iText7高级教程之html2pdf——4.使用pdfHTML创建报告
Posted CuteXiaoKe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了iText7高级教程之html2pdf——4.使用pdfHTML创建报告相关的知识,希望对你有一定的参考价值。
作者:CuteXiaoKe
微信公众号:CuteXiaoKe
{kind=link}
大致来说,使用iText创建PDF文档有三种主要方式:
- 你可以使用iText对象从头开始创建PDF文档,如
Paragraph、Table、Cell、List……这种方法的优点是,所有内容都是可编程的,因此可以按你想要的方式进行配置。缺点是需要对所有内容进行编程;即使是很小的更改,如将一种颜色更改为另一种颜色,也需要开发人员更改应用程序的Java代码、重新编译代码等。 - 你可以填写一个预先存在的表单。一方面,有AcroForm技术,它既快速又简单,但不是动态的(所有字段都有固定的位置)。另一方面,您有XML表单体系结构(XFA),它是动态的,填写表单很容易,但表单创建很复杂,而且XFA自PDF 2.0以来已被弃用。
- 你可以使用pdfhtml将HTML和CSS转换为PDF。这很容易,因为每个人都知道一些HTML,每个人都了解一些CSS。为什么要在另一个(其他专有)格式中创建模板,我们只需在HTML中创建内容,然后使用CSS以定义样式,将该内容转换为带有pdfHTML的PDF。
本教程讨论了第三种方法,当你创建特定类型的文档(例如目录、发票、清单等)时,这种方法非常理想和实用的。
1. 用例描述
假设你是为不同客户创建发票/清单的服务提供商。所有这些发票/清单都有一个相似的结构,无论客户是谁,但每个客户都希望您使用不同的字体、不同的颜色、不同的布局。如果使用第一种方法,每次新客户注册时都必须编写Java代码。如果使用第二种方法,您会发现您很快就会发现PDF中现有表单技术的局限性。如果使用pdfHTML,你可以构建一个需要最少编程的系统,并且不需要花费太多精力来注册新客户。
当新客户注册时,你需要:
- 一种快速获取数据的方式,它可以很容易地用于填充HTML;
- 要以CSS文件的形式获取字体、颜色、布局等信息;
- 获取一个可作为公司信纸的单页PDF文档。
在本章中,我们将使用XML文件movies.xml,包含将使用不同XSLT转换以不同方式呈现的数据。
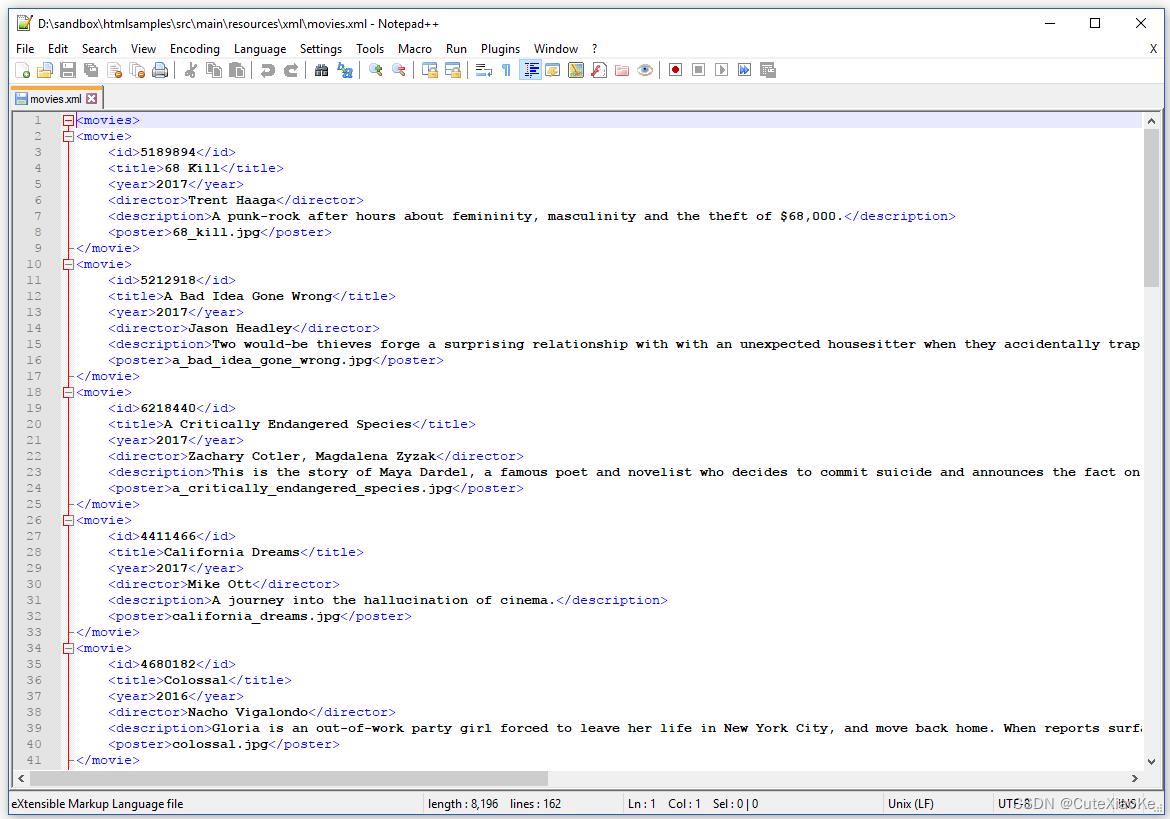
图4.1显示了这个XML文件的根元素叫做<movies>,XML文件由一系列<movie>标签组成,这些标签包含关于电影的信息,例如IMDB id(<id>)、标题(<title>)、电影制作年份(<year>)、导演(<director>)、描述(<description>)和电影海报的文件名(<poster>)。
我们将在本章中的所有示例中使用此XML文件,但生成的PDF将完全不同。
2. 使用XSLT将XML转换为HTML
在第一个系列的示例中,我们将使用XSL转换,将XML转换为包含一个大表的HTML文件。
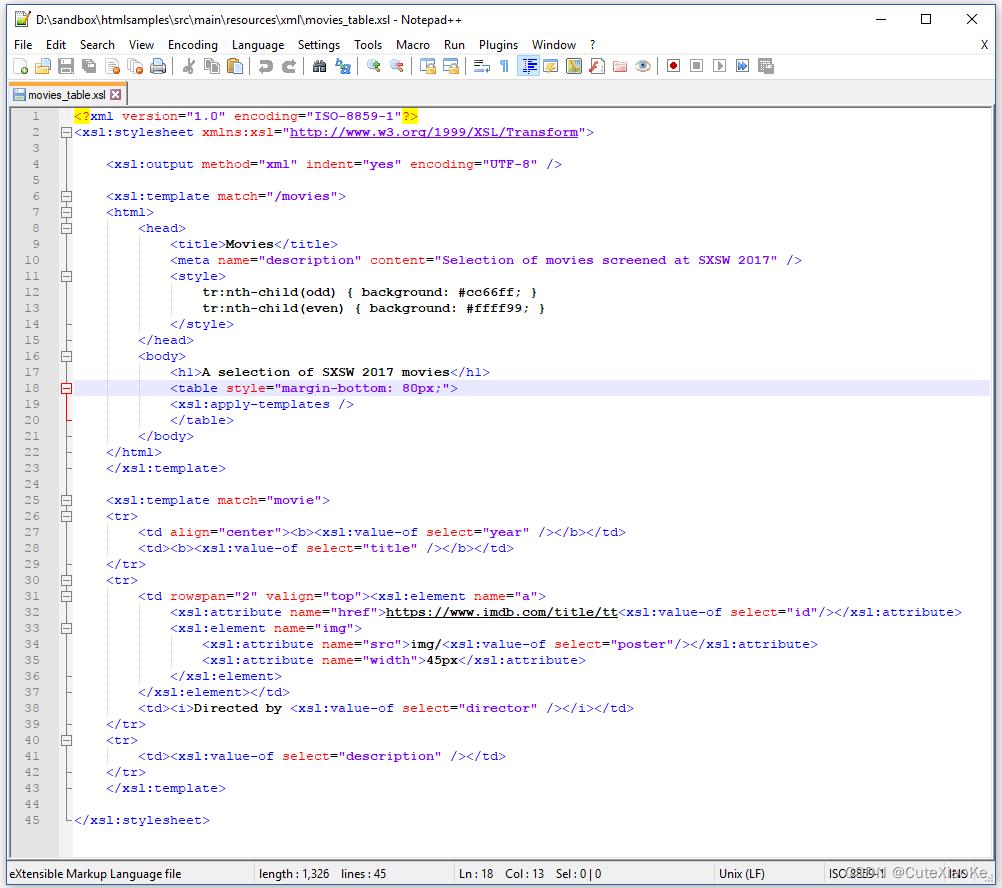
当我们查阅图4.2中movies_table.xsl代码时,可以看出与<movies>根元素匹配的HTML页面的结构。我们定义了一个<table>对象,并使用apply-templates,在这种情况下,它将为每个<movie>标签生成三行表格数据。这些行将填充对应的电影数据。
这一次我们不使用任何外部CSS,但有一些内部CSS,在其中为行定义伪类。每个奇数行(tr:nth-child(odd))将有#cc66ff作为背景色;每个偶数行(tr:nth-child(even))将有#ffff99作为背景色。
