CMU 15-445 数据库课程第三课文字版 - 存储1
Posted 干货满满张哈希
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CMU 15-445 数据库课程第三课文字版 - 存储1相关的知识,希望对你有一定的参考价值。
熟肉视频地址:
1. 课程大纲

这门课主要是关于如何开发一个功能全面的数据库管理系统,而不是如何编写复杂的 SQL 查询以及设计出最合理的关系模型数据库表。这门课会告诉你从低往上设计一个数据库管理系统需要的这些技术栈层:
- 磁盘管理(Disk Manager)
- 缓存池管理(Buffer Pool Manager)
- 访问方法(Access Method)
- 操作执行(Operator Execution)
- 查询计划(Query Plan)
涉及的主题包括:
- 关系数据库(Relational Databases,这个前面两节课已经过了一遍,咱们这个系列从第三节课开始,这部分就省略了)
- 存储(Storage)
- 执行(Execution)
- 并发控制(Concurrency Control)
- 恢复(Recovery)
- 分布式数据库(Distributed Databases)
- 其他一些有意思的实战(Potpourri)
2. 存储介质与为何不用 mmap

面向磁盘的数据库系统是这样一个系统,软件假定数据库的主要搜索位置在磁盘上。这意味着执行一个查询,它可能要访问不在内存中的数据,它需要将数据从 non-volatile 存储(例如磁盘)加载到 volatile 存储(例如内存)中。

