Mybatis设计与源码分析
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis设计与源码分析相关的知识,希望对你有一定的参考价值。
前言
前面文章主要针对mybatis有个大体的设计,包括 对 整个框架包括对于 mapper的存储,以及 如何应对我们常见的增删改查 如何去 定义 好 注解或者xml的方式来定义,如何进行参数之间的寻找等,都是需要设计的场景,以及 如何去执行sql 这是在 mybatis 框架给我们设计时,需要考虑到的; 这篇文章会继续 实现 mybatis框架 的各个部分,从而知道 mybatis框架 如何实现,最后在来看框架提供为我们做了多少事情。
设计框架的源码的好处
学习以及解析包括mybatis也好spring也好 ,这些热门的框架,都是让自己提升技术,包括在以后的开发中,别老是用什么 if else 这些 耦合性强的代码,而且不易后续功能的扩展以及 后后期维护时相当麻烦的,充分利用 接口 以及抽象类,将逻辑性的代码 进行抽象出来, 真正达到好的代码,单个类的单一原则等等,最后给我们的系统后期进行功能扩展也好 以及 重构也罢,是非常有必要的。 而且 当你学习 mybatis的源码 扩展点,自己也能写出来,通过接口的方式 对于 功能进行增强,这不是对于 我们一个大的提升么,可能 说这些对一些大牛来说都太小儿科了,所以废话不多说继续设计mybatis框架吧。
执行sql类的设计
对于mybatis最重要的一个类 ,Configuration
这里面持有了mappedStatements 这些 数据 ,都是在 mybatis中 给我们 的一个总的类。
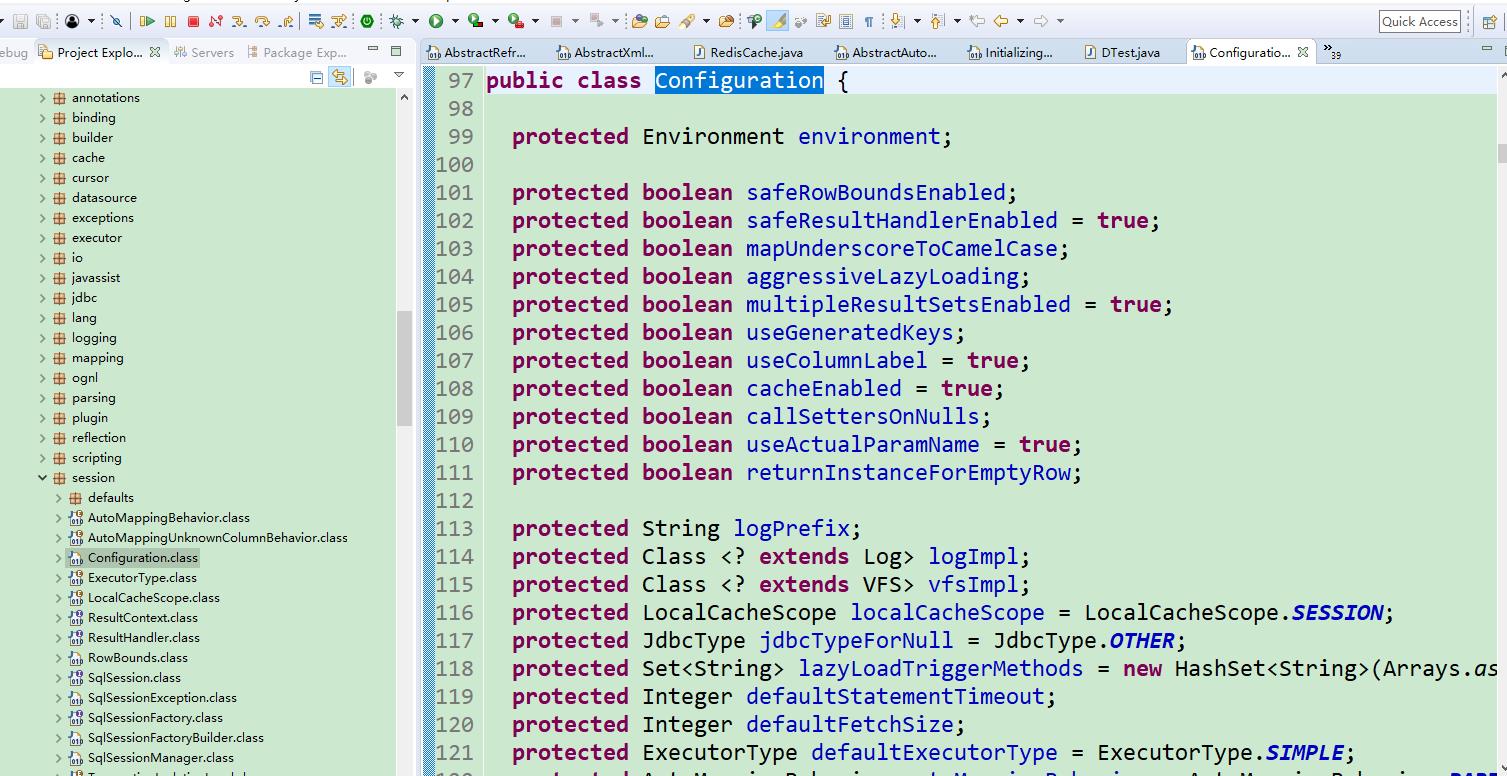
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
protected final InterceptorChain interceptorChain = new InterceptorChain();
protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry();
protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>("Mapped Statements collection");
protected final Map<String, Cache> caches = new StrictMap<Cache>("Caches collection");
protected final Map<String, ResultMap> resultMaps = new StrictMap<ResultMap>("Result Maps collection");
protected final Map<String, ParameterMap> parameterMaps = new StrictMap<ParameterMap>("Parameter Maps collection");
protected final Map<String, KeyGenerator> keyGenerators = new StrictMap<KeyGenerator>("Key Generators collection");
protected final Set<String> loadedResources = new HashSet<String>();
protected final Map<String, XNode> sqlFragments = new StrictMap<XNode>("XML fragments parsed from previous mappers");框架完成接口对象的生成,JDBC执行过程。
我们得要有 DataSource ,谁来持有 DataSource,并且执行sql的地方 都需要一个类去解决。 像下图一下 让 configuration 来持有也行, 然后 在spring 中获取到对应的datasource. 既方便又简单。
谁来执行SQL
如果使用 Confifiguration去执行sql ,这样做耦合性是非常大的,而且不适合,相当复杂,mybatis也不可能这么做。 来做事的,那就先定义一个接口吧: SqlSession 具体的执行 接口 包括 执行sql 增删改查的操作等等。
具体的执行 接口 包括 执行sql 增删改查的操作等等。

框架 对象接口的生成,实体类去执行,要做的事情 就是 要做的 sql 并且进行拼接等等。
具体的实现类的。 框架完成接口对象的生成,JDBC执行过程。
用户给定 Mapper 接口类,要为它生成对象,用户再使用这个对象完成对应的数据库操作。 相对应的数据库 操作。
相对应的数据库 操作。
