STL:list
Posted 小键233
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STL:list相关的知识,希望对你有一定的参考价值。
STL 中的list 可以说是与vector 相对应的一个容器。
什么意思呢?
嗯,在我看来,vector 是线性表,空间连续,它的特点是原生指针作为它的迭代器,支持随机存取。但是插入和删除的操作代价高,并且有可能有一部分空间被浪费。
list 是链表,空间不连续,它的特点是对空间利用率高,插入和删除数据是常量时间,但是不支持随即存取,并且每个节点都需要浪费掉额外的两个指针的内存空间(不要忽视这点!)
注意,以上仅是个人的讨论,在数据结构中,线性表就是指抽象的连续数据的存储容器,实现一般分为数组和链表。
在三中讨论了vector 的实现,也说到STL 中的一些基础了,比如空间配置器、全局构造和析构函数、萃取技术、逆向迭代器等。这里就不再重复讲基础的东西,仅关注如何实现list
list_node 与 link_type
既然list 是链表,那么链表的节点肯定要定义一下的。
准确地说,list 是双向链表,它的节点有两个指针,一个指向后续节点,一个指向前驱节点。
于是,简洁明了的代码如下:
/** _list_node
*/
template<typename T>
struct _list_node
_list_node<T>* next;
_list_node<T>* prev;
T data;
;
以一个下划线开始的命名,表示仅在STL 的内部实现使用,不提供给客户使用(SGI 中的STL 是两个下划线开始)
SGI 中的STL 有点不一样,贴上代码:
template <class T>
struct __list_node
typedef void* void_pointer;
void_pointer next; //这里使用了void指针
void_pointer prev;
T data;
;它是用void* 来声明数据,我表示并不喜欢,就改成我实现的版本。
link_type 其实是一个typedef ,如下:
typedef _list_node<T> list_node;
typedef list_node* link_type;这个typedef 在list 类中。(typedef 大法好)
弄明白这个之后,就可以往下看了。
数据结构
前面说了,list 是双向链表,这个特性决定它可以很优美地定义自己的数据结构。
什么意思呢?
list 中仅有一个结点指针。
这很正常,链表都需要一个头指针。
然而,它将这个指针刻意指向一个空白的节点,这个节点表示链表的尾端。然后,它还是环状双向链表,所以尾端的next 指针指向链表的开头。
示意图如下:
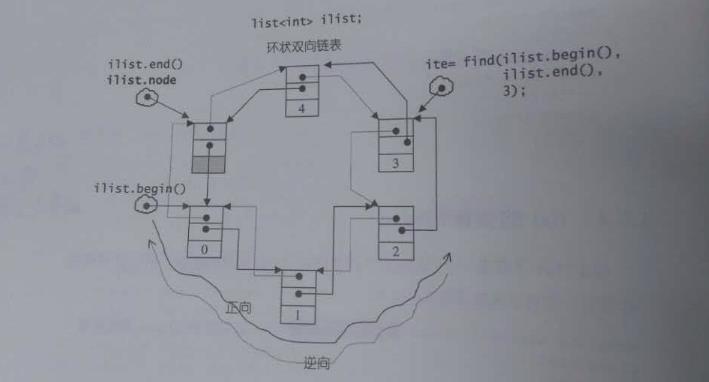
(图像来源:参考资料[1] )
在设计链表时,预先安排一个空白结点是常见的手法,这样能够简化很多操作。仔细体会list 的操作,就能够感受到它的威力了。
在list 之中,有这样的代码:
link_type node;
//...
