自然语言处理顶会 ACL 2018 参会见闻
Posted 机器之心V
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理顶会 ACL 2018 参会见闻相关的知识,希望对你有一定的参考价值。
关于作者:郑在翔,现为南京大学自然语言处理实验室二年级硕士生,将准备继续攻读自然语言处理方向的博士。当前主要研究方向为神经网络机器翻译。
作者在本文记录了自己在自然语言处理顶会 ACL 2018 的参会经历,从个人的角度出发,介绍了会议内外的内容、感兴趣的工作和研究热点,并简单叙述了其以论文作者身份第一次参加学术会议的一些感想。

2018 年 7 月 15 日至 20 日,自然语言处理领域的顶级会议 ACL 2018 在澳大利亚墨尔本举行。本次大会共收到了 1018 篇长文和 526 篇短文的提交,相比去年有显著的增长,在规模上是名副其实的学术界的盛会。其中,长文有 256 篇被录用,录用率为 25.1%;短文有 125 篇被录用,录用率为 23.8%;总体的录用率为 24.7%。
本次会议还是产业界的盛会,共得到了来自全世界 28 家赞助商的大力赞助。近些年来,来自中国的企业对人工智能领域学术会议的赞助热情和规模逐年上涨,ACL 2018 的主要赞助商中,有 7 家来自中国,如字节跳动(ByteDance)、百度、京东、腾讯等。其中字节跳动公司与 Apple、Google 等公司同为本届 ACL 的顶级赞助商,这也反应了中国企业和市场对于人工智能学术前沿和产业化应用的关注。
由于笔者有一篇发表在 TACL (Transaction of ACL)上的论文有机会在此次 ACL 展示,所以非常幸运地能来到墨尔本参加此次的大会。作为一个第一次参加学术会议的小白,笔者在墨尔本的这短短七天不仅经历了好多“第一次”,更得到了许许多多的收获。在会议期间,不仅有机会可以和来自世界各地优秀的研究者请教交流,还能近距离了解人工智能企业感兴趣的问题。笔者在此想结合自己的参会经历,和大家分享一下本次会议的见闻。
精彩的主会场
第一天是 Tutorial 环节。此次大会共设了 8 场 Tutorial,上午下午各 4 场。笔者参加了上午的Neural Approaches to Conversational AI 和下午的 Deep Reinforcement Learning for NLP。两个 Tutorial 深入浅出,非常精彩,并且都公开了报告的 slides。

▲ Williams Wang 老师在报告《Deep Reinforcement Learning for NLP》Tutorial
第二天日程由大会开幕式开始。在开幕式中,大会主席 Marti Hearst 宣布成立 AACL(The Asia-Pacific Chapter of the ACL)的决定,引发现场一片欢呼。区别于现有的针对于欧洲地区的 EACL(The European Chapter of the ACL)和北美地区的 NAACL(The North American Chapter of the Association for Computational Linguistics),此次成立的 AACL 会主要聚焦于亚太地区。
新成立的 AACL 委员会由亚太地区该领域具有影响力的学者组成。其中,AACL 委员会主席(Chair)是来自百度公司的王海峰,候任主席(Chair-Elect)是来自台湾资讯科学研究所的 Keh-Yih Su,秘书(Secretary)是来自清华大学的刘洋等。相信 AACL 的成立将会给亚太地区的自然语言处理的研究者又一个促进交流和学习的机会。

笔者在本次会议中看到,深度学习继续在自然语言处理的领域中发挥着重要作用。正式会议的上午和下午是 Oral 报告。笔者和大家一样,在各个不同 Track的会场奔波。Oral 的报告都非常有启发性,如来自 Google AI 的工作 The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation,通过将 RNN 的时序建模能力和 Transformer 中的“块”的概念及最新的训练技术结合起来,再次刷新了机器翻译上的最佳性能,同时也给笔者很大启发:虽然 Transformer 的提出使人们惊讶于 Self-Attention 赋予模型的性能,但是这不一定代表 RNN 的表达能力是弱于 Self-Attention 的;而在结合了 Transformer 中的一些最新的技术后,RNN 也表现出了更优越的性能,使人重新思考模型的表达能力与训练之间关系。