UserDao userDao = sqlSession.getMapper(UserDao.class);
userDao.addUser(user);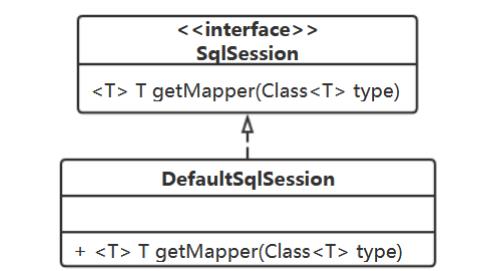
用户给入一个接口类,DefaultSqlSession中就为它生成一个对象 ,配置阶段扫描、解析Mapper接口时做个存储了
参数判断,类型转换,
这也是配置信息,还是存在Confifiguration 中,就用个Set来存吧。
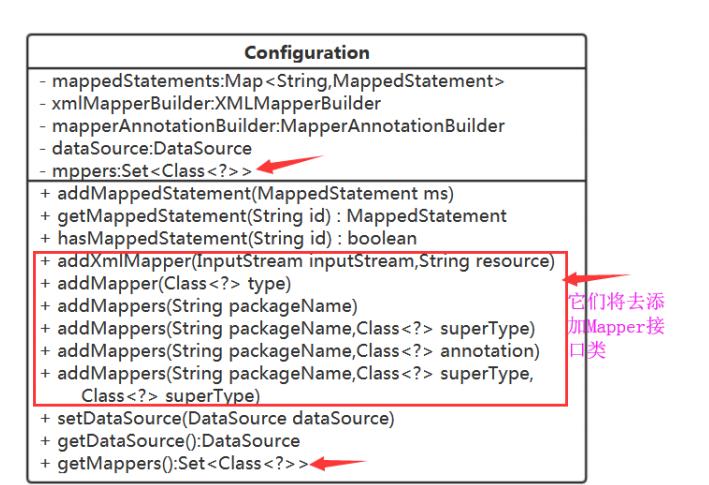
DefaultSqlSession中需要持有Confifiguration。
对象生成
如何为用户给入的 Mapper接口生成对象,使用代理的方式可以实现,JDK 动态代理。Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[]
mapperInterface , invocationHandler);public class DefaultSqlSession implements SqlSession
private Configuration configuration;
public DefaultSqlSession(Configuration configuration)
super();
this.configuration = configuration;
@Override
public <T> T getMapper(Class<T> type)
//检查给入的接口
if (!this.configuration.getMappers().contains(type))
throw new RuntimeException(type + " 不在Mapper接口列表中!");
//得到 InvocationHandler
InvocationHandler ih = null; // TODO 必须要有一个
// 创建代理对象
T t = (T)Proxy.newProxyInstance(type.getClassLoader(), new
Class<?>[] type, ih);
return t;
执行SQL的InvocationHandler
InvocationHandler 是在代理对象中完成增强。我们这里通过它来执行 SQL 。public interface InvocationHandler
/** @param proxy 生成的代理对象
@param method 被调用的方法
@param args @return Object 方法执行的返回值
*/
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;

package com.study.mybatis.session;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class MapperProxy implements InvocationHandler
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable
// TODO 这里需要完成哪些事?
return null;
这里需要做的事情 ,具体 要执行的。
// 1 、获得方法对应的 SQL 语句 // 2 、解析 SQL 参数与方法参数的对应关系,得到真正的 SQL 与语句参数值 // 3 、获得数据库连接 // 4 、执行语句 // 5 、处理结果获得方法对应的 SQL 语句 要获得 SQL 语句,需要用到 Confifiguration , MapperProxy 中需持有 Confifiguration 。
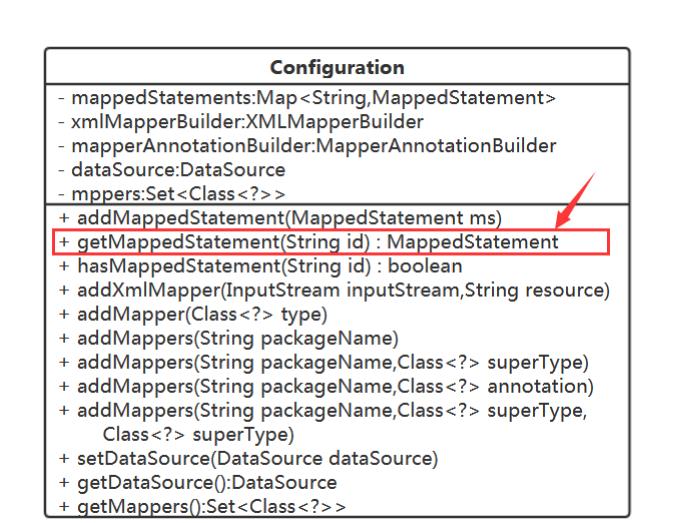
可以通过 method参数能得到方法名,但得到的类名不是Mapper接口类名。
让 MapperProxy 持有其增强的 Mapper 接口类。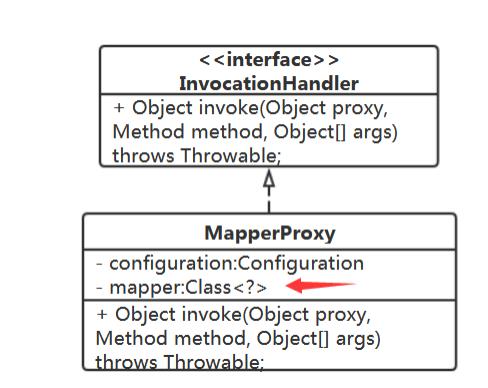 解析
SQL
参数与方法参数的对应关系,得到真正的
SQL
与语句参数值
逻辑:
1
、查找
SQL
语句中的
#
属性
,确定是第几个参数,再在方法参数中找到对应的值,存储下
来,替换
#
属性
为?
2
、查找
SQL
语句中的
$
属性
,确定是哪个参数,再在方法参数中找到对应的值,替换
$
属
性
。
3
、返回最终的
SQL
与参数数组。
解析过程涉及的数据:
SQL
语句、方法的参数定义、方法的参数值
解析
SQL
参数与方法参数的对应关系,得到真正的
SQL
与语句参数值
逻辑:
1
、查找
SQL
语句中的
#
属性
,确定是第几个参数,再在方法参数中找到对应的值,存储下
来,替换
#
属性
为?
