Spring循环依赖是如何解决的?
Posted lllllLiangjia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring循环依赖是如何解决的?相关的知识,希望对你有一定的参考价值。
目录
什么是循环依赖?
如图所示,A对象中的属性是B对象,并且B对象的属性也有A对象。循环依赖的A、B两个对象由于属性有彼此的存在,各自都想在创建时给属性赋值另外一个完整的对象,那这两个对象就一直处于创建阶段,一直循环下去。
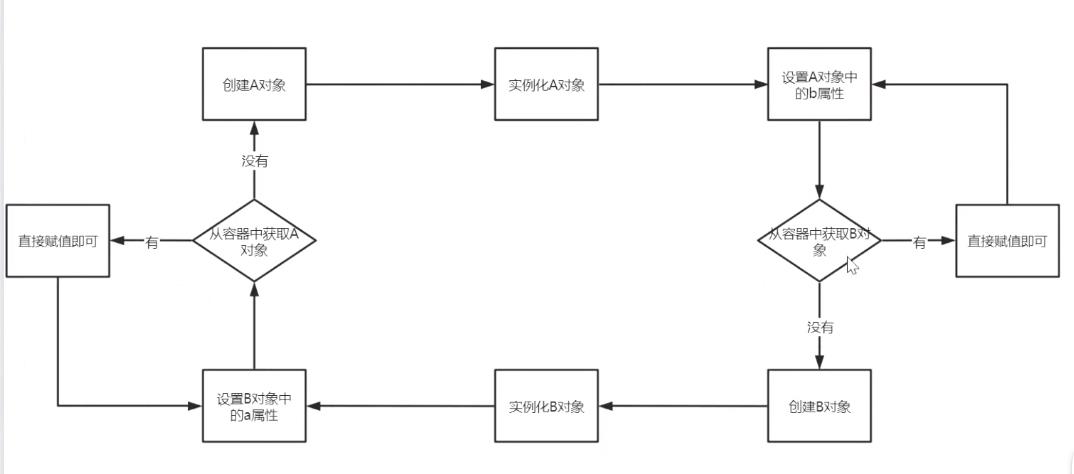
如何解决循环依赖问题?
如果IoC容器要创建对象,需要经过大体两个步骤实例化和初始化。实例化是创建一个半成品对象,经过初始化给对象属性赋值的操作,一个完整的对象才算创建完成。
spring通过提前暴露对象的方式(完成实例化但是没有初始化的对象)解决循环依赖问题。
如何提前暴露对象?
使用三个缓存。DefaultSingletonBeanRegistry类中的三个属性,这三个map集合就是缓存
/** Cache of singleton objects: bean name --> bean instance */
//一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
//三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name --> bean instance */
//二级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);为了后面说的方便我将singletonObjects 、singletonFactories、earlySingletonObjects 叫做一、三、二级缓存。你也可以用代码的顺序定义一、二、三。网上有的人将singletonFactories定为第二缓存,将earlySingletonObjects定为第三缓存。大家学习时不要因为这个问题纠结太多,明确指的是具体哪个map就好。
三级缓存中分别存放什么状态的对象?