iterator begin()
return node->next; //或者iterator(node.next)
iterator end()
return node;
迭代器
在list 中,数据的被包装在list_node 中,list_node的指针又被包装在迭代器中。
list 的数据操作仅支持双向移动,所以是双向迭代器(bidirectional iterator) 。
一开始不熟悉的时候,list_node 和link_type 老是被我搞混了。
在设计list 的迭代器的时候,应该谨记,不讨论迭代器的移动问题,迭代器的表现应该像一个原生指针。
迭代器的表现应该像一个原生指针。
迭代器的表现应该像一个原生指针。
有了信仰,那么可以实现了:
/** _list_iterator
*/
template<typename T, typename Ref, typename Ptr>
struct _list_iterator
typedef _list_iterator<T, T&, T*> iterator;
typedef _list_iterator<T, const T&, const T> const_iterator;
typedef _list_iterator<T, Ref, Ptr> self;
typedef T value_type;
typedef Ptr pointer;
typedef bidirectional_iterator_tag iterator_category;
typedef Ref reference;
typedef _list_node<T>* link_type;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
link_type node;
_list_iterator()
_list_iterator(link_type inn) : node(inn)
_list_iterator(const iterator& x): node(x.node)
bool operator == (const self& x) const return node == x.node;
bool operator != (const self& x) const return node != x.node;
reference operator * () const return node->data;
pointer operator -> () const return &(operator *() );
/** ++ -- operator
*/
self& operator ++ ()
node = node->next;
return *this;
self operator ++ (int)
self tmp(*this);
node = node->next;
return tmp;
self& operator -- ()
node = node->prev;
return *this;
self operator -- (int)
self tmp(*this);
node = node->prev;
return tmp;
;operator* 应该是获得data 的引用
operator -> 应该是针对data 的操作。什么意思呢?比如当data 是一个指针时,-> 应该是在data 的值上操作,而不是迭代器的node 上操作。
为什么需要三个模板参数?因为要满足iterator 向 const_iterator 的隐式转换。
在list 中这么定义迭代器:
template<typename T, typename Alloc>
class list
//...
typedef _list_iterator<T, T&, T*> iterator;
typedef _list_iterator<T, const T&, const T*> const_iterator;
//...
;在这样的情况下,以下代码是允许的:
iterator iter = begin();
const_iterator citer = iter; //发生隐式转换简直 Amazing,我第一次知道原来还可以这么玩,牛逼。
而原生指针本身就支持non-const 到 const 的隐式转换,所以,迭代器的设计也是要支持的。
关于逆向迭代器,在vector 中,已经说明了reverse_iterator 的设计,这里直接套用就好了:
typedef _reverse_iterator<iterator> reverse_iterator;
typedef _reverse_iterator<const_iterator> const_reverse_iterator;*const_reverse_iterator 也能向 reverse_iterator 隐式转换
虽然,list 的迭代器不支持opeartor + 和 operator - 的操作,但是却神奇地通过编译了。而且,即使通过萃取技术,拿到的也还是bidirectional_iterator_tag。
所以,只要我们不二逼地直接在reverse_iterator 上加减,就没有问题。(STL 提供了advance 函数进行迭代器的移动)
几个重要的protected member function
在直接开撸之前,先把几个重要的辅助函数写好。
事实证明,复杂问题可以通过几个简单的解合并到一起解决的。
get_node 与 put_node
get_node 是分配一个节点,而put_node 是解决一个节点(就是回收节点内存)
link_type get_node()
return list_node_alloc::allocate(1);
void put_node(link_type x)
list_node_alloc::deallocate(x);
create_node 与 destroy_node
create_node 是依据参数初始化一个节点,destroy_node 是销毁一个节点,在这个层面上讲,这个设计倒是和STL 中内存分配和对象构造分离异曲同工呀:
link_type create_node(const value_type& val)
link_type tmp = get_node();
XJ_TRY
construct(&tmp->data, val);
XJ_CATCH
put_node(tmp);
return tmp;
void destroy_node(link_type x)
destroy(&x->data);
put_node(x);
注意到,这里也是使用了异常处理。(貌似在对象的构造中会使用异常处理)
transfer
transfer 函数是将某连续范围的元素迁移到某个特定的位置之前,它为其它的公有函数实现打下了良好的基础:
/** transfer :将[first,last) 的元素移到pos 之前
*/
void transfer(const_iterator pos, const_iterator first, const_iterator last)
//先处理next
pos.node->prev->next = first.node;
first.node->prev->next = last.node;
last.node->prev->next = pos.node;
//再处理prev
link_type tmp = last.node->prev;
last.node->prev = first.node->prev;
first.node->prev = pos.node->prev;
pos.node->prev = tmp;
insert
逼逼了那么多,终于到开始实现接口的时候了。
insert 的插入操作直截了当。因为是链表,所以数据只能一个个的放进去。那么,其实只要把一个写好,其他的都写好了:
iterator insert(const_iterator pos, const value_type& val)
link_type tmp = create_node(val);
tmp->next = pos.node;
tmp->prev = pos.node->prev;
pos.node->prev->next = tmp;
pos.node->prev = tmp;
return tmp;
其他的insert 在上面这个基础上循环实现:
template<typename T, typename Alloc>
typename list<T, Alloc>::iterator list<T, Alloc>::insert(const_iterator pos, size_type n, const value_type& val)
iterator result;
while(n--)
result = insert(pos, val);
return result;
template<typename T, typename Alloc>
template<typename Input_iter>
typename list<T, Alloc>::iterator list<T,Alloc>::insert(const_iterator pos, Input_iter first, Input_iter last)
iterator result;
for(; first!=last; ++first)
result = insert(pos, *first);
return result;
erase
erase 和 insert 是一个德性,小心一点编写就可以了:
iterator erase(const_iterator pos)
link_type next_node = pos.node->next;
link_type prev_node = pos.node->prev;
next_node->prev = prev_node;
prev_node->next = next_node;
destroy_node(pos.node);
return iterator(next_node);
iterator erase(const_iterator first, const_iterator last)
while( first != last) erase(first++); //要先自增才能去erase!!