2
、查找
SQL
语句中的
$
属性
,确定是哪个参数,再在方法参数中找到对应的值,替换
$
属
性
。
3
、返回最终的
SQL
与参数数组。
解析过程涉及的数据:
SQL
语句、方法的参数定义、方法的参数值
@Insert("insert into t_user(id,name,sex,age) values(#id,#name,# sex,#age)")
void addUser(String id,@Param("name")String xname,String sex,int age);Parameter[] params = method.getParameters();public Object invoke(Object proxy, Method method, Object[] args)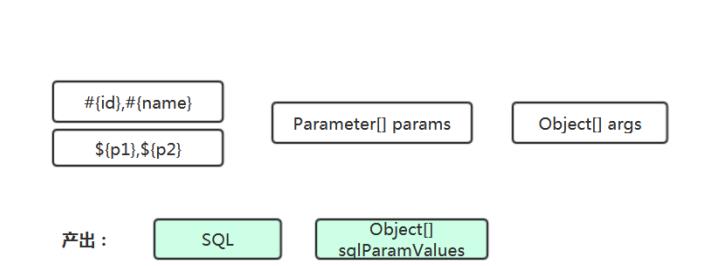
所以所有的都要抽象出来,这才是正常的开发 模式。 和系统
我可以一层一层往下传递。 最好不要填写 switch 这样下去。
 方式一相较于方式二,看起来复杂的地方是要遍历
Parameter[]
来确定索引号。
这个对应关系可以在扫描解析
Mapper
接口时做一次即可。在调用
Mapper
代理对象的方法时,
就可以直接根据索引号去
Object[] args
中取参数值了。
而 则每次调用
Mapper
代理对象的方法时,都需要创建转换
Map
。
而且方式一,单个参数与多个参数我们可以同样处理。
要在扫描解析
Mapper
接口时做参数解析我们就需要定义对应的存储结构,及修改
MappedStatement
了
?
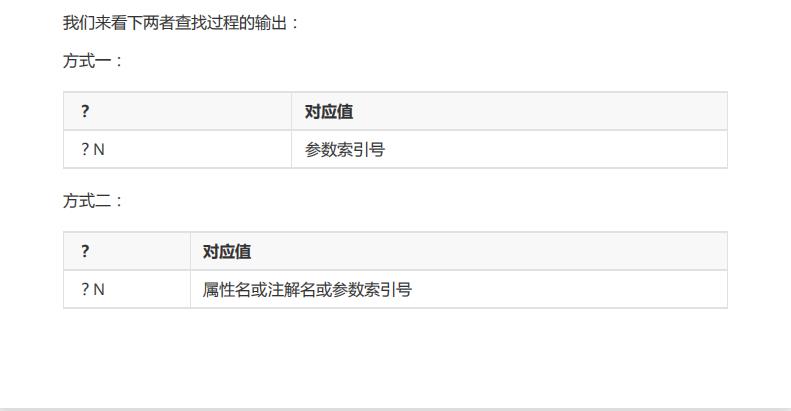
N---
参数索引号 的对应关系如何表示?
?
N
就是一个数值,而且是一个顺序数(只是
jdbc
中的?是从
1
开始)。我们完成可以用
List
来
存储。
方式一相较于方式二,看起来复杂的地方是要遍历
Parameter[]
来确定索引号。
这个对应关系可以在扫描解析
Mapper
接口时做一次即可。在调用
Mapper
代理对象的方法时,
就可以直接根据索引号去
Object[] args
中取参数值了。
而 则每次调用
Mapper
代理对象的方法时,都需要创建转换
Map
。
而且方式一,单个参数与多个参数我们可以同样处理。
要在扫描解析
Mapper
接口时做参数解析我们就需要定义对应的存储结构,及修改
MappedStatement
了
?
N---
参数索引号 的对应关系如何表示?
?
N
就是一个数值,而且是一个顺序数(只是
jdbc
中的?是从
1
开始)。我们完成可以用
List
来
存储。
@Insert("insert into t_user(id,name,sex,age,org_id) values(#user.id,# user.name,#user.sex,#user.age,#org.id)")
void addUser(User user,Org org);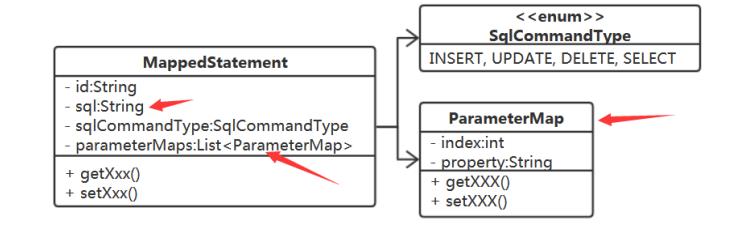
解析阶段有它们俩完成这件事:
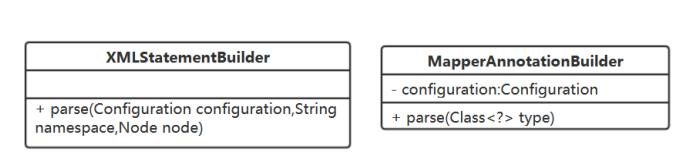
把MapperProxy的invoke方法填填看:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable
// TODO 这里需要完成哪些事?
// 1、获得方法对应的SQL语句
String id = this.mapper.getName() + "." + method.getName();
MappedStatement ms = this.configuration.getMappedStatement(id);
// 2、解析SQL参数与方法参数的对应关系,得到真正的SQL与语句参数值
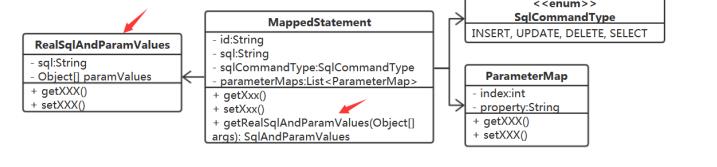
RealSqlAndParamValues rsp = ms.getRealSqlAndParamValues(args);
// 3、获得数据库连接
Connection conn = this.configuration.getDataSource().getConnection();
// 4、执行语句。
PreparedStatement pst = conn.prepareStatement(rsp.getSql());
// 疑问:语句一定是PreparedStatement?
// 设置参数
if (rsp.getParamValues() != null)
int i = 1;
for (Object p : rsp.getParamValues())
pst.setxxx(i++, p);
//这里写不下去了.......如何决定该调用pst的哪 个set方法?
