Java 集合类
Posted Shen_JC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合类相关的知识,希望对你有一定的参考价值。
类图
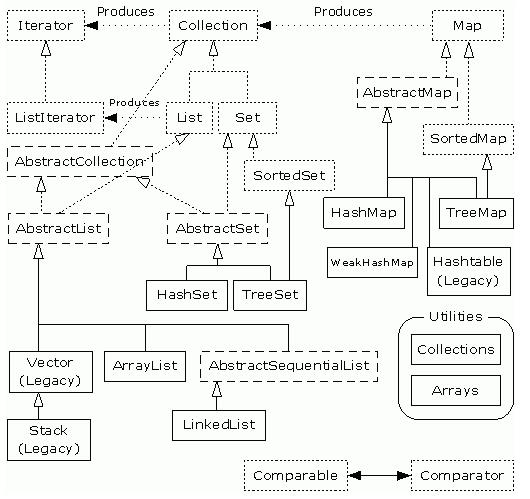
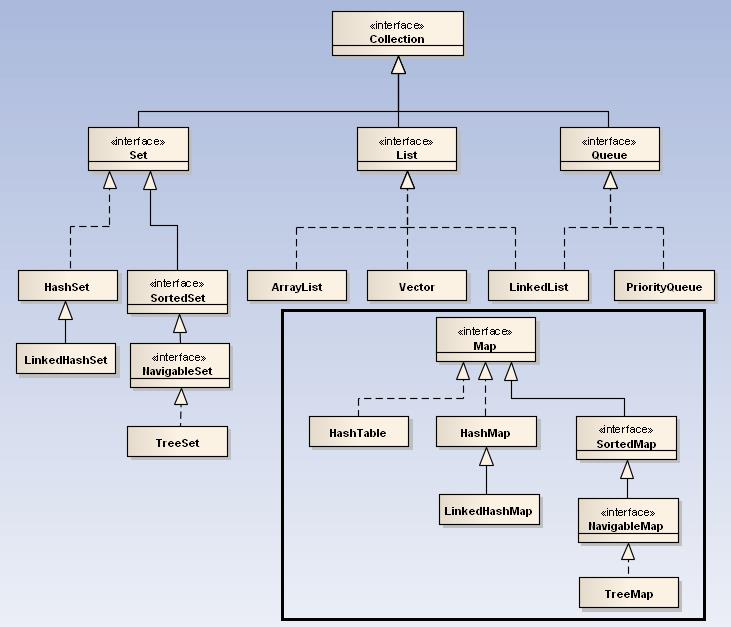
Collection接口
boolean add(Object o)
boolean addAll(Collection c)
boolean remove(Object o)
boolean removeAll(Collection c)去交集
boolean retainAll(Collection c)取交集
Iterator iterator()
Object[] toArray()
Object[] toArray(Object[] a)
Iterator接口
boolean hasNext()
Object next()
for(Iterator it=c.iterator();it.hasNext();)
Object o=it.next();
ListIterator接口
ListIterator是Iterator的子接口。
Iterator和ListIterator的区别
遍历方法 ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序身后遍历,但是ListIterator还有hasPrevious()和pervious()方法,可以实现逆向(顺序向前)遍历,Iterator就不可以。
遍历索引定位 ListIterator 可以定位索引位置——nextIndex()和previousIndex(),Iterator没有此功能。
增加集合对象元素方法 ListIterator有add方法,可以向List中添加对象,而Iterator不能。
对象维护 都可实现删除对象,但ListIterator可以调用set方法来对集合元素进行修改。而Iterator不能。
Map接口类型
Map接口用于将一个键(key)映射到一个值(value),且不允许有重复的键。
entrySet()的方法,这个方法返回一个实现Set接口的集合对象,集合中的每个对象元素又都实现了Map.Entry接口。Map.Entry接口提供了一个getKey()方法和一个getValue()方法。
keySet()方法,返回包含了所有keys的一个Set型集合。可以通过for、iterator来遍历。
values()方法,返回包含了所有values的Collection集合。可以通过for、iterator来遍历。
排序接口Comparable 和 Comparator
在Java中有两个接口来实现Comparable和Comparator,每一个对象都有一个必须实现的接口。分别是:
java.lang.Comparable: int compareTo(Object o1)
这个方法用于当前对象与o1对象做对比,返回int值,分别的意思是:
- positive – 当前对象大于o1
- zero – 当前对象等于o1
- negative – 当前对象小于o1
java.util.Comparator: int compare(Object o1, Objecto2)
这个方法用于o1与o2对象做对比,返回int值,分别的意思是:
- positive – o1大于o2
- zero – o1等于o2
- negative – o1小于o2
Comparable是排序接口;若一个类实现了Comparable接口,就意味着“该类支持排序”。
而Comparator是比较器;我们若需要控制某个类的次序,可以建立一个“该类的比较器”来进行排序。
我们不难发现:Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
List(有序、索引、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法。
- ArrayList(数组、快速访问)
ArrayList可以理解成一个可增长的数组,因此可以通过索引快速访问。
从ArrayList的add方法中可以看到,当ArrayList中的元素超过它的初始大小时,如果length < MIN_CAPACITY_INCREMENT / 2 时,ArrayList会把容量扩大到MIN_CAPACITY_INCREMENT ; 如果length >= MIN_CAPACITY_INCREMENT , ArrayList容量会增加50%。
if (s == a.length)
Object[] newArray = new Object[s +
(s < (MIN_CAPACITY_INCREMENT / 2) ?
MIN_CAPACITY_INCREMENT : s >> 1)];
System.arraycopy(a, 0, newArray, 0, s);
array = a = newArray;
LinkedList(链表、快速插入、删除)
LinkedList是双向链接的,拥有链表的快速插入和删除的特性Vector
ArrayList的线程安全版,但是性能较低。Vector的方法都是synchronized的,所以是线程安全的。当Vector中的元素超过它的初始大小时,Vector会将它的容量翻倍。Stack
Stack 继承自 Vector,实现了一个后进先出的堆栈。Stack 提供 5 个额外的方法使得 Vector 得以被当作堆栈使用。除了基本的 Push 和 Pop 方法,还有 Peek 方法得到栈顶的元素,Empty 方法测试堆栈是否为空,Search 方法检测一个元素在堆栈中的位置。注意,Stack 刚创建后是空栈。
Set(唯一、无序)
HashSet
HashSet是通过HashMap实现的,Set使用了Map中的key,因此Set具有唯一性。而HashMap中通过HashCode和 equals方法来确保唯一。 HashSet的contains和remove依据都是hashCode方法,如果该方法返回值相同,才判断 equals方法。TreeSet
TreeSet是通过TreeMap实现的,TreeMap实现了SortedMap,具有排序功能。
Map(键值对、键唯一)
Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复。
HashMap
Hashmap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为NullHashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空,同时效率较低。LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时 用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。TreeMap
TreeMap实现SortMap接口,二叉树结构。能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。
一般情况下,我们用的最多的是HashMap, HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现。
集合类的选择
- 是否有线程安全问题
- 集合类的元素数量是否很大(很大应该选择Hash开头的类,便于快速检索)
- 哪种集合类的结构方便当前使用
工具类
Collections类
CollectionUtils类
由Apache的commons-collections提供。
参考
Java集合类学习
java集合类框架
Java排序: Comparator vs Comparable 入门
以上是关于Java 集合类的主要内容,如果未能解决你的问题,请参考以下文章