▲ Google AI 的论文报告
虽然笔者的研究方向主要是机器翻译,但也非常希望能从其他方向上的一些优秀论文也会中得到对自己研究的启发。例如来自 FAIR 的工作 What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties,通过采用探测(probing)的方法,试图“探测”出30个不同模型学到神经网络句子表示中究竟蕴含了什么,比如句子的长度信息和句法树的深度等,给下游任务的研究者对句子表示的理解提供了新的视角。
和 Oral 报告一样,在 Poster 环节中,笔者也更关注其他 NLP 方向的工作,希望能从其他得到启发。笔者看到本次会议有许多工作都开始探索基于 Self-Attention 的方法来建模文本中的句子表示和依赖关系。如来自 Berkeley 的工作 Constituency Parsing with a Self-Attention Encoder,通过引入 Transformer 中的 Self-Attention 机制,并且发现原本的 Self-Attention 机制中将内容信息和位置信息结合起来建模可能存在问题,提出了一种将内容和位置信息分解的方式,在成分句法分析(Constituency Parsing)上得到了 state-of-the-art 的性能。笔者还向作者询问了有关位置信息编码的问题,也得到了耐心的解答。
除此之外,笔者还发现,生成对抗网络和强化学习在很多工作中得到应用,这也表现了未来一段时间的研究热点和趋势。另外,研究如何将人类总结的知识和自然语言处理中的深度学习模型结合起来,向模型提供更多的先验知识的工作也在逐渐增多。
笔者有幸在此有一篇论文 Modeling Past and Future for Neural Machine Translation 作为 Poster 展示。这篇工作主要的动机是源于在通常的神经机器翻译的翻译结果中观察到的漏翻译和重复翻译现象。于是我们试图在解码阶段更显式地建模和学习到翻译的历史和未来信息的表示,希望能为当前一步翻译的注意力机制和单词预测提供更加丰富的目标端上下文,从而希望能避免翻译模型做出遗漏或者重复的决策。
由于是作为小白的笔者第一次在学术会议上做 Poster,并且需要使用英语,对口语不是很自信的我一度非常紧张。当天中午笔者连午饭都来不及吃,就匆匆守到了我们的展板,内心十分忐忑,担心自己不能很好地向对我们工作感兴趣的研究者解答他们的疑惑和表达自己的观点。
本文的共同第一作者、现在在字节跳动人工智能实验室工作的师兄看出了笔者的紧张,就向我介绍了他的经验。在实验设计和论文撰写时,师兄就提出了非常多有深度的见解,为这篇工作做出了主要贡献。在他的鼓励下,我的情绪得以稍稍缓解。当真正开始向源源不断过来的人讲解自己的工作的时候,笔者反而就忘记了紧张这回事了,投入到了和大家的交流过程中。面对各种各样的问题,笔者只好不停地“freestyle”。幸运的是,每个人都很有耐心地和我进行反复的讨论。通过和大家的交流,不仅收获了很多启发和建议,也锻炼了自己的表达和胆量,为自己积累了宝贵的经验。
此次会议评选出了 3 篇最佳长论文和 2 篇最佳短论文,共计 5 篇,并在闭幕式前进行报告。其中,最佳长论文为:
1. Finding syntax in human encephalography with beam search. John Hale, Chris Dyer, Adhiguna Kuncoro and Jonathan Brennan.
2. Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information. Sudha Rao and Hal Daumé III.
3. Let’s do it “again”: A First Computational Approach to Detecting Adverbial Presupposition Triggers. Andre Cianflone, Yulan Feng, Jad Kabbara and Jackie Chi Kit Cheung.
最佳短论文为:
1. Know What You Don’t Know: Unanswerable Questions for SQuAD. Pranav Rajpurkar, Robin Jia and Percy Liang
2. Lighter’ Can Still Be Dark: Modeling Comparative Color Descriptions. Olivia Winn and Smaranda Muresan
在闭幕式上,大会将 ACL 终身成就奖(Lifetime Achievement Award)颁发给了 University of Edinburgh 的 Mark Steedman 教授,感谢其对计算语言学、人工智能和认知科学作出的贡献。

