赵雷的歌都讲的是什么
Posted 「已注销」
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了赵雷的歌都讲的是什么相关的知识,希望对你有一定的参考价值。
最近爬虫群里有一道面试题,《赵雷的歌都讲的什么》。
面试官为什么问这样的问题?他是怎么想的?他想通过这个问题考察我们哪些能力?
我尝试着做了这道题,有一些不同的收获,于是写出来分享给大家。
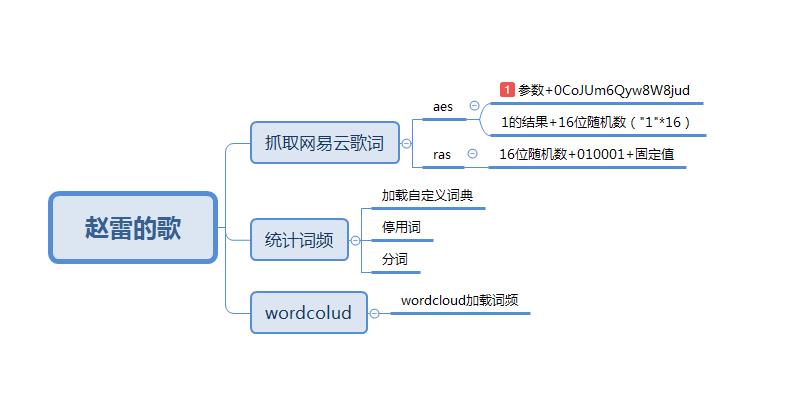
整体思路是抓取网易云关于赵雷的所有歌词,统计词频,最后显示出来。
阅读流程
- 效果展示
- 项目地址
- 核心代码
- 遇到的问题
- 总结
效果展示

项目地址
核心代码
- 反爬部分
def sign(data):
random = '1' * 16 # 随机数
text = json.dumps(data)
params = aes(text,'0CoJUm6Qyw8W8jud')#第一次加签
params = aes(params,random)#第二次加签
encSecKey = rsa(random.encode(),"010001",'00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7')
return 'params':params,
'encSecKey':encSecKey
-
统计词频部分
-
加载自定义词典
jieba.load_userdict("words.txt") -
加载停用词
with open('stop.txt',encoding='utf-8') as fr: stop_words = [word.strip()for word in fr.readlines() if word.strip()] -
统计
def cut_words(datas): words = for data in datas: for line in data.split('\\n'): tmps = jieba.cut(line) # print(stop_words,'==') tmps = [tmp for tmp in tmps if tmp.strip() and tmp.strip() not in stop_words] for word in tmps: words[word]=words.setdefault(word,1)+1 words = sorted(words.items(),key=lambda item:item[1],reverse=True) return dict(words)
-
-
云图显示
def gen_word_cloud(words): wordcloud = WordCloud(font_path='fonts/youyuan.TTF').generate_from_frequencies(words) plt.imshow(wordcloud) plt.axis("off") plt.show()
遇到的问题
- 网易云反爬
- 网易云的反爬类似快手的反爬,都是对参数进行两次aes加密,然后在对随机数进行rsa加密。
- js逆向的过程是一个套路
- 找到lyric地址,进行debug
- 查看调用栈,找到加密参数
- 不断debug,找到入参(原始参数),加密函数
- 重写
- jieba分词效果
- 需要不断的尝试,找出合适的自定义词典,然后才能更好的进行分词。
总结
面试官问这样的问题,他为什么这样问,他为什么这样思考,他想通过这个问题考察我们哪些能力?
相比于直接骂面试官sb,倒不如改变下我们的思考方式,认知方式。
认知三部曲
以上是关于赵雷的歌都讲的是什么的主要内容,如果未能解决你的问题,请参考以下文章