singletonObjects :成品对象
earlySingletonObjects :半成品对象
singletonFactories :lambda表达式
创建bean的流程
此流程方法对应Spring源码中对应的方法

A、B循环依赖,说明大体流程:
- 先getBean、createBean一套流程下来,实例化完A半成品对象,然后将带有A为参数的工厂方法放在第三缓存中,之后给A半成品对象B属性赋值的时候,发现没有B对象。
- 便开始创建B对象,也是getBean、createBean一套流程下来,实例化完B半成品对象,然后将带有B为参数的工厂方法放在第三缓存中,之后给B半成品对象的A属性赋值的时候,发现没有A对象。
- 这时候开始doGetBean对象A,这时候在第三缓存中发现了带有A的工厂方法,执行该方法,获取到A的半成品,放到第二缓存中,清空第三缓存。将半成品对象A返回赋值给B半成品对象的属性,然后B实例化完,清空第三缓存,将完整的B对象添加到第一缓存中。
- 此时B对象现在能获取到,那就回到第一步,A的属性也赋值完成,清空第二缓存,将完整A对象添加到第一缓存中。
由于涉及的代码太多而且大多就是重复的,我只将重要的方法名写出来,想深入了解的可以按照对应的方法名去源码里找
在第三级缓存中lambda表达式
在doCreateBean方法中createBeanInstance后,在三级缓存放入初始化的对象 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));如果一级缓存没有beanName,那就清空二级缓存,放入到三级缓存中。
之后进入到populateBean方法调用applyPropertyValues方法,里面有for循环属性值,调用resolveValueIfNecessary将BeanDefinition进行解析为bean引用,走进resolveReference方法中又包含了getBean()方法
在第二级缓存中放入未初始化的半成品对象
在doGetBean方法中getSingleton方法得到三级缓存所对应的对象,执行getEarlyBeanReference(beanName, mbd, bean),得到的结果存入二级缓存中,移除三级缓存中beanName的键值对。
在第一级缓存中放入初始化后的完整对象
之后一直返回到createBean方法外,它被getSingleton方法利用lambod表达式调用,进入方法,再进入addSingleton方法,将beanName和SingletonObject的映射关系添加到一级缓存中,清空一二缓存。
从第一级缓存中获取对象
getBean,doGetBean方法中的getSingleton方法直接再一级缓存中获取对象返回。
三级缓存相关问题详解
如果只设置一级缓存能不能解决循环依赖问题?
如果只有一级缓存的话,那么一位置半成品和成品对象都要放到一级缓存中,那么就有可能获取到对象的非完整状态,此时不能使用,所以需要一级二级分别来存放不同状态的对象。
删除三级缓存可以不可以?
一级和二级缓存就可以解决循环依赖的问题,但是有前提,如果没有使用aop,不需要创建代理对象,那就可以。三级缓存是为了解决代理过程中产生新的对象的循环依赖问题
删除二级缓存可不可以?
如果是只有两个类之间进行相互依赖是可以去掉的,但是当出现一个类被多个类之间相互引用,那如果有二级缓存就可以省很多时间。
例如类A有属性B、C、D。类B属性中有A,类C属性中有A,类D属性中有A。
那类A的lambda加载到三级缓存后,开始实例化类B、类C和类D,当没有二级缓存时,类B、类C和类D每次需要引用类A的半成品,都需要执行lambda表达式方法,该方法执行时间长的话,这三个类分别进行引用,每次都需要重新执行。由于三级缓存是工厂,每次生成的对象不是同一个,导致B、C、D引用的是不同的A对象
当添加了aop之后,跟刚刚的处理步骤哪里不一样?
在doCreateBean方法中往三级缓存中存入的getEarlyBeanReference方法中是有可能把之前的原始对象替换成代理对象的,所以,此时会造成版本不一致的问题,也就是无法使用最终的版本。原来的原始对象没有引用了就会被垃圾回收。
总结:
每次我们在获取对象的时候,是通过对象的name来获取bean的,如果原始对象和代理对象同时存在的话,那么我通过你名字在获取的时候,应该用哪一个呢?无法选择,其实还有最核心的点,你怎么能够确认对象什么时候需要被引用呢?使用了lambda表达式其实表达了一种回调机制,当需要使用当前对象的时候,通过lambda表达式来最终返回一个确定的最终版本,而不需要判断有几个对象,因为是替换的过程,所以只可能有一个!!
getEarlyBeanReference()方法中实例化了SmartInstantiationAwareBeanPostProcessor接口的子类,然后又调用该类的getEarlyBeanReference()方法,此方法有两个实现类,一个就是直接返回原始对象的,一个是调用proxy接口创建一个新的对象。

以上是关于Spring循环依赖是如何解决的?的主要内容,如果未能解决你的问题,请参考以下文章