计算机存储层次结构如上图所示,越往上,大小越小,成本越昂贵但是访问速度越快,越往下,大小越大,成本越低但是访问速度更慢,这些从顶部往下包括:
- Volatile 存储:断电后,存储的数据会丢失。支持字节访问,即可以直接读取取任意字节大小的数据,也可以直接更新。随机访问与顺序访问的速度差不多。
- CPU 寄存器
- CPU 缓存(L1,L2,L3)
- DRAM(Dynamic Random Access Memory 动态随机存取存储器)
- non-volatile 存储:断电后,存储的数据不会会丢失。不支持字节访问,只支持块访问,即如果你要读取某一字节的数据,必须将这字节所在的块或者页(page)的数据一起读取出来,并且一起更新。随机访问速度远小于顺序读取,所以对于 non-volatile 存储必须尽量用顺序访问。
- SSD(Solid State Disk,固态硬盘)
- HDD(Hard Disk Drive,硬盘驱动器):这里他经常管这块叫做 Spinning Disk Hard Drive,其实就是机械硬盘,一个磁头在磁盘上面不断移动寻找数据。
- Network Storage(网络存储):像是 AWS 的 EBS 以及 S3 这种网络存储服务。
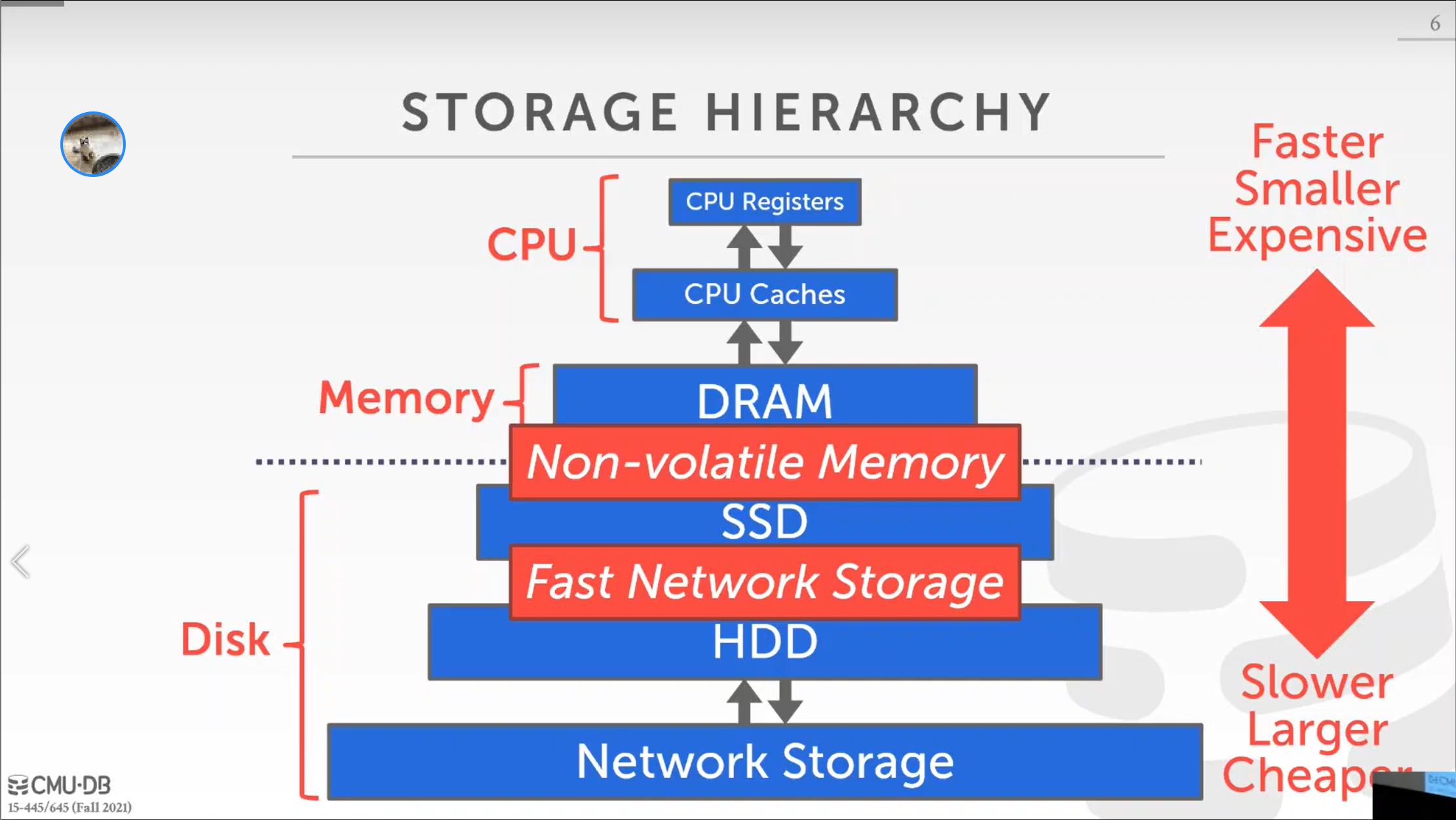
在这门课中,不会关心 CPU 寄存器以及缓存,将 DRAM 看做内存(Memory),将 SSD、HDD、Network Storage 看做磁盘(Disk)。我们只关心内存和磁盘。
这里其实还有一些新型的存储,可能打破这些边界,例如:
- Non-volatile Memory:可以像内存一样支持字节访问,同时掉电也不会丢失数据。目前发布的产品是 Intel® Optane™ Memory:https://www.intel.com/content/www/us/en/products/details/memory-storage/optane-memory.html
- Fast Network Storage:快速网络存储,例如 NAS(Network Attached Storage)
这些新型存储可能会打破现有的设计,但是他们还没有被大幅度的采用,这门课还不会涉及这些。
下面我们再来看看访问这些不同存储大概的耗时(网上各种数字很多,我们只要关注数量级即可)


因此,我们数据库管理系统的目标,虽然我们想要存储一个超过可用内存容量的数据库,但是我们想给应用程序提供一种错觉,即我们有足够的内存将整个数据库存储在内存中,用一些缓存,预先计算一些数据,允许不同的线程或不同的查询同时运行来避免每次读或写的时候都因为写入或者读取磁盘导致执行效率低。