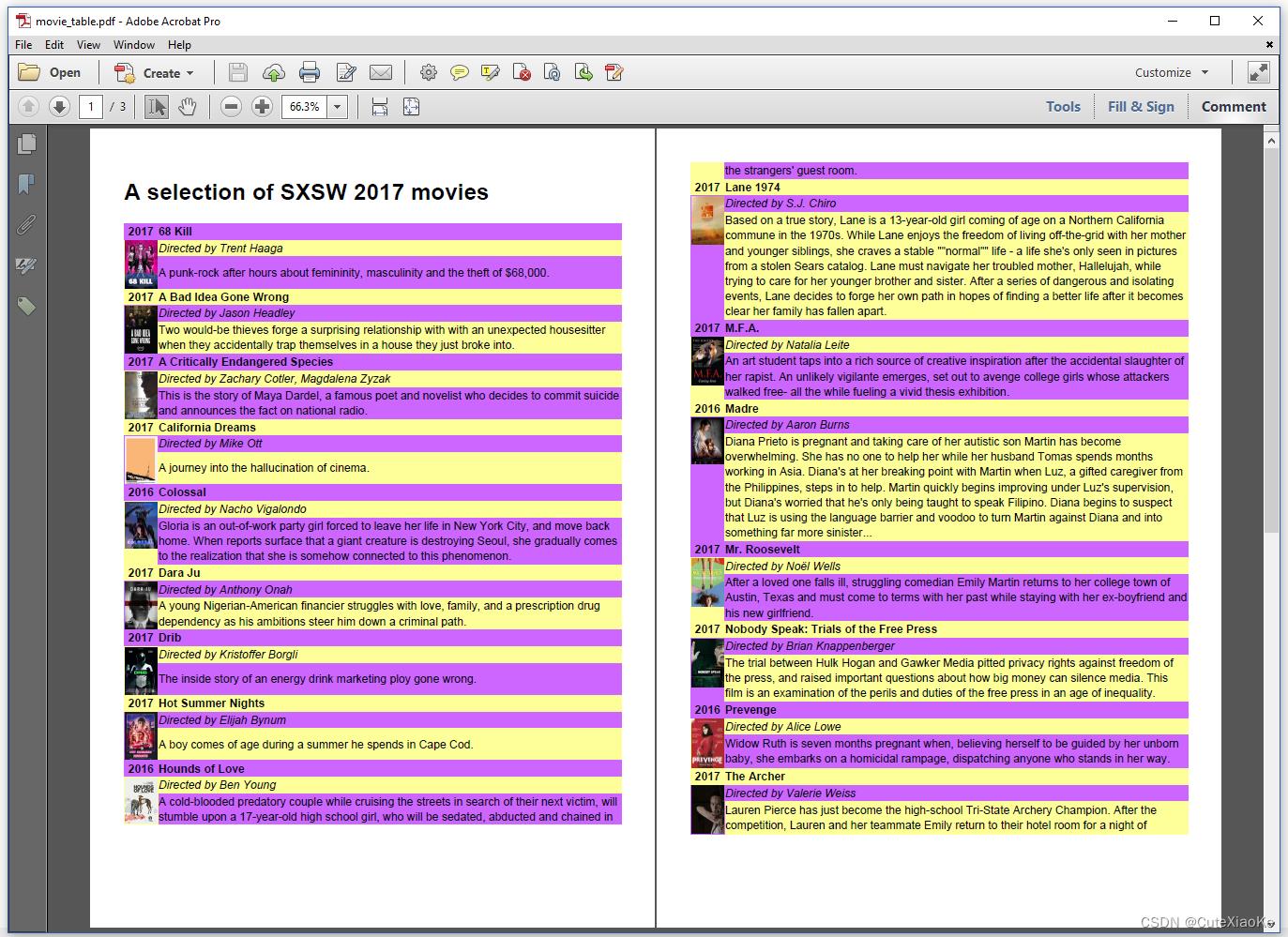
结果如图4.3所示,非常丰富多彩——当然颜色很花哈,如果伤到眼睛,请见谅。
我们使用下述代码的createPdf()方法:
app.createPdf(app.createHtml(XML, XSL), BASEURI, DEST);
这次我们不将转换后的HTML存储在磁盘上,而是在内存中创建HTML文件:
public byte[] createHtml(String xmlPath, String xslPath)
throws IOException, TransformerException
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Writer writer = new OutputStreamWriter(baos);
StreamSource xml = new StreamSource(new File(xmlPath));
StreamSource xsl = new StreamSource(new File(xslPath));
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer(xsl);
transformer.transform(xml, new StreamResult(writer));
writer.flush();
writer.close();
return baos.toByteArray();
然后传递html字节:
public void createPdf(byte[] html, String baseUri, String dest) throws IOException
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(
new ByteArrayInputStream(html), new FileOutputStream(dest), properties);
然后使用ConverterProperties,以便可以解析到图像的链接。
我们将在本章的所有其他示例中重用createHtml()/CreateHtmlBytes()方法。例如,在下一个示例中,我们将介绍公司信纸作为背景图像。
3. 添加背景和自定义页眉或页脚
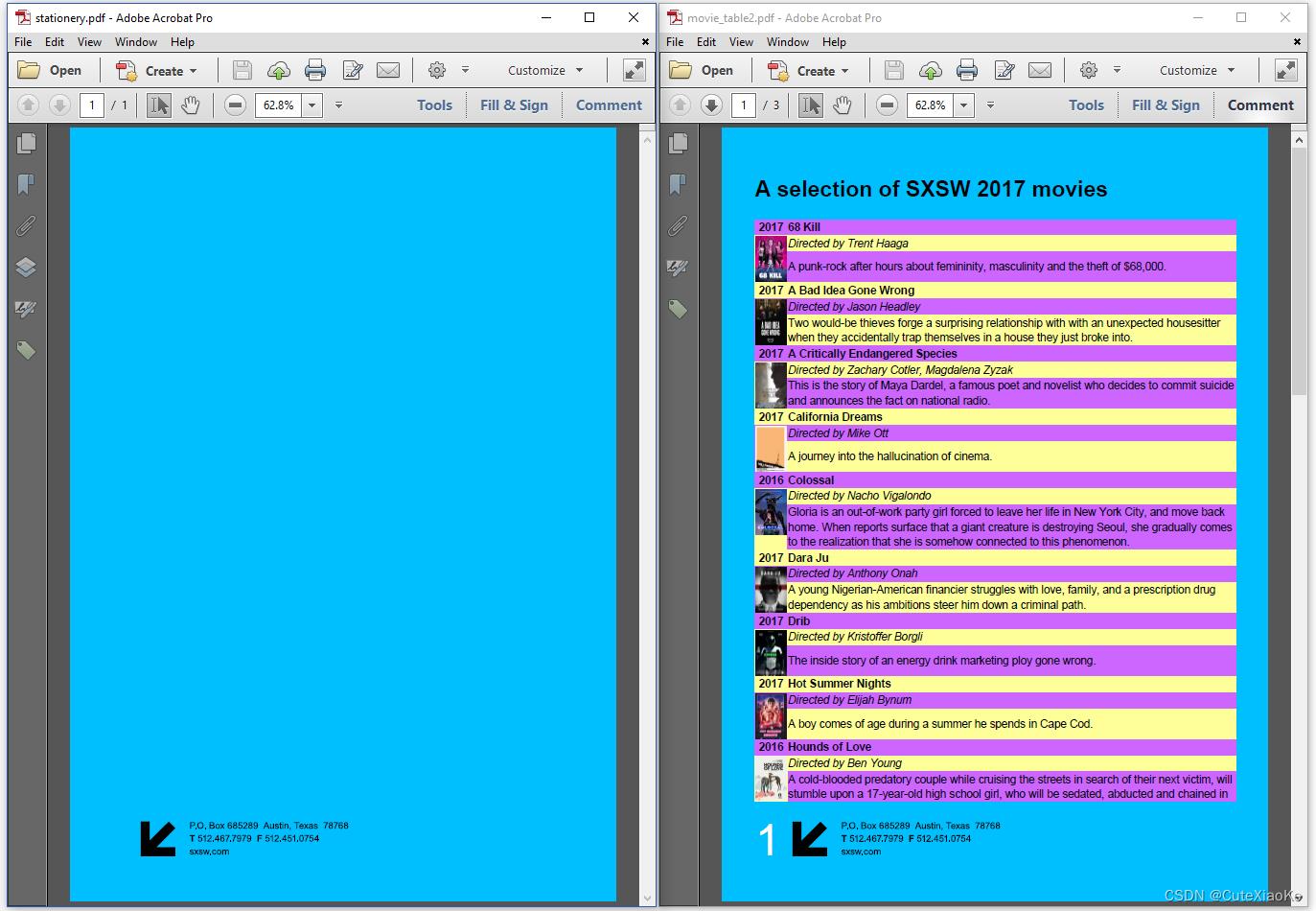
假设有一个可以用作公司信纸的单页PDF文档,请参见图4.4中左侧的PDF。假设我们想在从HTML创建的PDF的背景中添加此单页,请参见右侧的PDF。假设我们还想不用以 @page规则的方式添加页码。例如,请参见生成的PDF第一页上的白色大数字1。
iText7高级教程之构建基础块——7.处理事件,设置阅读器首选项和打印属性里面阐释的方法可以帮我们满足这个需求,你可看通过使用事件处理器来做到。
在下面的代码中,我们创建了IEventHandler的实现,名叫Background:
class Background implements IEventHandler
PdfXObject stationery;
public Background(PdfDocument pdf, String src) throws IOException
PdfDocument template = new PdfDocument(new PdfReader(src));
PdfPage page = template.getPage(1);
stationery = page.copyAsFormXObject(pdf);
template.close();
@Override
public void handleEvent(Event event)
PdfDocumentEvent docEvent = (PdfDocumentEvent) event;
