MySQL进阶实战4,那些年学过的索引,下篇
Posted 哪 吒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL进阶实战4,那些年学过的索引,下篇相关的知识,希望对你有一定的参考价值。
目录
一、索引合并策略
1、当出现服务器对多个索引做相交操作时(通常有多个and条件),通常意味着需要一个包含所有相关列的多列索引,而不是多个独立的单列索引。
2、当服务器需要对多个索引做联合操作时(通常有多个or条件),通常需要耗费大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回的大量数据的时候。
索引合并看似是一种优化,实际上更多时候说明了表上的索引建的很糟糕。
二、选择合适的索引列顺序
在一个多列的B-Tree索引中,索引列的顺序意味着索引首选按照最左列进行排序,其次是第二列…
索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的order by、group by、distinct等子句的查询需求,多列索引的顺序至关重要。
以为的经验法则来看,将选择性最高的列放到索引的最左列,依次排开。这可以吗?当不需要考虑排序和分组的情况下,这样是没啥问题的,这时候索引的作用只是用来优化where子句,这样设计的索引确实能够最快的过滤出需要的行,对于在where子句中只使用索引部分前缀列的查询来说选择性也更高。
然而,性能不只是依赖于所有索引列的选择性,也和查询条件的具体值有关,也就是和值的分布有关。可能需要根据运行频率最高的查询来调整索引的顺序,让这种情况下的选择性更高。
三、聚簇索引
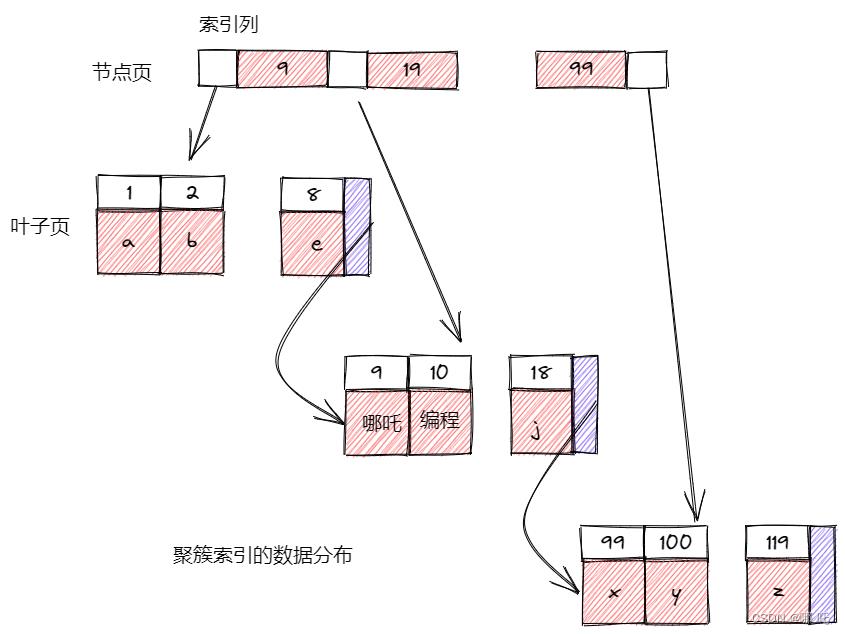
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式,但InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中。术语“聚簇”表示数据行和相邻的键值紧凑地存储在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
因为是存储引擎负责实现索引,因此不是所有的存储引擎都支持聚簇索引。
叶子页包含了行的全部数据,节点页只包含索引列,索引列包含的是整数值。
InnoDB通过主键聚集数据,也就是主键列,如果没有主键,InnoDB会选择一个唯一的非空索引代替,如果没有这样的索引,InnoDB会隐式的定义一个主键来作为聚簇索引。
四、聚簇索引的优缺点
1、优点
- 可以把相关数据保存在一起,例如实现电子邮箱时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘IO;
- 数据访问更快。聚簇索引将索引和数据保存在同一个B-Tree中,因此从聚簇索引中获取数据通常比在非聚簇索引中查找要快;
- 使用覆盖索引扫描的查询可以直接使用节点页中的主键值。
2、缺点
- 聚簇索引最大限度的提高了IO密集型应用的性能,但如果数据全部都放在了内存中,则访问的顺序就没有那么重要了,聚簇索引也就没什么优势了;
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键的顺序加载数据,那么在加载完成后最好使用optimize table命令重新组织一下表;
- 更新聚簇索引的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置;
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂”的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作。页分裂会导致表占用更多的磁盘空间;
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候;
- 二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列;
- 二级索引访问需要两次索引查找,而不是一次;
二级索引查找时,需要找到二级索引的叶子节点中存放的主键值,然后到聚簇索引中查找对应的行,所以是两次索引查找,在InnoDB中,可以通过自适应哈希索引减少这样的重复工作。
五、覆盖索引
如果一个索引包含所有需要查询的字段的值,我们就称之为覆盖索引。
六、覆盖索引的优点
- 索引条目通常远小于数据行大小,如果只需要读取索引,那么mysql就会极大地减少数据访问量。这对缓存的负载非常重要,这种情况下响应时间大部分花费在数据拷贝上。覆盖索引对于IO密集型的应用也有帮助,因为索引比数据更小,更容易放入内存中。
- 索引是按照列值顺序存储的,所以对IO密集型的范围查询会比随机从磁盘读取数据的IO少的多。
- 一些存储引擎如MyISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用。这可能会导致严重的性能问题。
- 由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用,InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询。
在发起一个覆盖索引查询时,在explain的Extra列可以看到“Using index”的信息。
七、冗余和重复索引
重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引,优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。应避免这样建索引,发现之后,应立即移除。
冗余索引和重复索引有一些不同,如果创建了索引(A,B),再创建索引(A)就是冗余索引,因为这只是前一个索引的前缀索引,这就是冗余索引。
冗余索引通常发生在未表添加新索引的时候,应该尽量扩展已有的索引而不是创建新索引。
MySQL进阶实战系列文章
哪吒精品系列文章

以上是关于MySQL进阶实战4,那些年学过的索引,下篇的主要内容,如果未能解决你的问题,请参考以下文章