// 5、处理结果
return null;
JavaType、JdbcType转换
JavaType : java 中的数据类型。 JdbcType : Jdbc 规范中根据数据库 sql 数据类型定义的一套数据类型规范,各数据库厂商遵照这 套规范来提供 jdbc 驱动中数据类型支持。
pst的set方法中与对应的:

这种情况:

要使用的JDBCType,不然鬼知道他想要什么。
用户怎么指定 面向接口编程, 把不变 定义到 接口里面 以不变应万变 TypeHandler
下面这个if-else-if的代码是否可以通过TypeHandler,换成策略模式
int i = 1;
for (Object p : rsp.getParamValues())
if (p instanceof Byte)
pst.setByte(i++, (Byte) p);
else if (p instanceof Integer)
pst.setInt(i++, (int) p);
else if (p instanceof String)
pst.setString(i++, (String) p);
... else if(...)
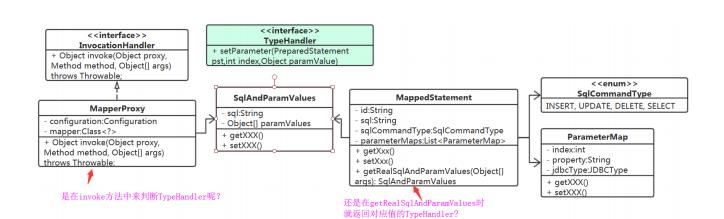
MapperProxy.invoke()中 设置 还需要JDBCType。
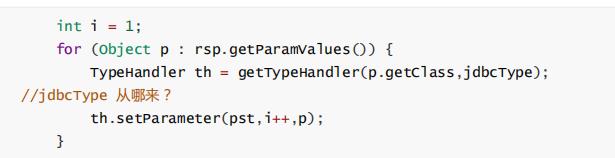
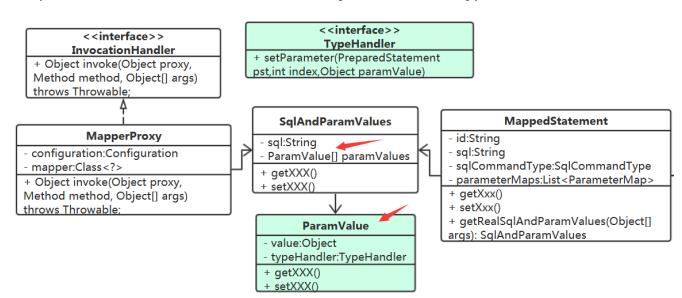
MapperProxy中的代码就变成下面这样了:
int i = 1;
for (ParamValue p : rsp.getParamValues())
TypeHandler th = p.getTypeHandler()
th.setParameter(pst,i++,p.getValue());
MappedStatement又从哪里去获取TypeHandler
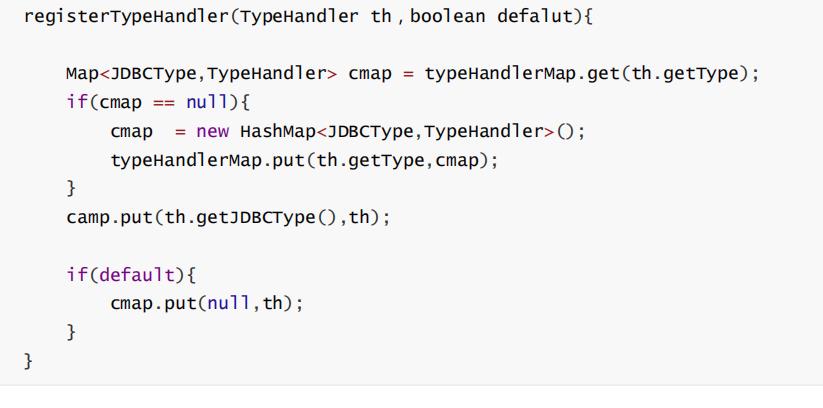
Confifiguration 吧,它最合适了。以什么结构来存储呢? 这里涉及到查找,需要根据 参数的javaType 、 jdbcTyp 来查找。Map<Type,Map<JDBCType,TypeHandler>> typeHandlerMap;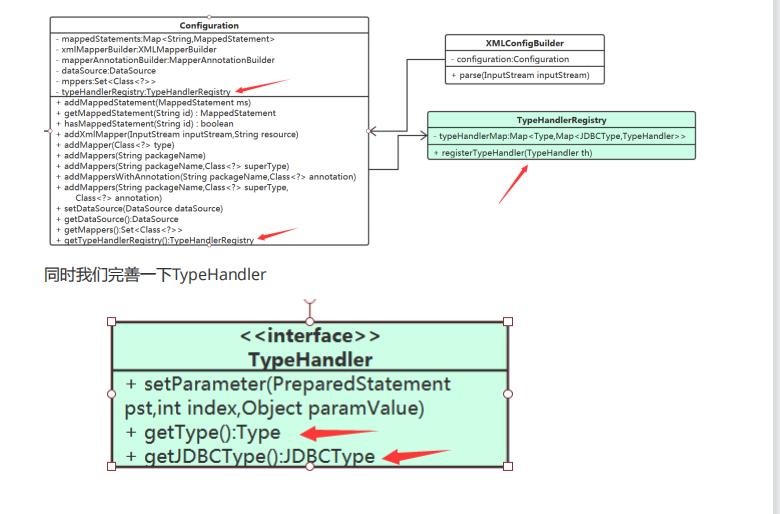
其实这样设计的方式可以放到 我们开发项目时,这个 应该都明白把。
这个在mybatis中也使用到的,可以采用 注册进去。
用户如何来指定它们的TypeHandler
在 mybatis-confifig.xml 中增加一个元素来让用户指定吧。 mybatis-confifig.dtd<!ELEMENT configuration (mappers?, typeHandlers?)+ >
<!ELEMENT mappers (mapper*,package*)>
<!ELEMENT mapper EMPTY>
<!ATTLIST mapper resource CDATA #IMPLIED url CDATA #IMPLIED class CDATA #IMPLIED ><!ELEMENT package EMPTY>
<!ATTLIST package name CDATA #IMPLIED type CDATA #IMPLIED annotation CDATA #IMPLIED ><!ELEMENT typeHandlers (typeHandler*,package*)>
<!ELEMENT typeHandler EMPTY> <!ATTLIST typeHandler class CDATA #REQUIRED ><configuration>
<mappers>
<mapper resource="com/mike/UserMapper.xml"/>