PdfDocument pdf = docEvent.getDocument();
PdfPage page = docEvent.getPage();
PdfCanvas pdfCanvas = new PdfCanvas(
page.newContentStreamBefore(), page.getResources(), pdf);
pdfCanvas.addXObject(stationery, 0, 0);
Rectangle rect = new Rectangle(36, 32, 36, 64);
Canvas canvas = new Canvas(pdfCanvas, pdf, rect);
canvas.add(
new Paragraph(String.valueOf(pdf.getNumberOfPages()))
.setFontSize(48).setFontColor(Color.WHITE));
canvas.close();
我们可以使用以下参数(第4行)创建Background类的实例:
- 我们正在创建的文档的
PdfDocument类的实例:pdf; - 指向单页PDF源的路径:
src。
在这个构造函数中,我们将单页PDF读入到另一个名为template的PdfDocument实例。得到这个模板的第一页,然后将这个页面作为FormXObject复制到pdf实例中。此窗体XObject存储为成员变量,即信纸。最后,我们关闭模板。
当一个事件被触发时,该事件由handleEvent()/HandleEvent()方法处理,我们重写覆盖了该方法。得到当前PDF文档中当前页面的PdfCanvas对象。我们希望在页面上绘制任何其他内容之前访问画布。这就是newContentStreamBefore()/NewContentStreamBefore()的作用。我们在坐标[x=0,y=0]处将Form XObject对象stationery添加到页面。addXObject()方法将我们在构造函数中导入的单个页面添加到当前页面作为其背景。
要添加页码,我们首先定义一个位置,然后使用低级API PdfCanvas实例创建一个高级 API Canvas对象。在此画布中,我们将当前页数添加为Paragraph,字体大小为48pt,文本颜色为白色。
何时触发此事件?这在createPdf()方法中定义:
public void createPdf(byte[] html, String baseUri, String stationery, String dest)
throws IOException
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
IEventHandler handler = new Background(pdf, stationery);
pdf.addEventHandler(PdfDocumentEvent.START_PAGE, handler);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
我们创建一个名为handler的Background类实例。我们使用addEventHandler()/AddEventHandle()方法将此实例添加到PdfDocument中。使用PdfDocumentEvent.START_PAGE参数,我们指出每次页面启动时都需要调用handleEvent()/HandleEvent()方法。在这种情况下,该方法将被调用三次,因为内容分布在三个页面上。
如果我们在浏览器中查看HTML文件,我们会看到一个很长的页面。当我们将相同的内容呈现为页面大小为A4的PDF时,我们有三个页面。但如果我们想将所有内容放在一个PDF页面上呢?