return iterator(last.node);
为什么说要小心一点呢,因为如果在循环的那句写成这样就会出bug:
for(; first!=last; ++first)
erase(first);仔细看迭代器的自增操作,当erase 之后,再自增,那么first 中node 的后继节点信息就失去了,还玩个卵。
merge
merge 是将两个list 的数据合并到一块去,前提是两个list 要先经过排序:
template<typename T,typename Alloc>
void list<T, Alloc>::merge(list<T, Alloc>& x)
iterator first1 = begin();
iterator last1 = end();
iterator first2 = x.begin();
iterator last2 = x.end();
while(first1!=last1 && first2 != last2 )
if(*first2 < *first1)
iterator next = first2;
transfer(first1, first2, ++next);
first2 = next;
else ++first1;
if(first2!=last2)
transfer( last1, first2, last2);
template<typename T, typename Alloc>
template<typename Compare>
void list<T, Alloc>::merge(list<T, Alloc>& x, Compare comp)
iterator first1 = begin();
iterator last1 = end();
iterator first2 = x.begin();
iterator last2 = x.end();
while(first1!=last1 && first2 != last2 )
if(comp(*first2 ,*first1) )
iterator next = first2;
transfer(first1, first2, ++next);
first2 = next;
else ++first1;
if(first2!=last2)
transfer( last1, first2, last2);
这个想法就是想合并排序一样,一个一个得将它们放到合适的位置,
but ,我想到说,找到一段连续的区间再操作,而不是一个一个操作,代码如下,仅供参考:
template<typename T, typename Alloc>
void list<T, Alloc>::merge(list<T, Alloc>& x)
iterator curr_first = x.begin();
iterator curr_last = curr_first;
iterator first = this->begin();
while(curr_last != x.end() && first!=end() )
while(first!=end() && *first<=*curr_first) ++first;
while(curr_last != x.end() && *curr_last<=*first) ++curr_last;
if(first !=end() )
transfer(first, curr_first, curr_last);
else break;
curr_first = curr_last;
if(curr_last != x.end() )
transfer(end() , curr_last, x.end() );
unique
unique 是将list 中连续的相同的数据去掉,只保留一个。
注意,是连续的,相同的。这意味着,先排序:)
template<typename T,typename Alloc>
void list<T, Alloc>::unique()
iterator first = begin();
iterator next = first;
++next;
while(next!=end() )
if(*first == *next)
erase(next++);
else ++first, ++next;
template<typename T,typename Alloc>
template<typename Binary_predicate>
void list<T, Alloc>::unique(Binary_predicate pred)
iterator first = begin();
iterator next = first;
++next;
while(next!=end() )
if( pred(*first, *next) )
erase(next++);
else ++first, ++next;
reverse
reverse 是反转链表的操作,面试经常问到的一个算法
template<typename T, typename Alloc>
void list<T, Alloc>::reverse()
link_type new_node = get_node();
new_node->next = new_node->prev = new_node;
iterator first = begin();
while(first!=end() )
link_type tmp = first.node;
++first;
new_node->next->prev = tmp;
tmp->next = new_node->next;
new_node->next = tmp;
tmp->prev = new_node;
put_node(node);
node = new_node;
以上是我自己是实现的,SGI 中的实现如下:
void list<T, Alloc>::reverse()
if (node->next == node || link_type(node->next)->next == node) return;
iterator first = begin();