我们要在这门课上设计的是一个基于磁盘持久化的 DBMS,如上图所示:
- 最下面一层是磁盘,放着单个文件或者多个文件构成的数据库文件。
- 用不同的块或页(Page)来划分文件中的内容,页是比较学术的说法。
- 同时文件中还包含页表或者页目录(Directory),类似于文件内容与页与文件位置的索引。
- 在上层内存中,有一个缓冲池(Buffer Pool),里面使用一些缓存算法将文件中的页和页目录缓存在内存中。
- 最上层是执行引擎(Execution Engine),直接将读取页的请求发送给缓冲池,缓冲池不存在就会从磁盘查找,根据页目录定位到页,加载到缓冲池,返回内存中页的地址。之后执行引擎用这个内存中的地址做一些事情。

对于前面提到的内存与缓冲池这一层,想那些学过操作系统或者对操作系统熟悉的人可能知道,操作系统有类似的机制,为啥不通过系统调用使用操作系统现有的机制实现缓冲池呢?例如 mmap() (内存映射文件的系统调用),我们来看下上图所示的这个场景:
- 假设我们磁盘上有四页,物理内存最多容纳两页
- 内存分配是先 reverse 虚拟内存,虚拟内存是很大的,基本用不完。在实际使用的时候,commit 映射实际的物理内存。对于 mmap,是先将文件映射到进程的虚拟地址空间,实际使用到这个地址的时候,如果不在内存中(也就是没有实际映射物理内存),就会发生缺页中断(Page Fault),需要阻塞等待加载这页实际映射到物理内存中。
- 假设我们先读取的是第一页,在虚拟内存中查找我们发现第一页实际没有映射物理内存,发生了缺页中断,阻塞加载磁盘第一页数据到内存
- 之后读取的是第三页,和上一步一样
- 如果这时候我们读取第二页,物理内存不够了,我们需要删除内存中的某一页。这个缓存过期策略,我们是全权交给系统了,但是系统并不知道我们的业务,可能不如我们自己管理做得好
如果我们使用 mmap(),我们就是将这种缓存过期以及内存管理全权交给操作系统来执行了,操作系统并不知道我们的业务场景,以及哪些缓存被过期掉是更加合适的。从应用程序的角度来看,我可能需要读取不在内存中的东西,也就会发生缺页中断,我们可以将它交给另一个线程来做,不阻塞当前线程,这样当前线程就可以去处理其他请求,这样可以增加吞吐量。对于只读的场景这样的优化已经足够了,但是如果还涉及写入的话,这个优化也就不够用了:

因为操作系统被告知要写一个数据,操作系统不会管是否合适(比如批量写,聚合内存块在一起的,减少内存中断)就直接写了。
我们还可以通过一些系统调用来优化:

还有一些系统调用可以让我们来告诉操作系统如何操作 mmap 内存:
- madvise:告诉操作系统你会怎么读取,是随机读取还是顺序读取
- mlock:防止操作系统将某些页与物理内存解绑
- msync:告诉操作系统将某些页刷入磁盘
主流数据库(比如 mysql,Postgres,Oracle,sqlserver 等等)都没有使用 mmap,那些在使用的大部分也正在考虑替换掉 mmap。
所以,我们总结下:

如果你将内存管理全权交给操作系统,操作系统可能会做出一些对于你的性能有损的决策,DBMS 通常都想自己控制内存管理策略,这样就可以带来:
- 根据当前数据库存储格式以及用户请求,决策脏页刷入磁盘的顺序,提高效率
- 根据存储结构以及用户请求,缓存预取提高查询速度
- 根据存储结构优化缓冲过期策略
- 多线程管理
3. 数据库文件存储结构-存储管理(Storage Manager)