例如:一些公司运行一个cron定时作业,它每小时、每天、每月对特定网页进行快照。他们不需要打印这一页,只需要一个档案,让他们知道哪些内容在特定的一天、特定的时间上线。
如何确保PDF始终由一页组成,其大小与内容的大小相适应?
4. 将HTML页面转换为单页PDF
如图4.5显示了我们在8.26 x 26.29英寸长的一页上用于前面示例的相同内容。
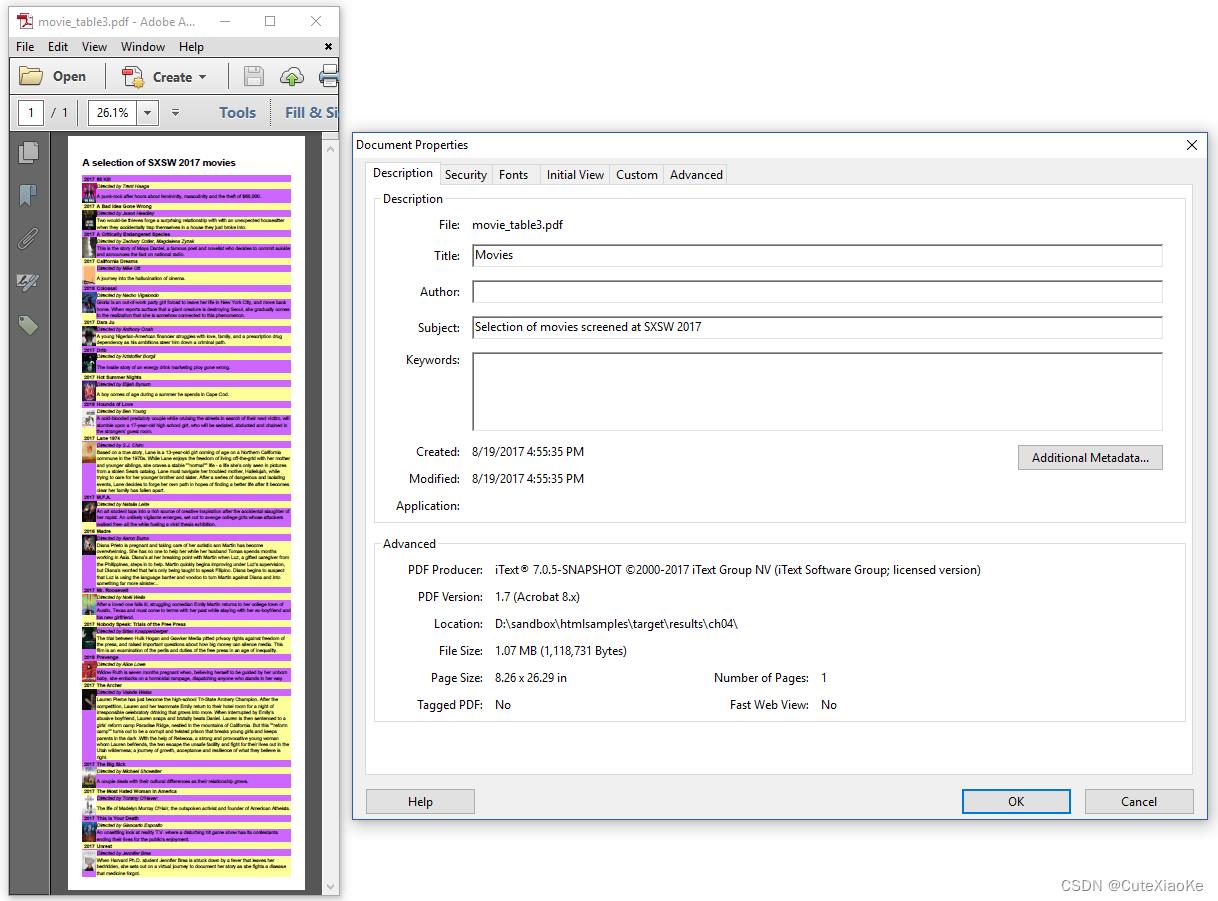
我们自己选择了文档的宽度——它是A4页的宽度。但是我们如何确定页面的长度呢?