<mapper url="file:///var/mappers/CourseMapper.xml"/>
<mapper class="com.study.dao.UserDao" />
<package name="com.study.mapper" />
<mappers>
<typeHandlers>
<typeHandler class="com.study.type.XoTypeHandler" />
<package name="com.study.type" />
</typeHandlers>
</configuration>
MappedStatement中来决定TypeHandler,它就需要Confifiguration

ParameterMap中增加typeHandler属性。
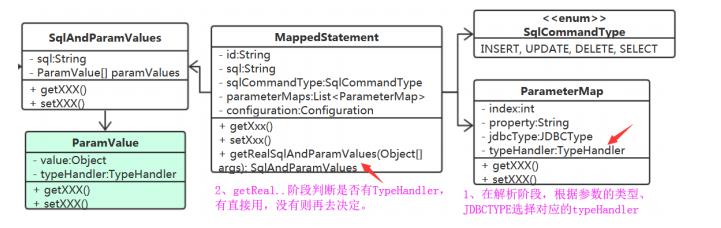
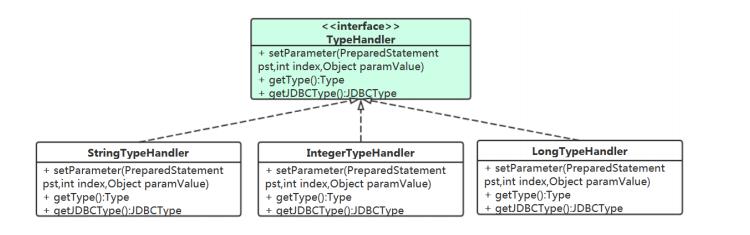 用户在
SQL
中参数定义没有指定
JDBCType
,则我们可以直接使用我们默认的
TypeHandler
如
#user.name
我们判断它的参数类型为
String
,就可以指定它的
TypeHandler
为
StringTypeHandler
。可能
它的数据库类型不为
VACHAR
,而是一个
CHAR
定长字符,没关系!因为
pst.setString
对
VARCHAR
、
CHAR
是通用的。
其实所有的扩展 ,在项目中你也要考虑使用这样的方式去解决。
mybatis有大量的handler 的项目,
用户在
SQL
中参数定义没有指定
JDBCType
,则我们可以直接使用我们默认的
TypeHandler
如
#user.name
我们判断它的参数类型为
String
,就可以指定它的
TypeHandler
为
StringTypeHandler
。可能
它的数据库类型不为
VACHAR
,而是一个
CHAR
定长字符,没关系!因为
pst.setString
对
VARCHAR
、
CHAR
是通用的。
其实所有的扩展 ,在项目中你也要考虑使用这样的方式去解决。
mybatis有大量的handler 的项目,
执行结果处理
执行结果处理要干的是什么事
pst.executeUpate() 的返回结果是 int ,影响的行数。 pst.executeQuery() 的返回结果是 ResultSet 。 在得到语句执行的结果后,要转为方法的返回结果进行返回。这就是执行结果处理要干的事 根据方法的返回值类型来进行相应的处理。 这里我们根据语句执行结果的不同,分开处理: 1 、 pst.executeUpate() 的返回结果是 int 。 void 、 int 、 long ,其他的不可以! 2 、 pst.executeQuery() 的返回结果是 ResultSet 可以是 void 、单个值、集合。 集合的元素可以是任意类型的 根据结果集列名与属性名对应等等的形式。 需用户显式说明映射规则这里需要涉及到的 数据进行转换 ,集合的处理, 对应的字段名等处理。
Executor 中 进行 执行 处理 并返回值。
考虑 JDBCType --- JavaType 的处理 根据方法的返回值类型来进行相应的处理。 这里我们根据语句执行结果的不同,分开处理:// 6、执行语句并处理结果
switch (ms.getSqlCommandType())
case INSERT:
case UPDATE:
case DELETE:
int rows = pst.executeUpdate();
return handleUpdateReturn(rows, ms, method);
case SELECT:
ResultSet rs = pst.executeQuery();
return handleResultSetReturn(rs, ms, method);
pst.executeUpate()的返回结果处理。