数据库其实就是磁盘上的一个或者多个文件,例如 sqlite 整个数据库就在一个文件中,大多数其他的数据库例如 MySQL 则是分了不同文件存储。sqlite 本身就是轻量级的系统,MySQL 这种一般考虑存储性能以及限制等会划分成不同的文件,在现在的文件系统中,文件大小限制已经不太是一个考虑因素了,你甚至可以有超 PB 的文件,但是像是那种老的文件系统例如 fat32 那种,最大只支持 2GB 大小。我们这里提到了文件系统(File System),文件系统其实就是操作系统给我们提供的操作文件的 api,我们通过这些 api 操作文件(文件其实就是一堆存储上面的块)。大部分数据库是依赖操作系统提供的文件系统的,曾经有一些厂商提供了自己原生的文件系统专门用于自己的数据库产品使用,但是这样就丧失了迁移以及部署在云上的灵活性。
我们这里要实现的就是DBMS的存储管理器(Storage Manager)

存储管理器负责管理上面提到的数据库文件,我们在这里会向操作系统发送读和写请求,操作系统会调度这些读写。一些比较高端的系统,还会优化这些系统调度,即在这文件系统上抽象出来一个中介层,在这个中阶层管理本由操作系统的管理的调度,比如这个中阶层知道会有多线程发多请求写互相临近的块,这个中阶层会组合在一起形成一个写请求。这里我们就不做这个了,太复杂了。
在这些文件里面,是由页(page)组织起来的,由一组页组成。我们会以页的维度记录这些页的读写(例如哪些页还有空间可以存储新数据,哪些页里面有脏数据还没刷入磁盘,哪些页已经完全满了)

页其实就是固定大小的数据块,页中存储数据库中所有相关的数据,例如元组数据、元数据、索引还有日志记录等等。但是我们总是尽量将内容存储在单个页中,并且页需要是自包含的,即关于如何解释和理解页内容,所需要的所有信息都必须存储在页本身中。这样,即使丢失任何一页,也不会影响其他任何一页的解析和使用。如果你把元数据存储与元组数据分开存储在不同的页,如果元数据页丢失或者损坏了,那么元组数据页也就无法解析了。这种自包含的设计,对于容灾更好。
虽然不同种类的数据(例如元组数据、元数据、索引还有日志记录)都是存储在页中,但是在同一页内一般不会存储不同类型的数据。有一些研究型的数据库可能会在同一页中存储不同类型的数据,但是大部分系统都没有这么做。
每个页都有唯一的标识符即页 ID(Page ID)。我们使用这个唯一标识符形成一个中间层,在这个中间层维护 Page ID 与实际存储的文件的位置的映射,通过 Page ID 就能定位到对应的文件位置并读取这个页。同时如果我们移动了页(例如我们想扩展存储,压缩存储使用等等),Page ID 不会变,只是修改了文件位置,这比直接使用文件位置存储要方便很多。这样 DBMS 的其它层就不用关心这个,只记录 Page ID 就可以,我们在修改页位置的时候不用告知其他层同时修改。

我们有很多不同的层面有页这个概念:
- 硬件存储页(Hardware Page):通常是 4KB。也就是如果你写的数据在 4KB 以内,那么就能保证原子性,不会发生写了一部分掉电导致只写入了一部分成功的情况,只会要么全成功或者全写入失败
- 操作系统页(OS Page):通常也是 4KB
- 数据库页(Database Page):通常是 512~16KB,例如 MySQL InnoDB 页大小默认 16KB,目前 8.0 可以配置成 4KB 8KB 16KB 32KB 64KB。在一些比较高端的系统,你甚至可以对于不同类型的页设置不同的页大小,例如元组数据页大小比较小,索引页大小调整的比较大。
将数据库页调大,那么单页就可以保存更多的数据,那么后面会提到的页目录大小就会降低,页目录是用来找所有页的位置的存储,一般会一直存在于内存中,页目录越小,那么 CPU 缓存命中率越高。并且更多的数据在同一页上面,读取数据也是一页一页读取,这样对于缓存预取也有好处。但是相应的,写入也是一页一页刷入,带来的写入消耗也更大。这就是为啥那些商用的数据库允许你调整页大小的原因。