我们无法提前确定长度,因为只有所有内容渲染后才知道总高度。在下面的例子中,我们创建了一个初始页面大小为595 x 14400用户单位的PDF。
14400个用户单元的高度不是任意选择的;这是Adobe Acrobat和Adobe Reader的实现限制。您可以创建宽度或高度大于14400个用户单位的页面大小的PDF,但Adobe Reader无法呈现它。你只会看到一页空白。
我们将使用convertToDocument()/ConvertToDocument()方法创建一个Document实例。然后将使用一个技巧来获得渲染内容后的结束位置。最后我们将更改页面大小,使其缩小到内容的大小。
createPdf()/CreatePdf()方法的代码向我们展示了这是如何完成的。
public void createPdf(byte[] html, String baseUri, String dest)
throws IOException
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
pdf.setDefaultPageSize(new PageSize(595, 14400));
Document document = HtmlConverter.convertToDocument(
new ByteArrayInputStream(html), pdf, properties);
EndPosition endPosition = new EndPosition();
LineSeparator separator = new LineSeparator(endPosition);
document.add(separator);
document.getRenderer().close();
PdfPage page = pdf.getPage(1);
float y = endPosition.getY() - 36;
page.setMediaBox(new Rectangle(0, y, 595, 14400 - y));
document.close();
上面的代码中我们设置了很大的的页面大小,并将HTML转换为Document实例,接着创建了EndPosition类的实例。然后将此实例传递给LineSeparator,并将此分隔符添加到Document。这将导致呈现所有内容,包括行分隔符。
我们得到第一页的页面对象,假设这是文档中的唯一页面。只要所需空间低于14400,这将是正确的。
最后,我们得到结束位置的Y值,并使用该Y值更改第一页的页面大小。更改此页面大小后,我们关闭文档。
这里发生了什么?我们添加了一个LineSeparator,但当我们查看生成的PDF时,我们看不到任何一行。这是因为我们创建了一个不绘制任何内容的ILineDrawer实现。相反,我们使用ILineDrawer来获取内容结尾的Y坐标。
让我们看看EndPosition类,它是如何工作的:
class EndPosition implements ILineDrawer
protected float y;
public float getY()
return y;
@Override
public void draw(PdfCanvas pdfCanvas, Rectangle rect)
this.y = rect.getY();
@Override
public Color getColor()
return null;
@Override
public float getLineWidth()
return 0;
@Override
public void setColor(Color color)
@Override
public void setLineWidth(float lineWidth)