▲ ACL终身成就奖获得者Mark Steedman教授
会场之外
在休息时走出报告的会场,可以看到有很多企业的展台,其中许多企业通过各种形式的 DEMO 来展示自己的技术和业务,让参会者们有机会了解到产业界的状况和关心的问题。 例如旗下有今日头条、抖音等产品的字节跳动(ByteDance)公司,他们以小明机器人(Xiaoming Bot) 为世界杯比赛自动写稿为例,展示了计算机视觉与自然语言处理技术的结合。其中,小明机器人首先通过基于计算机视觉的足球比赛理解技术能对视频中的球员、足球甚至人物的表情进行实时的追踪、分割和理解,而后结合自然语言处理技术自动生成图文并茂的新闻稿。
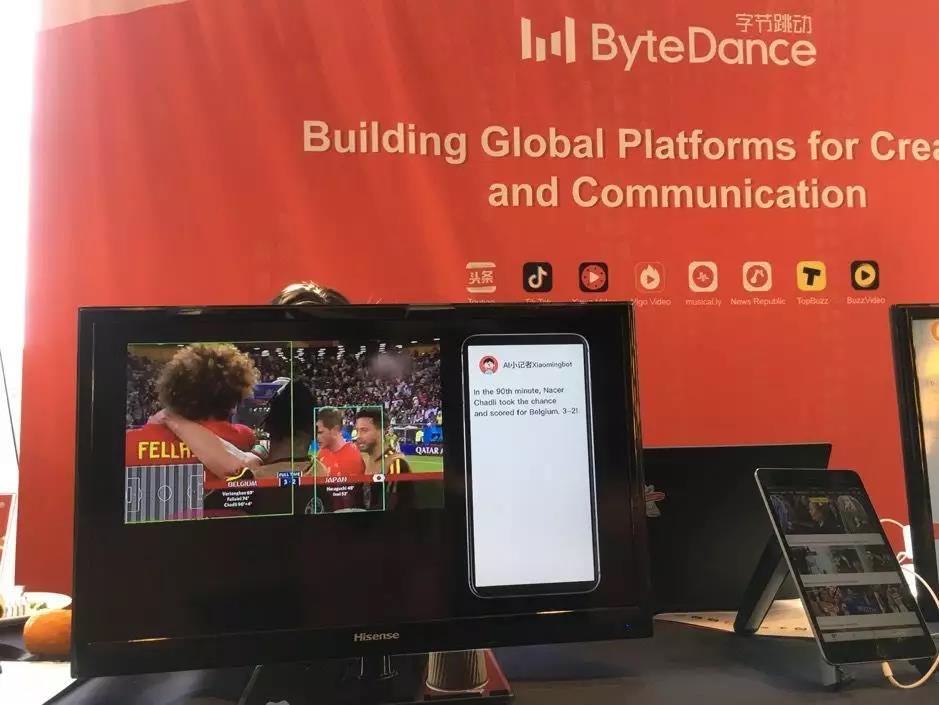
除此之外还看到相关人员在演示字节跳动支持多个语种的机器翻译系统。作为近些年来国内发展迅猛的 AI 企业,它的产品和机构也在积极地进行全球化运作。除了短视频软件抖音等在海外市场的惊人扩张外,它在美国硅谷、西雅图等地都设立了国际化的 AI 实验室,从而希望能招揽世界各地的行业精英。
笔者还有幸分别参加了百度公司和 CCF 青工委,以及字节跳动组织的晚宴。在百度公司和青工委组织的晚宴上,微软亚洲研究院副院长周明老师回顾了中国自然语言处理发展的历史,让我们这些晚辈对从那个年代的艰难起一路坚持走来的学术先行者们的敬意油然而生。展望未来,周明老师说:“在 NLP 的顶会上,中国和美国发表的论文数量很接近,我们下一步的目标,不光做更多的工作,还要做更好的工作,做更多有挑战的问题,为人类的文明作出贡献。”字节跳动晚宴邀请了很多国内外知名学者,李航老师现在在字节跳动人工智能实验室工作,这次晚宴是由他主持。从演讲了解到这是一个飞速发展的公司,在 NLP 领域已经有很多的应用,同时也正在招募更多技术人才加入他们。
除了在大会现场搭建展台和学者们交流外,笔者也看到多家中国企业,如阿里巴巴、百度、腾讯、京东、讯飞等,在主会场和最后两天的 Workshop 中积极展示来自企业的工作发表及研究成果。一段时间以来,这些 AI 相关的企业都在大力布局人工智能,通过对产业界中发现的实际问题进行研究和解决,表现出对前沿学术研究的空前热情,也使得学术界能更直接地了解到产业界关心的问题,对整个人工智能领域的健康发展起到了重要的作用。
写在最后
短短几日的 ACL 2018 之旅就要结束了,这几日经笔者历了无数的“第一次”:第一次参加学术会议,第一次在会议上作 Poster 展示,第一次鼓起勇气向 Christopher Manning 教授请教问题,第一次走在路上被墨尔本突如其来的冰雹袭击等。我感觉对我来说最大的收获除了各个学术上的报告外,就是学会倾听别人的想法和努力表达自己的想法。
相信很多小伙伴一开始的时候也向笔者一样,对自己的听力和表达不自信,担心无法和来自世界各地的研究者交流。但当笔者真正专注进这个事情,渴望就自己感兴趣的话题交换想法时,就发现这些都不再成为沟通的障碍了。在开会期间遇见了太多太多优秀的同龄人,他们对研究理解很深入,对问题的看法颇有远见,这也激励笔者要多多提高自己,努力向优秀的同龄人看齐。以上是笔者参加 ACL 2018 的一些见闻和浅薄的见解,希望自己将来也能做出有意义的工作,再次有机会和世界各地的学者交流。
入门 ACL 2018 NLP 1以上是关于自然语言处理顶会 ACL 2018 参会见闻的主要内容,如果未能解决你的问题,请参考以下文章
大会 | 自然语言处理顶会NAACL 2018最佳论文时间检验论文揭晓
2023计算机领域顶会(A类)以及ACL 2023自然语言处理(NLP)研究子方向领域汇总