那么如何设计文件页结构呢,一般有三种:
- 堆文件组织(Heap File Organization):这是最常用的,我们也会主要研究这种。每种关系存储到一个单独的文件,文件中的记录是无顺序的。
- 顺序文件组织(Sequential File Organization):所有文件里面的记录内容,都按照记录的某个属性值的一定顺序排序好。
- 哈希散列文件组织(Hashing File Organization):使用记录的某些属性计算哈希值,决定存储在文件的哪个位置。

数据库堆文件是一个无序的页面集合,其中元组数据可以随机顺序存储。其实关系模型中,也没有对元组定义任何顺序。我们所要实现的就是针对页操作的增删改查 API,以及遍历所有页的 API。
同时,我们需要一些元数据追踪哪些页还有剩余空间,这样在我们需要插入新数据的时候就能快速定位到在哪里插入。
一般我们通过页目录(Page)这种方式设计堆文件中的结构,但是首先我们先来通过链表(Linked List)设计下文件结构来看下为何这种方式是愚蠢的。
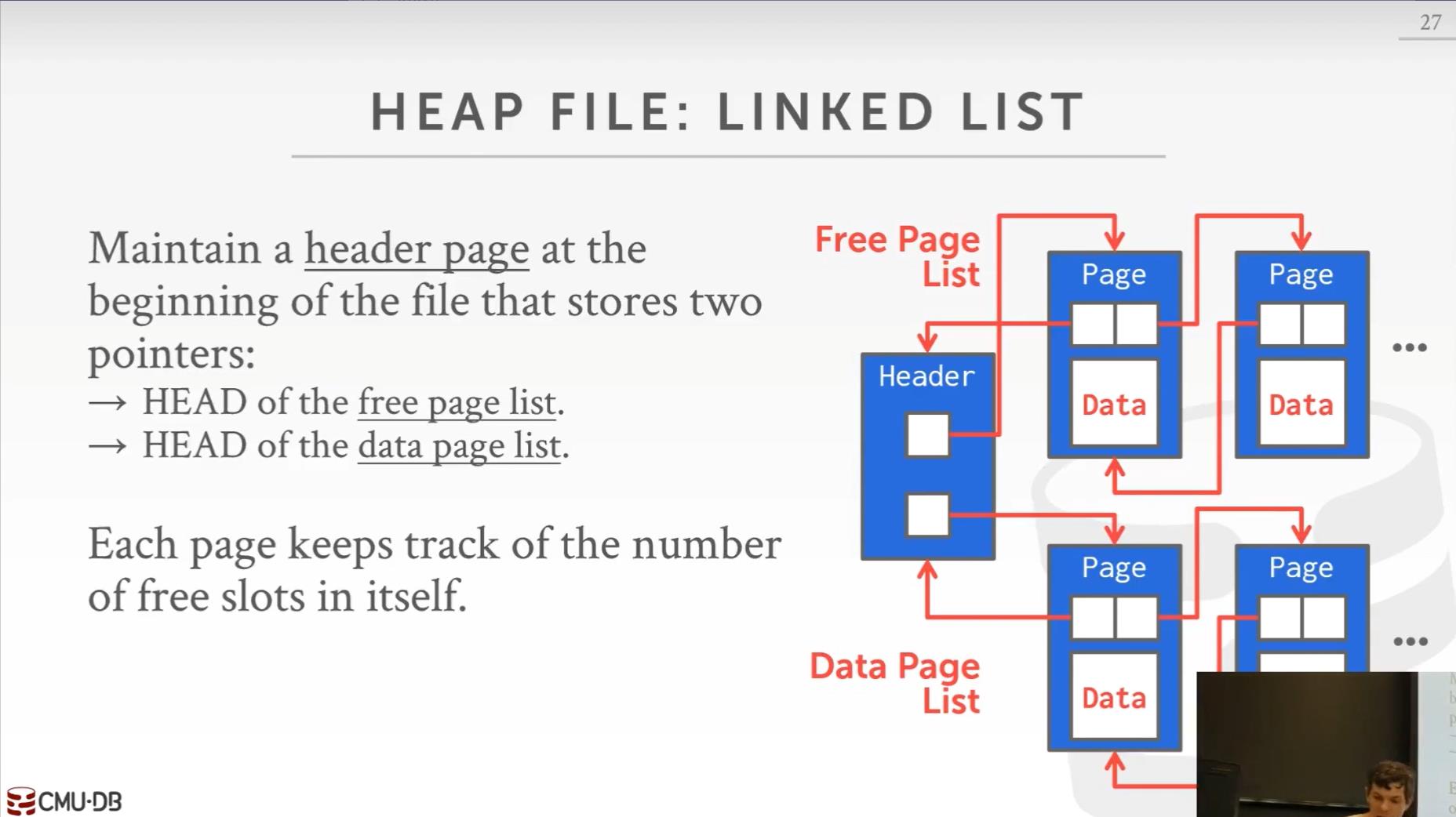
如果使用链表设计的话,一般我们会维护一个 Header 页,在这个页 里面我们维护两个指针,一个指针是指向所有还有剩余空间的页链表的指针,另一个指针指向的是已经被填充满的页链表指针。这两个链表都是双向链表,我们可能顺序遍历也可能逆序遍历:顺序遍历一般用于找合适的位置比如找还有足够容纳我们要插入数据空间的页,逆序遍历一般用于移动。这并不是一个比较好的设计方式,主要是插入与更新的效率比较低

