从4条脉络看Deep Learning 模型最近若干年的重要进展
Posted tealex
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从4条脉络看Deep Learning 模型最近若干年的重要进展相关的知识,希望对你有一定的参考价值。
一个学生帮忙整理的 Deep Learning 模型最近若干年的重要进展。有 4 条脉络,整理很不错。分享一下。
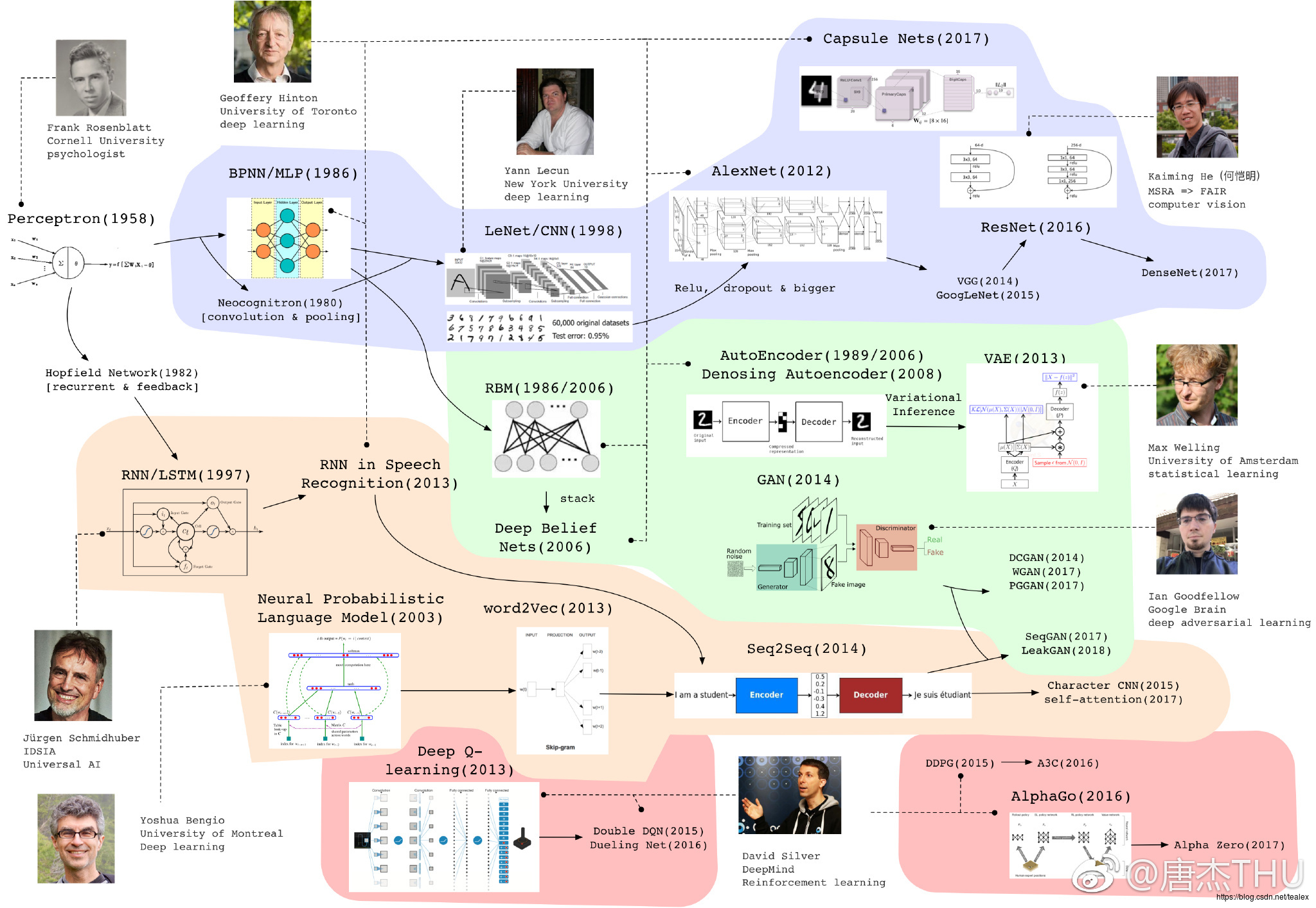
高清图下载点击
track1 cv/tensor:
1943 年出现雏形,1958 年研究认知的心理学家 Frank 发明了感知机,当时掀起一股热潮。后来 Marvin Minsky(人工智能大师)和 Seymour Papert 发现感知机的缺陷:不能处理异或回路、计算能力不足以处理大型神经网络。停滞!