我们重写了ILineDrawer接口的所有方法,但只有一个方法对我们很重要:draw()/Draw()方法。此方法为我们提供了一个Rectangle 实例,该实例在要渲染LineSeparator时标记光标在PDF中的当前位置。我们在这个位置没有画任何东西。相反,我们检索Y坐标并存储在成员变量中。在LineSeparator被“渲染”之后,我们可以使用getY()/GetY()方法检索这个Y位置。
在下一个示例中,我们将使用一个不同的XSLT文件来创建数据的不同视图。我们还将介绍书签。
5. 向报告添加书签
如图4.6显示了一个PDF,其内容与我们之前的相同,但呈现方式略有不同,因为我们现在使用movies_overview.xsl文件将XML转换为HTML。
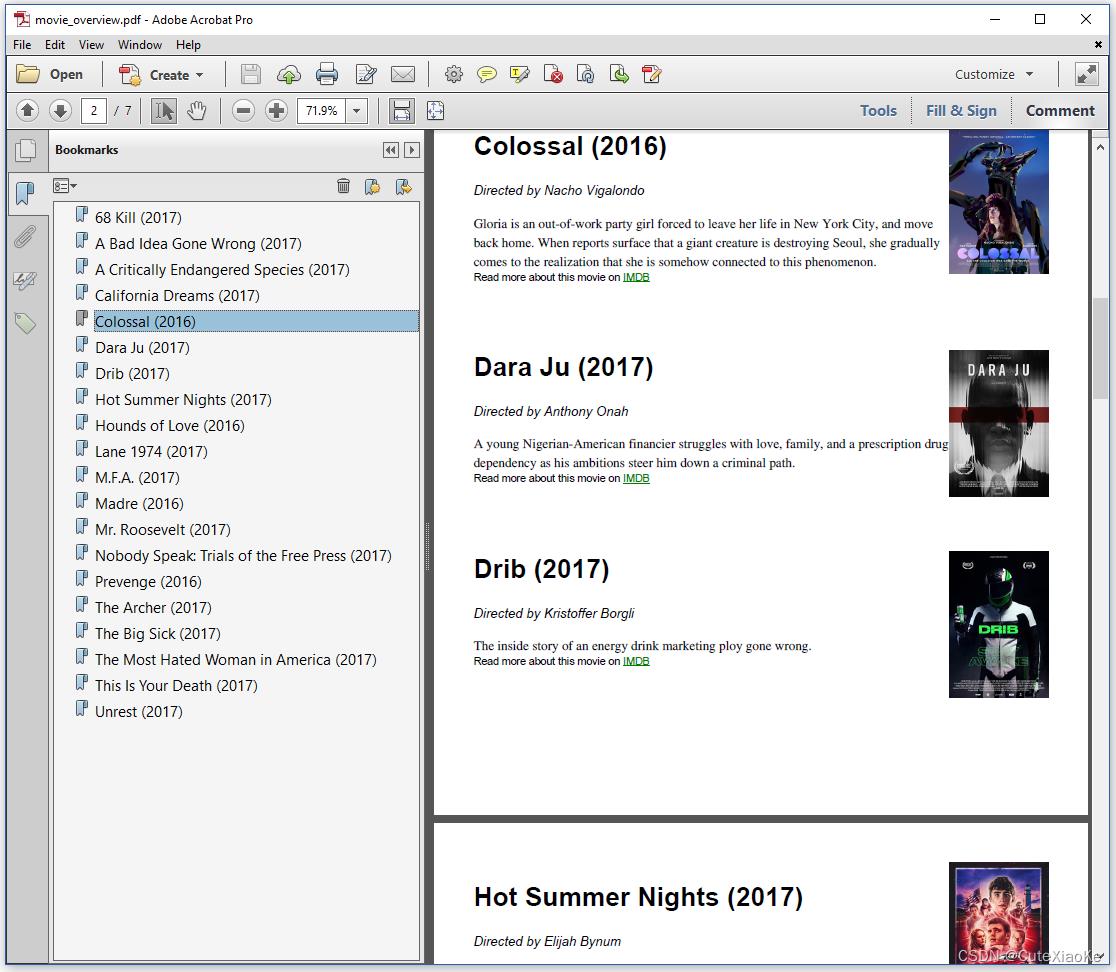
请注意,生成的PDF文档有书签。当我们点击电影的标题时,我们会跳转到文档中的位置,在那里我们可以找到关于这部电影的更多信息。
下面的java代码展示了怎么添加这些书签。
public void createPdf(byte[] html, String baseUri, String dest) throws IOException
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
OutlineHandler outlineHandler = OutlineHandler.createStandardHandler();
properties.setOutlineHandler(outlineHandler);
HtmlConverter.convertToPdf(
new ByteArrayInputStream(html), new FileOutputStream(dest), properties);
创建书签(或PDF标准中所称的大纲)是通过创建一个OutlineHandler并将该大纲处理程序传递给ConverterProperties来完成的。
在本例中,我们使用createStandardHandler()/CreateStandardHander()方法创建标准处理程序。实际上,这意味着pdfHTML将查找<h1>、<h2>、<h3>、<h4>、<h5>和<h6>。书签将基于HTML文件中这些标签的层次结构创建。在我们创建的电影概述中,我们只有<h1>标签。这就解释了为什么书印只有一层深。
我们还可以创建自定义OutlineHandler。
在图4.7中,我们看到了由每部电影的导演姓名组成的第二级书签。
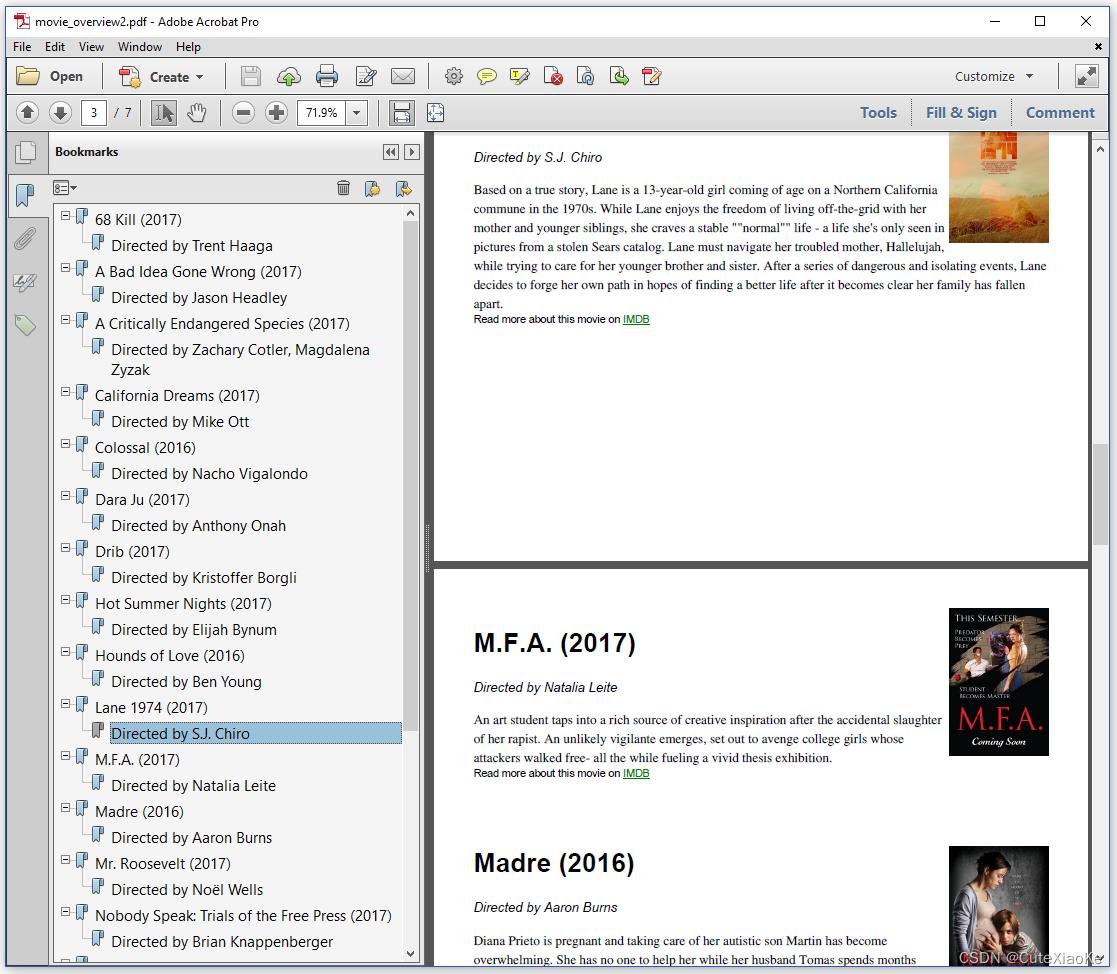
每部电影的导演都使用<p>标签添加到概述中,而其余信息则使用<div>标签添加。知道了这一点,我们可以创建一个自定义的OutlineHandle,在创建大纲时查找<h1>和<p>标签。代码如下。
public void createPdf(byte[] html, String baseUri, String dest)
throws IOException
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
OutlineHandler outlineHandler = new OutlineHandler();
outlineHandler.putTagPriorityMapping("h1", 1);
outlineHandler.putTagPriorityMapping("p", 2);
properties.setOutlineHandler(outlineHandler);
HtmlConverter.convertToPdf(
new ByteArrayInputStream(html), new FileOutputStream(dest), properties);
在这个createPdf()/CreatePdf()方法中,我们创建了一个新的OutlineHandler,并为<h1>-标签(优先级1)和<p>-标签(优先级2)添加了标签优先级。如果HTML中有<h2>、<h3>或任何其他标签,那么在创建大纲树时,这些标签将被忽略。