++first;
while (first != end())
iterator old = first;
++first;
transfer(begin(), old, first);
哪个更好?当然是标准的,没有涉及到额外的空间分配。但我不喜欢transfer 操作,它涉及到太多结点的操作。
splice
splice 是将一个list 的数据分割到另一个list 中:
/** splice :将x 中的元素转移到this 中
@param pos :要插入的位置
*/
void splice(const_iterator pos, list& x)
if(!x.empty() )
transfer(pos, x.begin(), x.end() );
void splice(const_iterator pos, list&, iterator i)
iterator j(i);
++j;
if(pos == i || pos == j) return ;
transfer(pos, i, j);
void splice(const_iterator pos, list&, const_iterator first, const_iterator last)
if(first!=last)
transfer(pos, first, last);
sort
sort 函数是个难搞的东西。list 的sort 算法有点厉害。
先上代码,再看运算过程:
/** sort
非常神奇的算法
*/
template<typename T, typename Alloc>
void list<T, Alloc>::sort()
//size ==0 || size ==1
if( node->next == node || node->next->next == node) return ;
list<T, Alloc> carry;
list<T, Alloc> counter[64];
int fill = 0;
while(!empty() )
carry.splice(carry.begin(), *this, begin() );
int i=0;
while(i<fill && !counter[i].empty() )
counter[i].merge(carry);
carry.swap(counter[i++]);
carry.swap(counter[i]);
if(i==fill)
++fill;
for(int i=1;i<fill; ++i)
counter[i].merge(counter[i-1]);
this->swap(counter[fill-1]);
template<typename T, typename Alloc>
template<typename Compare>
void list<T, Alloc>::sort(Compare comp)
//size ==0 || size ==1
if( node->next == node || node->next->next == node) return ;
list<T, Alloc> carry;
list<T, Alloc> counter[64];
int fill = 0;
while(!empty() )
carry.splice(carry.begin(), *this, begin() );
int i=0;
while(i<fill && !counter[i].empty() )
counter[i].merge(carry, comp);
carry.swap(counter[i++]);
carry.swap(counter[i]);
if(i==fill)
++fill;
for(int i=1;i<fill; ++i)
counter[i].merge(counter[i-1],comp);
this->swap(counter[fill-1]);
假设,现在有数据如下:
51 83 45 8 26
sort 的算法思想就是,每一轮将数据排序好,存放到counter 中。
counter[i] 存到的数据大小null 或者 2^(i) 个。
即
counter[0] : 1
counter[1] : 2
//。。。carry 是每一轮数据的运输者,相当于给counter 传输数据的。
开始排序:
51 83 45 8 26
//1
counter[0] : 51;
counter[1] : null;
//2
counter[0] : null;
counter[1] : 51 83;
//3
counter[0] : 45;
counter[1] : 51 83;
//4
counter[0] : null;
counter[1] : null;
counter[2] : 8 45 51 83;
counter[3] : null;
//5
counter[0] : 26;
counter[1] : null;
counter[2] : 8 45 51 83;
counter[3] : null;
//6
//合并各个counter这就像玩2048 一样,一点一点地往上合并。
一开始我还很好奇为什么会定义常数64呢?
现在看来,2^64 次方已经足够进行排序了。
[1] 说这个排序是快速排序,但又有资料说这个排序是合并排序。
我一时间也分不清究竟是哪个排序。
但是,这个排序算法无疑是出色的,空间复杂度为1,时间复杂度O(n*ln n);
swap
swap 的编写,我之前专门写过一篇博客谈这个主题。在SGI 中,标准的做法就是这么做的。
定义一个成员swap 函数
/** swap
*/
void swap(list& x)
xj::swap(node,x.node);
全局swap 函数:
template<typename T, typename Alloc>
void swap(list<T, Alloc>& x, list<T, Alloc>& y)
x.swap(y);
–End–(我简直就是个话唠)
[参考资料]
[1] 侯捷. STL 源码剖析[M]. 华中科技大学出版社, 2002.
以上是关于STL:list的主要内容,如果未能解决你的问题,请参考以下文章