1986 年 hinton 正式地提出反向传播训练 MLP,尽管之前有人实际上这么做。
1979 年,Fukushima 提出 Neocognitron,有了卷积和池化的思想。
1998 年,以 Yann LeCun 为首的研究人员实现了一个七层的卷积神经网络 LeNet-5 以识别手写数字。
后来 svm 兴起,这些方法没有很受重视。
2012 年,Hinton 组的 AlexNet 在 ImageNet 上以巨大优势夺冠,兴起深度学习的热潮。其实 Alexnet 是一个设计精巧的 CNN,加上 relu、dropout 等技巧,并且更大。
这条思路被后人发展,出现了 vgg、GooLenet 等。
2016 年,青年计算机视觉科学家何恺明在层次之间加入跳跃连接,Resnet 极大增加了网络深度,效果有很大提升。一个将这个思路继续发展下去的是去年 cvpr best paper densenet。
cv 领域的特定任务出现了各种各样的模型(Mask-RCNN 等),这里不一一介绍。
2017 年,hinton 认为反省传播和传统神经网络有缺陷,提出 Capsule Net。但是目前在 cifar 等数据集上效果一半,这个思路还需要继续验证和发展。
track2 生成模型
传统的生成模型是要预测联合概率分布 P(x,y)。
rbm 这个模型其实是一个基于能量的模型,1986 年的时候就有,他在 2006 年的时候重新拿出来作为一个生成模型,并且将其堆叠成为 deep belief network,使用逐层贪婪或者 wake-sleep 的方法训练,不过这个模型效果也一般现在已经没什么人提了。但是从此开始 hinton 等人开始使用深度学习重新包装神经网络。
Auto-Encoder 也是上个世纪 80 年代 hinton 就提出的模型,此时由于计算能力的进步也重新登上舞台。bengio 等人又搞了 denoise Auto-Encoder。
Max welling 等人使用神经网络训练一个有一层隐变量的图模型,由于使用了变分推断,并且最后长得跟 auto-encoder 有点像,被称为 Variational auto-encoder。此模型中可以通过隐变量的分布采样,经过后面的 decoder 网络直接生成样本。
GAN 是 2014 年提出的非常火的模型,他是一个隐的生成模型,通过一个判别器和生成器的对抗训练,直接使用神经网络 G 隐式建模样本整体的概率分布,每次运行相当于从分布中采样。
DCGAN 是一个相当好的卷积神经网络实现,WGAN 是通过维尔斯特拉斯距离替换原来的 JS 散度来度量分布之间的相似性的工作,使得训练稳定。PGGAN 逐层增大网络,生成机器逼真的人脸。
track3 sequence learning
1982 年出现的 hopfield network 有了递归网络的思想。1997 年 Jürgen Schmidhuber 发明 LSTM,并做了一系列的工作。但是更有影响力的是 2013 年还是 hinton 组使用 RNN 做的语音识别工作,比传统方法高出一大截。
文本方面 bengio 在 svm 最火的时期提出了一种基于神经网络的语言模型,后来 google 提出的 word2vec 也有一些反向传播的思想。在机器翻译等任务上逐渐出现了以 RNN 为基础的 seq2seq 模型,通过一个 encoder 把一句话的语义信息压成向量再通过 decoder 输出,当然更多的要和 attention 的方法结合。
后来前几年大家发现使用以字符为单位的 CNN 模型在很多语言任务也有不俗的表现,而且时空消耗更少。self-attention 实际上就是采取一种结构去同时考虑同一序列局部和全局的信息,google 有一篇耸人听闻的 attention is all you need 的文章。
track4 deep reinforcement learning
这个领域最出名的是 deep mind,这里列出的 David Silver 是一直研究 rl 的高管。
q-learning 是很有名的传统 rl 算法,deep q-learning 将原来的 q 值表用神经网络代替,做了一个打砖块的任务很有名。后来有测试很多游戏,发在 Nature。这个思路有一些进展 double dueling,主要是 Qlearning 的权重更新时序上。
DeepMind 的其他工作 DDPG、A3C 也非常有名,他们是基于 policy gradient 和神经网络结合的变种(但是我实在是没时间去研究)
一个应用是 AlphaGo 大家都知道,里面其实用了 rl 的方法也有传统的蒙特卡洛搜索技巧。Alpha Zero 是他们搞了一个用 alphago 框架打其他棋类游戏的游戏,吊打。
以上是关于从4条脉络看Deep Learning 模型最近若干年的重要进展的主要内容,如果未能解决你的问题,请参考以下文章