在下一组示例中,我们将创建一些发票/清单。在许多国家,法律要求公司将发票存档一定年限。PDF的一个子集称为PDF/A,其中a代表存档。PDF/A是长期保存文档所需的格式。创建发票/清单时,以PDF/A格式创建发票/清单被认为是最佳做法。
6. 使用pdfHTML创建PDF/A文档
如图4.8显示了PDF/A-2B格式的PDF发票。它是用我们在本章前面的示例中使用的相同XML创建的,但使用了不同的XSLT文件movies_invoice.xsl。
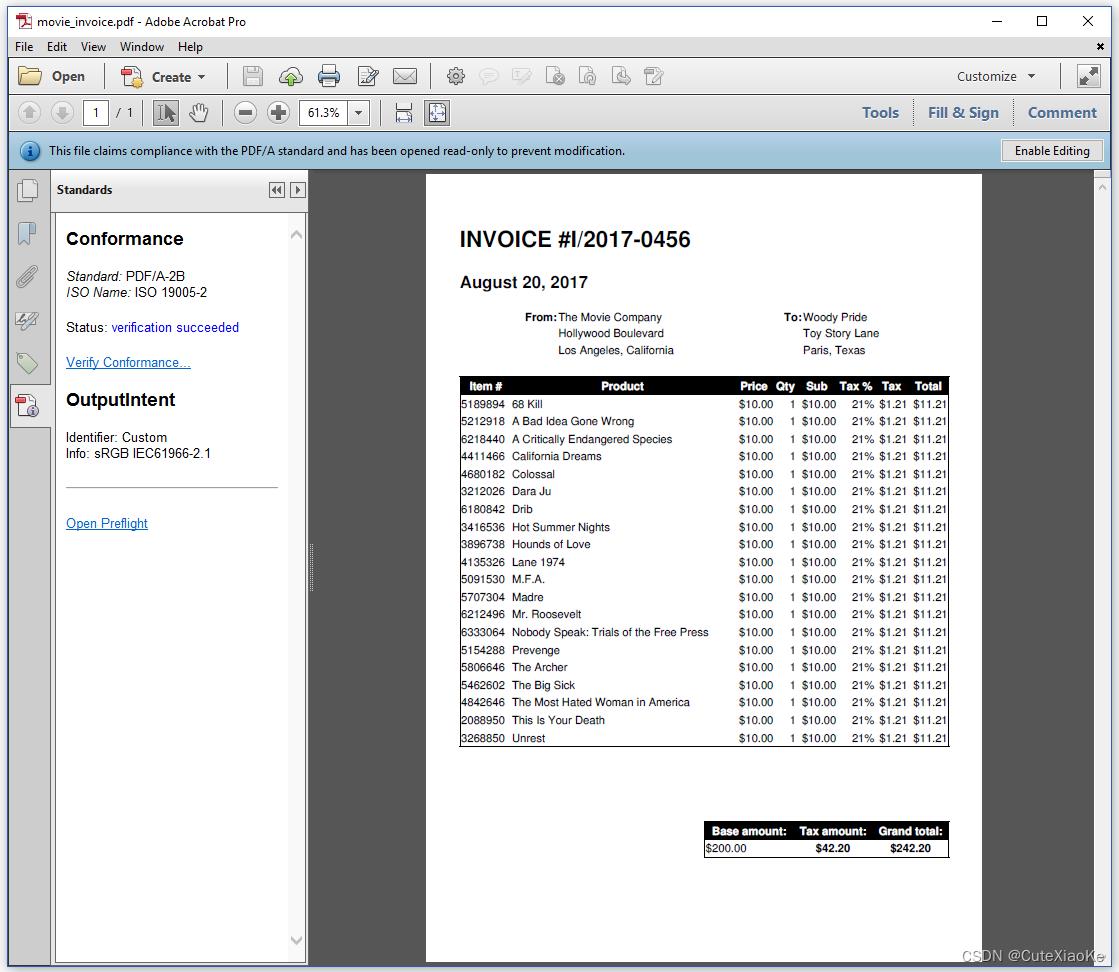
PDF/A也称为ISO 19005标准。它是ISO 32000的子集,定义了一组义务和限制。例如:
- 文件必须包含ISO 16684中描述的可扩展元数据平台(XMP)格式的元数据;
- 您需要将正确的颜色配置文件添加到文件中,这样就不会对颜色产生歧义;
- 文档必须是自包含的:所有字体都需要嵌入,不允许外部电影、声音或其他二进制文件,等等。
- 不允许javascript,也不允许加密。
本标准目前有三部分。批准的部分永远不会失效。创建新的部分是为了定义新的有用特征。
- PDF/A-1可以追溯到2005年。它基于PDF 1.4,定义了两个级别:B是确保视觉外观保存的“基本”级别;A是“可读的”级别,它在B级要求的基础上增加了对PDF进行标记的要求。
- PDF/A-2始于2011年。它基于ISO 32000-1,并为PDF/A-1添加了PDF 1.5、1.6和1.7中引入的一些功能,如支持JPEG2000、集合、对象级XMP和可选内容。还改进了对透明度、注释类型和注释以及数字签名的支持。它定义了三个层次:“基本”B级;“可理解/可读”A级;和“unicode”级别U。级别U类似于级别B,但额外要求所有文本都需要以unicode存储。
- PDF/A-3的日期为2012年。它与PDF/A-2相同,但有一个主要区别:在PDF/A-2中,所有附件都必须是符合PDF/A-1或PDF/A-2标准的PDF文件;在PDF/A-3中,允许使用各种附件(常规PDF文件、XML、docx、xslx等)。
除了我们用来创建看起来像发票的文档的不同布局之外,我们还必须对与PDF/A相关的HTML进行重要更改。在 movies_invoice.xsl XSLT文件中,我们在<body>中定义了一个字体。
我们将在第6章中讲述,FreeSans是一种随pdfHTML一起提供的字体,它始终是嵌入的,而不是默认的字体Helvetica,这是前面示例中使用的字体。嵌入所有字体是PDF/A的要求之一。
让我们看看下面代码的createPdf()/CreatePdf()方法还有什么不同:
public void createPdf(byte[] html, String baseUri, String dest, String intent) throws IOException
PdfWriter writer = new PdfWriter(dest);
PdfADocument pdf = new PdfADocument(writer,
PdfAConformanceLevel.PDF_A_2B,
new PdfOutputIntent("Custom", "", "https://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(intent)));
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
与前面的示例唯一的区别是,我们现在使用的是PdfADocument,而不仅仅是PdfDocument。我们将PdfAConformanceLevel(在本例中是PDF_A_2B,用于PDF/A-2B一致性)添加为构造函数的参数,并使用PdfOutputIntent对象传递颜色配置文件。
创建PDF/A-2A文件只需要两个小的更改。参见以下代码:
public void createPdf(byte[] html, String baseUri, String dest, String intent)
throws IOException
PdfWriter writer = new PdfWriter(dest);
PdfADocument pdf = new PdfADocument(writer,
PdfAConformanceLevel.PDF_A_2A,
new PdfOutputIntent("Custom", "", "https://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(intent)));
pdf.setTagged();
ConverterProperties properties = new ConverterProperties();
properties.setBaseUri(baseUri);
HtmlConverter.convertToPdf(new ByteArrayInputStream(html), pdf, properties);
我们将PdfAConformanceLevel从PDF_A_2B更改为PDF_A_2 A,由于第二个A代表“可理解/可读”的PDF,因此我们需要确保创建一个带标签的PDF,从而创建额外的行pdf.setTagged()/pdf.SetTagged()。图4.9显示Adobe Acrobat推测文档符合PDF/A-2A以及PDF/UA-1标准,其中UA代表通用可访问性。
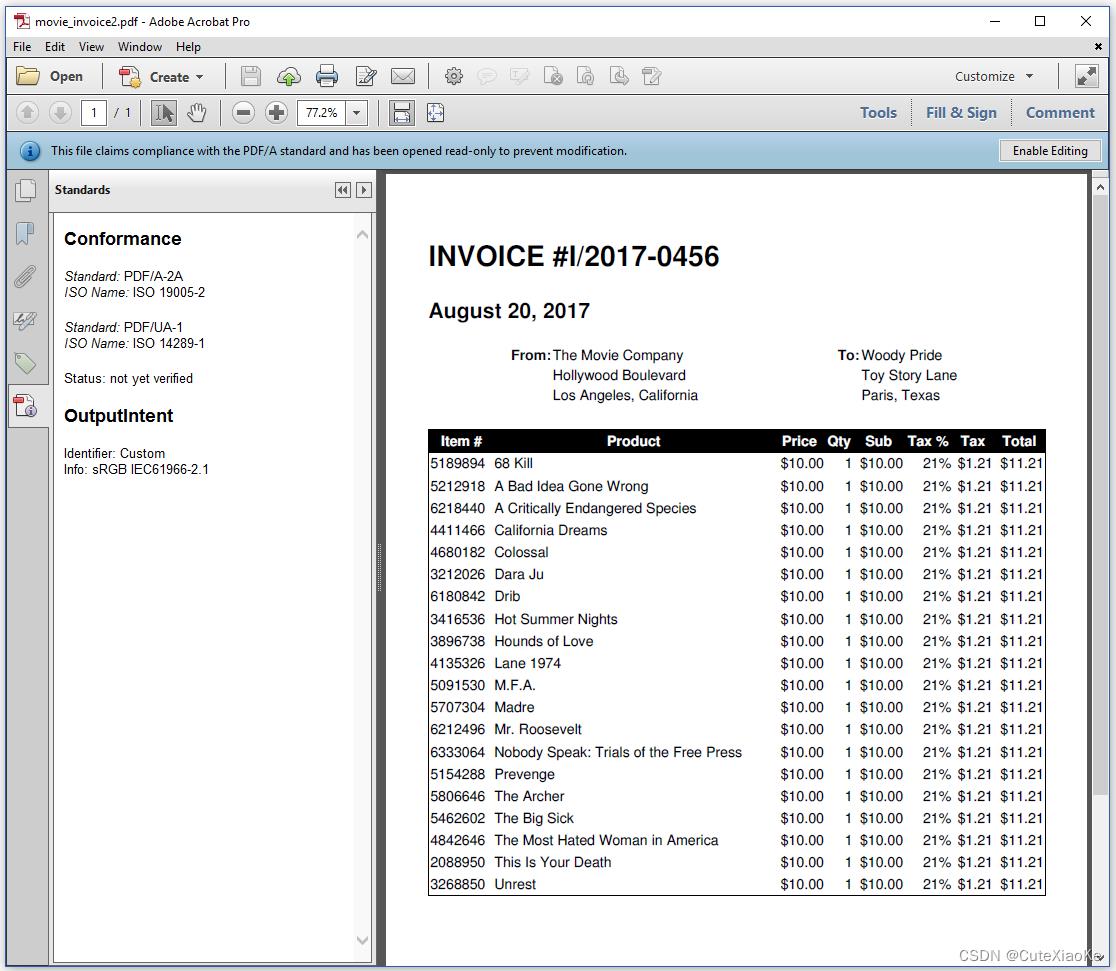
我们可以使用印前检查(Preflight)来验证此文件是否符合PDF/A-2A标准,但无法检查是否完全符合PDF/UA-1标准。PDF/UA有一系列只能由人类验证的要求。例如:只有人类才能检查PDF是否正确标签;即:如果所有的语义信息都是正确的。
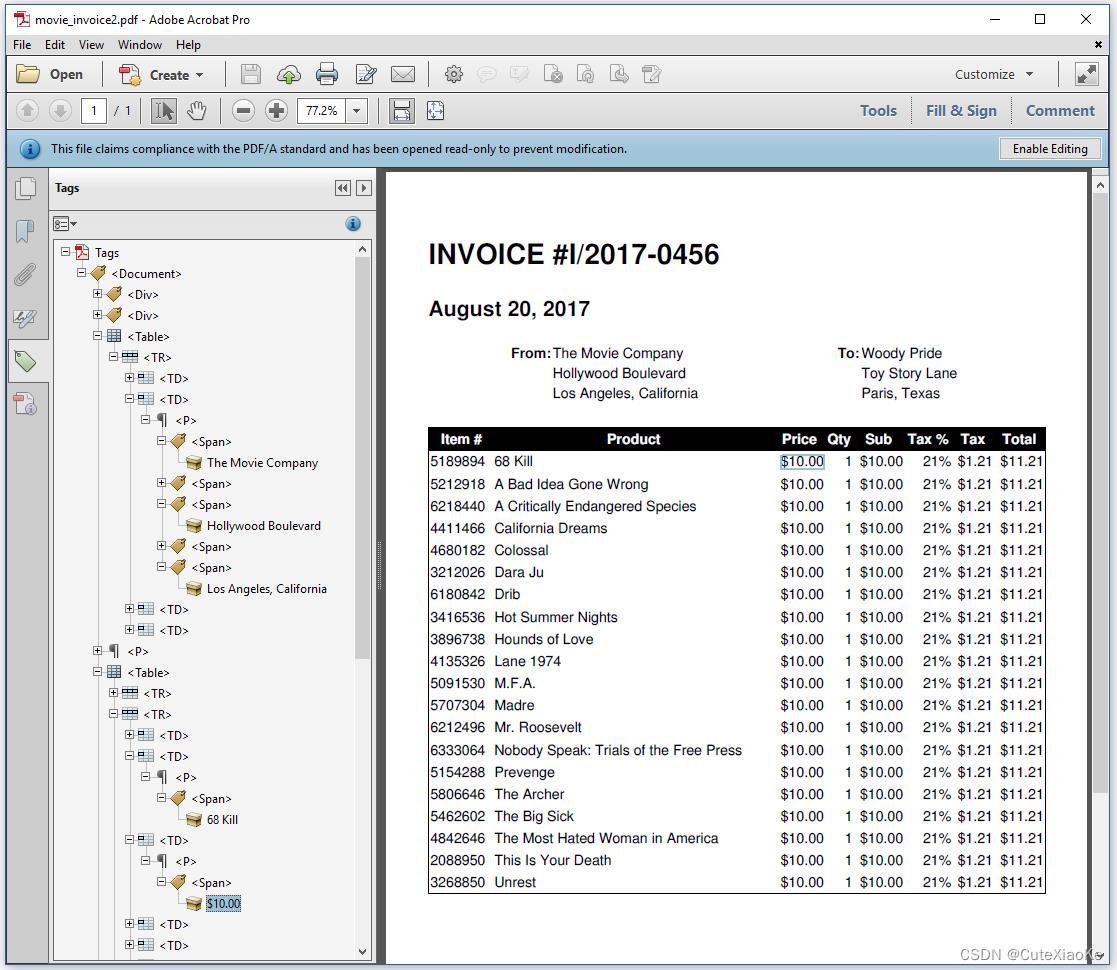
在上一章中,我们已经创建了一些带标签PDF文件,我们简要讨论了带标签PDF对于使用辅助技术的残疾人以及在下一代PDF中都很重要。在图4.10中,我们看到iText添加了一个表结构(参见<table>、<TR>和<TD>标签)。由人来检查这个表结构是否是内容的正确语义表示。
如果我们要将附件添加到PDF/A-2文件中,该附件也应该是PDF/A-1文件。PDF/A-3不存在此要求。例如:我们可以将用于创建HTML的原始XML文件作为额外数据添加到PDF文档中。
实现的代码如下:
public void createPdf(
byte[] xml, byte[] html, String baseUri, String dest, String intent)
throws IOException
PdfWriter writer = new PdfWriter(dest);
PdfADocument pdf = new PdfADocument(writer,
PdfAConformanceLevel.PDF_A_3A,
new PdfOutputIntent("Custom", "", "https://www.color.org",
"sRGB IEC61966-2.1", new FileInputStream(intent)));
pdf.setTagged();
pdf.addFileAttachment(
"Movie info", xml, "movies.xml",
PdfName.ApplicationXml, new PdfDictionary(), PdfName.Data);
ConverterProperties properties = new ConverterProperties();
properties.以上是关于iText7高级教程之html2pdf——4.使用pdfHTML创建报告的主要内容,如果未能解决你的问题,请参考以下文章