pst.executeUpate() 的返回结果是 int pst.executeQuery()
的返回结果处理
pst.executeQuery()
的返回结果是
ResultSet
方法的返回值可以是什么?
可以是
void
、单个值、集合。
单个值可以是什么类型的值?
任意值、(
map)
pst.executeQuery()
的返回结果处理
pst.executeQuery()
的返回结果是
ResultSet
方法的返回值可以是什么?
可以是
void
、单个值、集合。
单个值可以是什么类型的值?
任意值、(
map)
@Select("select count(1) from t_user where sex = #sex")
int query(String sex);
@Select("select id,name,sex,age,address from t_user where id = #id")
User queryUser(String id);
@Select("select id,name,sex,age,address from t_user where id = #id")
Map queryUser1(String id);这里也需要 策略模式 ,来根据不同的变换 来走不同的路径 进行转换数据。
无论结果是什么类型的,在这里我们都是要完成一件事:从查询结果中获得数据返回,只是返 回类型不同,有不同的获取数据的方式。 这也是变与不变的部分。@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount)
ResultMap resultMap = resultMaps.get(resultSetCount);
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null)
while (rsw != null && resultSetCount < resultSets.length)
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null)
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
return collapseSingleResultList(multipleResults);
private Object handleResultSetReturn(ResultSet rs, MappedStatement ms, Object[] args)
// TODO Auto-generated method stub
return null;

那么在handleResultSetReturn()方法中我们从哪得到ResultHandler呢
这肯定是在解析时,就能获取到,
从 MappedStatement 中获取,每个语句对象(查询类型的)中都持有它对应的结果处理器。 在解析准备 MappedStatement 对象时根据方法的返回值类型选定对应的 ResultHandler 。
在handleResultSetReturn方法中只需调用ms中的ResultHandler:
private Object handleResultSetReturn(ResultSet rs, MappedStatement ms, Object[] args) throws Throwable
return ms.getResultHandler().handle(rs, args);
基本数据类型、String 如何处理
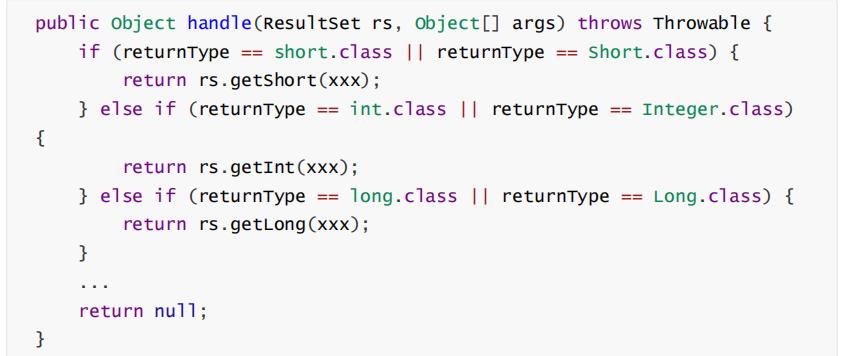
针对这种情况,提供对应的ResultHandler实现:
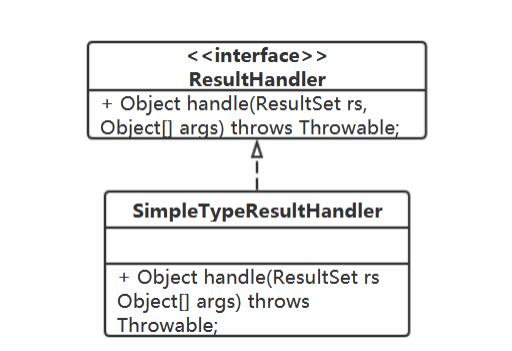
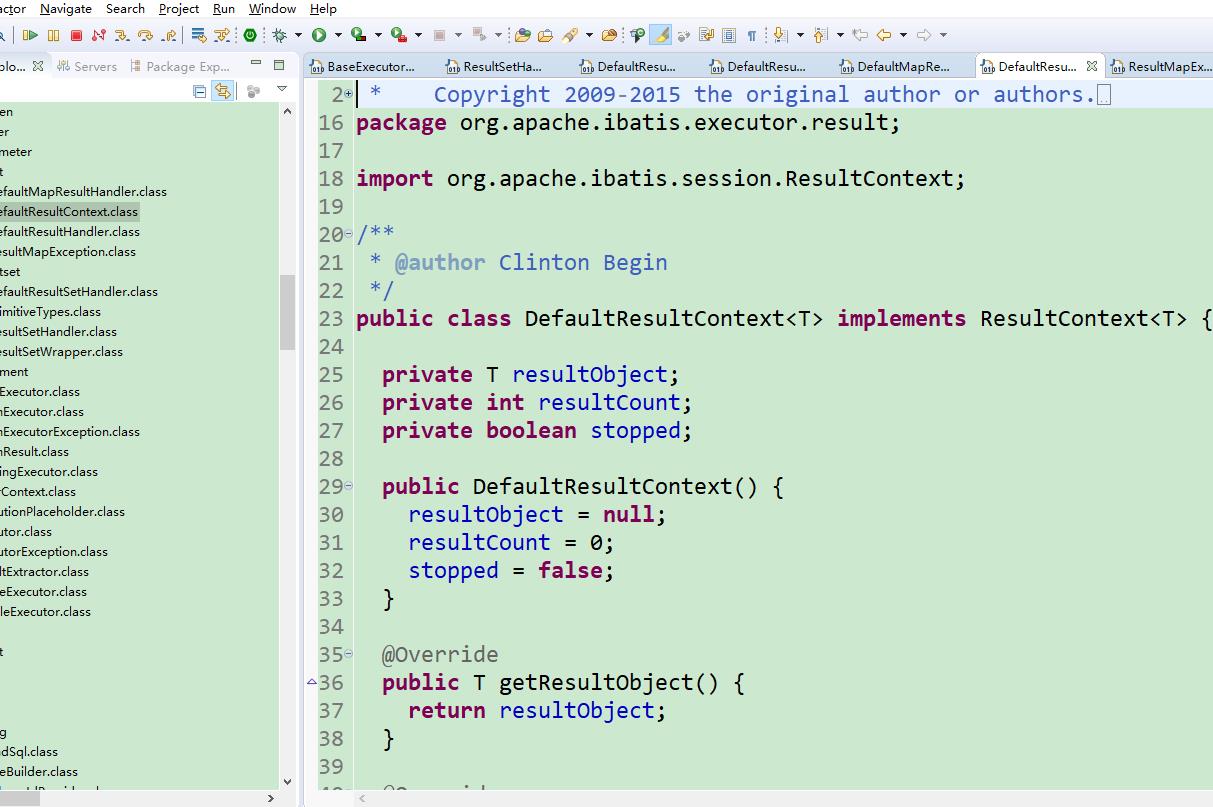
handle方法中的逻辑