这是使用更多的设计方式,即页目录。我们维护一个专门存储目录的页,在这个目录中维护页 ID 到具体文件位置的偏移量的映射,可以简单把它理解成一个 key 为页 ID value 为文件位置偏移的哈希表。并且在这里还会维护页的空闲空间信息,这样在插入的时候,我们可以直接通过页目录直接定位到要插入的页。但是这样也带来了原子更新的问题,即页的空闲空间信息与插入数据是否在一个原子操作内。但是由于这个两个页的操作,硬件层面上我是很难保证两页更新是原子性的,所以我们需要额外的机制在数据库重启的时候检查是否有这些未完成的写入,这在后面讲恢复与日志的章节的时候会说到。
4. 页布局(Page Layout)

每个页都有页头(Header),在 Header 中一般包含:
- 页大小
- 校验和(CheckSum):这个可能会用来检查是否有未完成的写入(例如写一半就宕机了)
- DBMS 版本:创建这个页的数据库管理系统的版本,这个一般用于向前兼容使用,比如在某个版本后页布局发生了变化,我们可以通过这个 DBMS 版本让这个页的解析走不同的分支。
- 压缩相关信息(Compression Information):如果对页面做了压缩,需要标注一些信息,例如使用的算法,是 lz4 还是 gzip 等等。
- 事务可见性相关信息(Transaction Visibility):对于实现事务可见性需要的一些信息,例如是哪个事务修改了这个页的内容,以及修改后的内容在当前时间点对于谁可见等等。
页需要是自包含的,即关于如何解释和理解页内容,所需要的所有信息都必须存储在页本身中。这样,即使丢失任何一页,也不会影响其他任何一页的解析和使用。如果你把元数据存储与元组数据分开存储在不同的页,如果元数据页丢失或者损坏了,那么元组数据页也就无法解析了。这种自包含的设计,对于容灾更好。

在页内部,我们有两种方式存储元组信息:
- 面向元组存储(Tuple-oriented):即页中存储元组的数据
- 面向日志存储(Log-oriented):即存储修改元组的日志而不是元组数据本身
首先我们来看看面向元组的存储方式设计,首先看一个很糟糕的设计:

假设所有元组的字节长度都是一样的,那么实现方式比较简单,基本就是在头维护一个元组数量(这样我们就能直接跳转到要插入下一个元组的文件位置偏移,如果元组大小不一样,那么这里维护的就是要插入的文件位置偏移),如果有新的元组插入,则根据元组数量计算出要插入的位置插入然后更新头部计数。当需要删除一个元组的时候,假设删除的是 Tuple 2:

我们可以把 Tuple 2 本来占用的空间标记为未使用,而不是将 Tuple 2 之后的所有元组数据都向前移动。但是这带来了其他的问题,即存储碎片:
- 我想再插入新的数据的时候,假设所有元组的字节长度都是一样的,我可以插入到原来 Tuple 2 的位置,但是我怎么知道这个位置有空闲的空间呢?这样就需要引入额外的记录
- 如果元组的字节长度不一样呢?就更麻烦了
所以这种设计很不好,没人会这么做。一般采用槽页(Slotted Pages)这种设计:
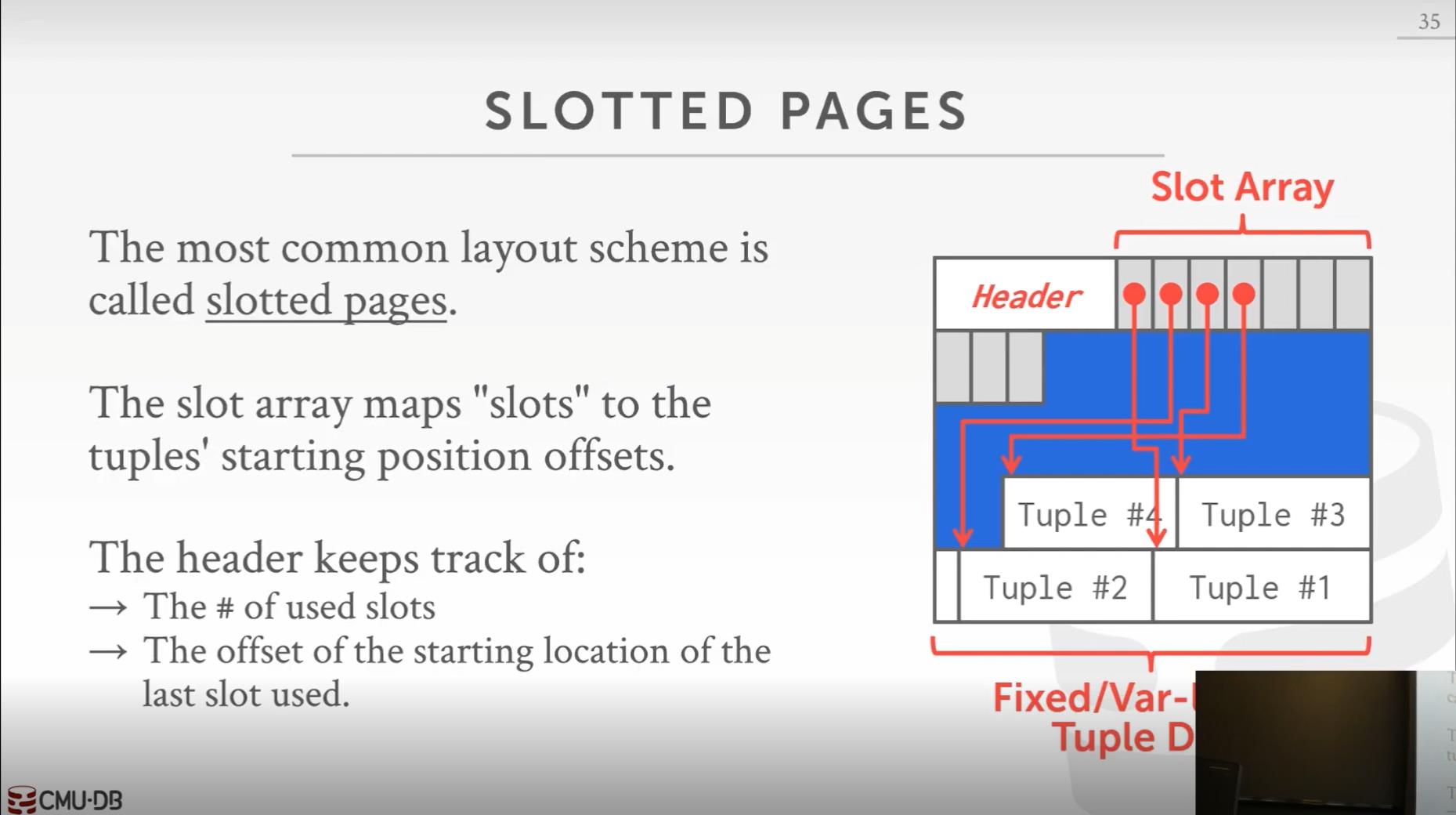
这种设计被大部分数据库所采用,虽然在细节上有些不同,但是大致是这么个结构。在开头还是前面提到的页头,之后跟着两种存储结构
- 槽数组(slot array):从前向后写,在这个数组中的元素记录所有元组在文件中的起始位置偏移。槽数组可以解耦元组位置与外部访问,相当于前面提到的间接层。我们可能在页内部移动元组(比如更新元组导致元组长度改变会标记删除原始元组在最后追加新的元组数据),通过这个槽数组外部就可以不关心这个位置变化了。
- 实际元组数据:从后向前写
思考下:我们是否可以在这一页中存储来自于不同表的数据呢?实际上没有人这么做,首先是需要额外的元数据记录每个元组所属的表,然后是表数据访问一般具有局部性,即我们访问表的某一条数据,那么之后这个表这个记录他周围的数据也可能稍后会访问到,把他们放在同一页里面一起读取效率更高,如果在一页中混合了不同表的数据就丧失了这个局部性。
还有就是如果一个元祖或者一个元祖的某个属性数据大小超过一页的大小,那我们应该怎么做?这个下节课会讲到。这节课还是假设某个元组的数据只会存在于单页上。
5. 元组结构(Tuple Layout)
元组其实就是一个字节序列,DBMS 负责解析这个字节序列。

