafka-topics.sh --zookeeper 10.19.23.215:2181 --describe --topic applog_raw
## 修复leader分区不是优先分区
/opt/kafka211/bin/kafka-preferred-replica-election.sh --zookeeper 10.19.23.215:2181 --path-to-json-file applog_e.json
其中:applog_e.json内容
"partitions":[
"partition":9,
"topic":"applog_e"
,
"partition":10,
"topic":"applog_e"
]
文件位置:
10.42.7.27/data/tiangx/applog_e.json
10.42.7.27/data/tiangx/applog_raw.json
以上是关于一次因为kafka分区的leader不为优先副本导致的消费堆积问题的原因排查及问题解决方法的主要内容,如果未能解决你的问题,请参考以下文章