public Object handle(ResultSet rs, Object[] args) throws Throwable
//从rs中取对应值
return rs.getXXX(OOO);
该调用rs的哪个get方法
得根据返回值来,返回值类型从哪来? 从 SimpleTypeResultHandler 中取,在创建 MappedStatement 时,根据反射获得的返回值类 型给入到 SimpleTypeResultHandler 中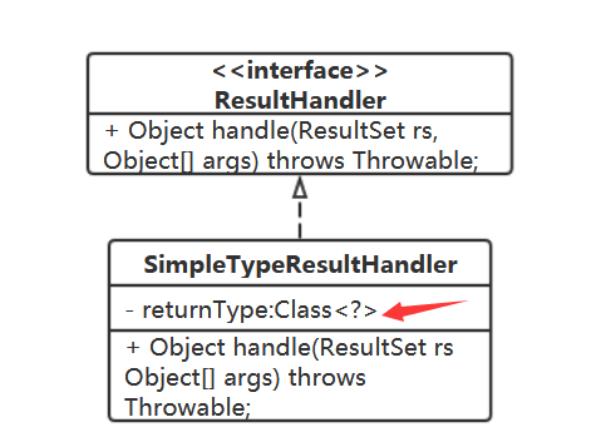
对于mybatis来说 更加麻烦一点,是放到 factory中做的处理。
SimpleTypeResultHandler的handle方法中的代码逻辑如下:
该返回值情况下不允许结果集多列。
不限制,用户指定列名,不指定则取第一列。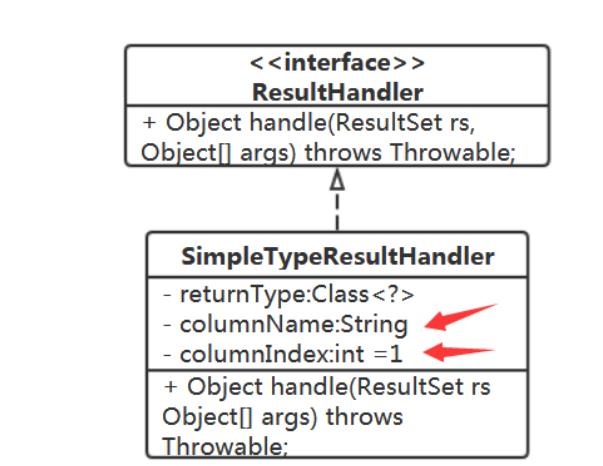
if else 的解决办法,利用策略模式 去解决。
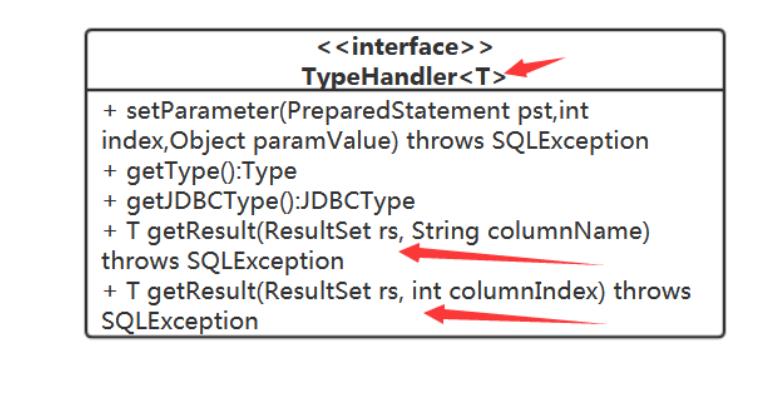
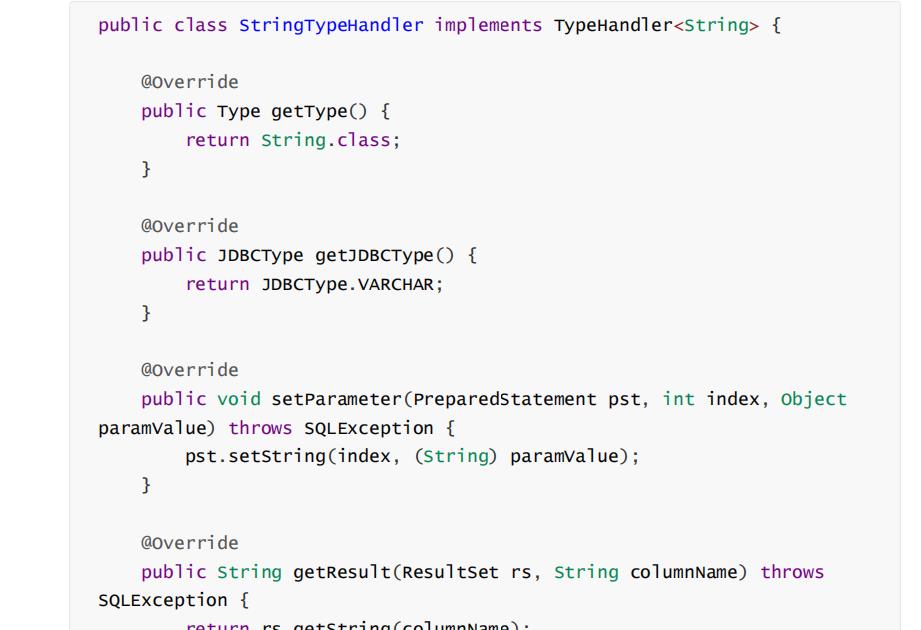
public interface TypeHandler<T>
Type getType(); JDBCType getJDBCType();
void setParameter(PreparedStatement pst, int index, Object paramValue) throws SQLException;
T getResult(ResultSet rs, String columnName) throws SQLException;
T getResult(ResultSet rs, int columnIndex) throws SQLException;
在启动解析阶段完成结果的TypeHandler选定。

很好,那就可以在SimpleTypeResultHandler中持有对应的TypeHandler。
在 SimpleTypeResultHandler 中还有必要持有 Class<?> returnType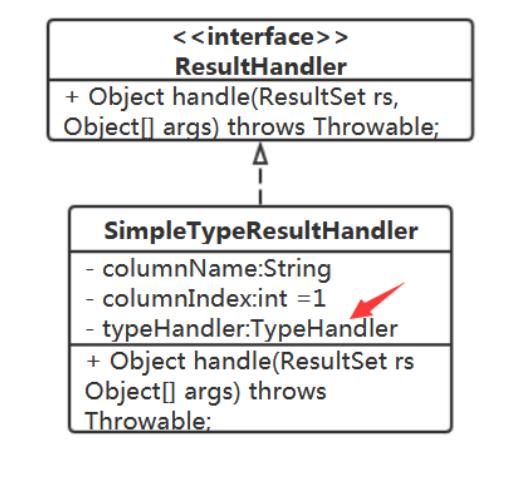
SimpleTypeResultHandler 的handle方法代码就简单了:
public Object handle(ResultSet rs, Object[] args) throws Throwable
if (StringUtils.isNotEmpty(columnName))
return typeHandler.getResult(rs, columnName);
else
return typeHandler.getResult(rs, columnIndex);
对于对象的情况下。通过 工厂类,进行创建 对象,
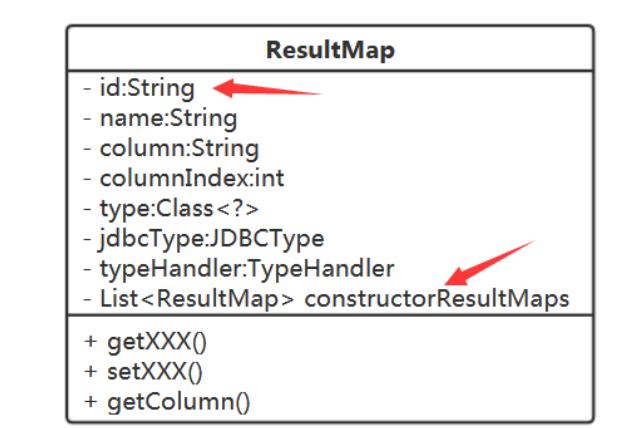
创建对象,则需要对应的构造参数值。 得定义构造参数与 ResultSet 中列的对应规则 1 、优先采用指定列名的方式:用参数名称当列名、或用户为参数指定列名(参数名与列名不 一致时、取不到参数名时); 2 、如不能取得参数名,则按参数顺序来取对应顺序的列。 注解、 xml配置 指定列名 利用别名的方式。 对应的 参数 解析的时候,都会放到里面。 定义一个结果映射实体: ResultMap 在创建
ResultMap
时,当用户没有指定
TypeHandler
或是
UndefifinedTypeHandler
时,要根据
type
、
jdbcType
取对应的
typeHandler
,没有则为
null;
ResultMap
类定义本身就是表示一种
java
类型与
JDBCType
类型的映射,基本数据类型与复合类
型(类)都是
java
类型。 扩充一下ResultMap
即可:
在创建