每个元组都有一个头,包含元组的元数据,例如:
- 元组的长度
- 可见性信息(Visibility info):例如是哪个事务那个查询最后修改的这个元组,其他事务或者查询根据这个信息以及事务隔离级别设置来决定是否能看到这个元组。
- NULL 位图(NULL BitMap):通过位图标记哪些列是 NULL 值
我们一般不将模式信息(例如有哪些属性列,列是什么格式的数据,是否可以为 NULL 等等)存储在每个元组的头部,这样会冗余太多数据造成存储浪费并且一页内包含更少的数据导致更新与读取效率下降。

然后是元组数据,我们通常按照创建表语句中的属性顺序去存储元组数据,大部分系统是这么做的。有的系统会对于属性进行重排序,让它能更适应内存对齐(例如 8 字节对齐)增加访问效率(内存与磁盘存储访问一般都是内存对齐的访问)。
DBMS 的其它层,如何在这种存储结构下定位一个元组的数据呢?

一般所有元组都会被分配一个唯一 ID,这个 ID 中会直接或者间接包页 ID 信息和槽(或者偏移量)信息,直接包含即从 ID 中直接就可以看出页 ID 以及槽信息,间接包含则是需要解码或者查询另一个元数据表来解析出页 ID 以及槽信息。可能还会包含文件位置信息用于定位去哪个目录或者文件位置去寻找页目录定位页 ID 对应的文件位置偏移量等等。这样,我们可以通过页 ID 查询页目录找出页对应的文件以及偏移量,根据槽信息读取页中的槽数组找到元组的位置进行读取。
微信搜索“干货满满张哈希”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
- 知乎:https://www.zhihu.com/people/zhxhash
- B 站:https://space.bilibili.com/31359187

以上是关于CMU 15-445 数据库课程第三课文字版 - 存储1的主要内容,如果未能解决你的问题,请参考以下文章