ResultMap
时,当用户没有指定
TypeHandler
或是
UndefifinedTypeHandler
时,要根据
type
、
jdbcType
取对应的
typeHandler
,没有则为
null;
ResultMap
类定义本身就是表示一种
java
类型与
JDBCType
类型的映射,基本数据类型与复合类
型(类)都是
java
类型。 扩充一下ResultMap
即可:
 xml
:根据
constructor
元素中
arg
元素的数量、
javaType
来确定构造函数。注意
arg
有顺序规
则、必须指定构造方法的全部参数。
xml
:根据
constructor
元素中
arg
元素的数量、
javaType
来确定构造函数。注意
arg
有顺序规
则、必须指定构造方法的全部参数。
 结果集中取值来填装对象则是复杂的
不是一行一个
Blog
对象,处理行时要判断该行的
blog
是否已取过了。 需要判断
注解方式:在
@Arg
、
@Rersult
注解中增加
id
指定项。
怎么知道,属性列表和 和字段值进行对比,都可以采用这种方式去,查询数据等。
结果集中取值来填装对象则是复杂的
不是一行一个
Blog
对象,处理行时要判断该行的
blog
是否已取过了。 需要判断
注解方式:在
@Arg
、
@Rersult
注解中增加
id
指定项。
怎么知道,属性列表和 和字段值进行对比,都可以采用这种方式去,查询数据等。
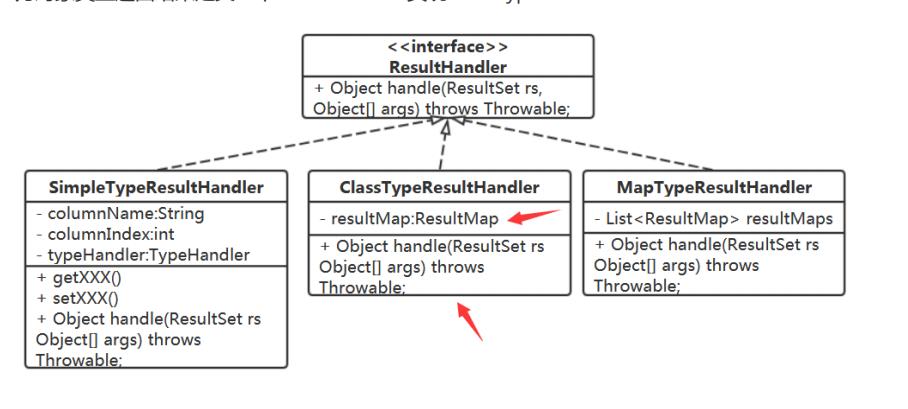
这里需要根据具体的 的去判断 到底是那个数据的转换。
TypeHandler ---> javaType 在 TypehandlerRegistry 中定义一个 JDBCType 类型对应的默认的 TypeHandler 集合,来完成取 java 值放入到 Map 中 然后其他的怎么判断 的,都可以通过策略模式将 隔离开。 第一次处理结果时,要把这个 ResultMaps 填充好,后需查询结果的处理就是直接使用 resultMapMybatis源码解读
Mybatis整体架构图
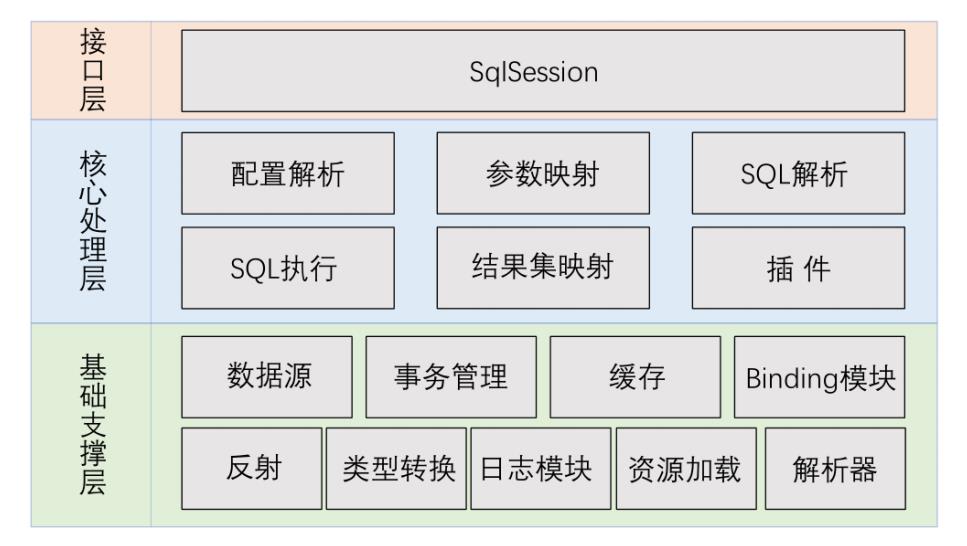
每个基于 MyBatis 的应用都是以一个 SqlSessionFactory 的实例为核心的。SqlSessionFactory 的实例可以通过 SqlSessionFactoryBuilder 获得。而 SqlSessionFactoryBuilder 则可以从 XML 配置文件或一个预先配置的 Configuration 实例来构建出 SqlSessionFactory 实例。
从 XML 文件中构建 SqlSessionFactory 的实例非常简单,建议使用类路径下的资源文件进行配置。 但也可以使用任意的输入流(InputStream)实例,比如用文件路径字符串或 file:// URL 构造的输入流。MyBatis 包含一个名叫 Resources 的工具类,它包含一些实用方法,使得从类路径或其它位置加载资源文件更加容易。
Mybatis 核心流程三大阶段 1. 初始化阶段 读取 XML 配置文件和注解中的配置信息,创建配置对象,并完成各个模块的初始化的工作; 2. 代理阶段 封装 iBatis 的编程模型,使用 mapper 接口开发的初始化工作; 3. 数据读写阶段 通过 SqlSession 完成 SQL 的解析,参数的映射、 SQL 的执行、结果的解析过程; Mybatis 的初始化 建造者模式 建造者模式( Builder Pattern )使用多个简单的对象一步一步构建成一个复杂的对象。这种类型的设计 模 式属于创建型模式,它提供了一种创建对象的最佳方式。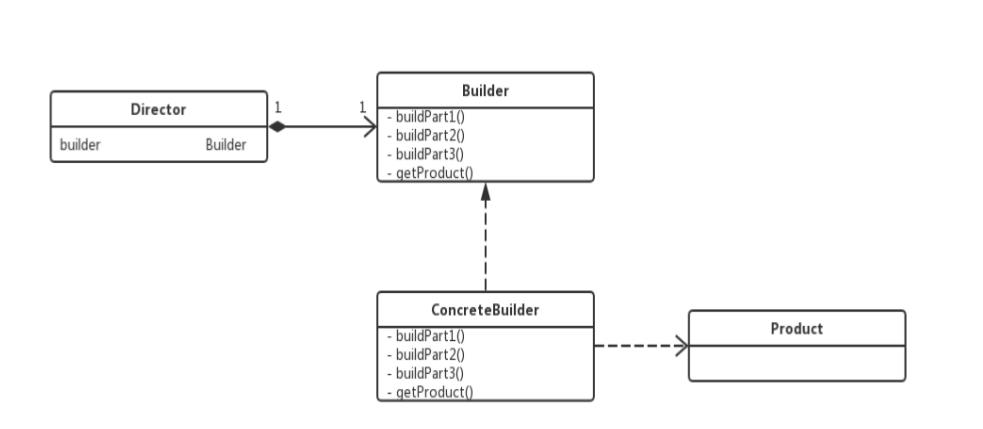
将各个部分进行组装起来的。
Builder :给出一个抽象接口以上是关于Mybatis设计与源码分析的主要内容,如果未能解决你的问题,请参考以下文章