Kafka日志及索引文件
Posted 绝世好阿狸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka日志及索引文件相关的知识,希望对你有一定的参考价值。
每一个分区一个文件夹,一个分区对应多个文件。当满足一定条件后,会生成新的文件。每一个文件叫做一个日志段,每一个日志段会关联两个索引文件,一个是偏移量索引另一个是时间戳索引。日志段以本日志内的第一条消息的偏移量命名。段内的日志偏移量是相对偏移量。
一个分区只有最新的日志段是可写的,其余的都是只读。
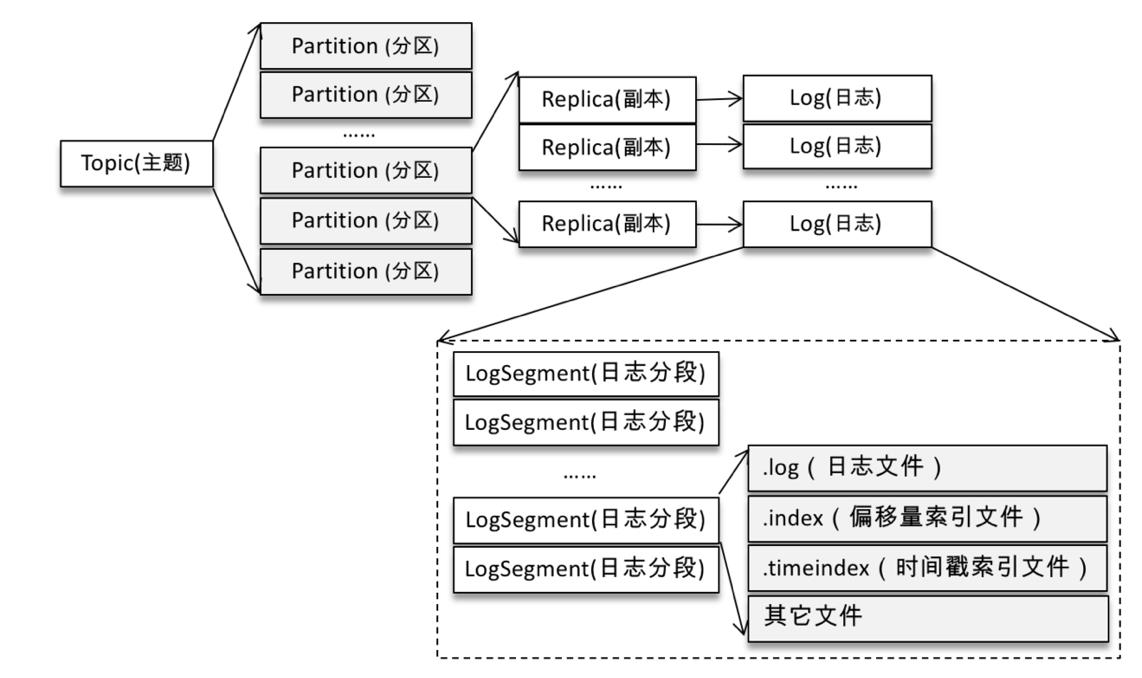
索引文件:并非每一条消息都对应一个索引项,而是积累到一定数量后,插入一条索引项。
1.偏移量:按照偏移量排序,存放的是偏移量到物理位置,查找时二分法查找。
2.时间偏移量:按照时间戳排序,查找时二分法查找。当然还需要再通过偏移量索引查找一次。
日志段分割的时机
1.日志文件大小;
2.日志文件最大最小时间戳大于一个阈值;
3.日志文件最大最小偏移量大于一个阈值;
4.索引文件大小大于一个阈值;
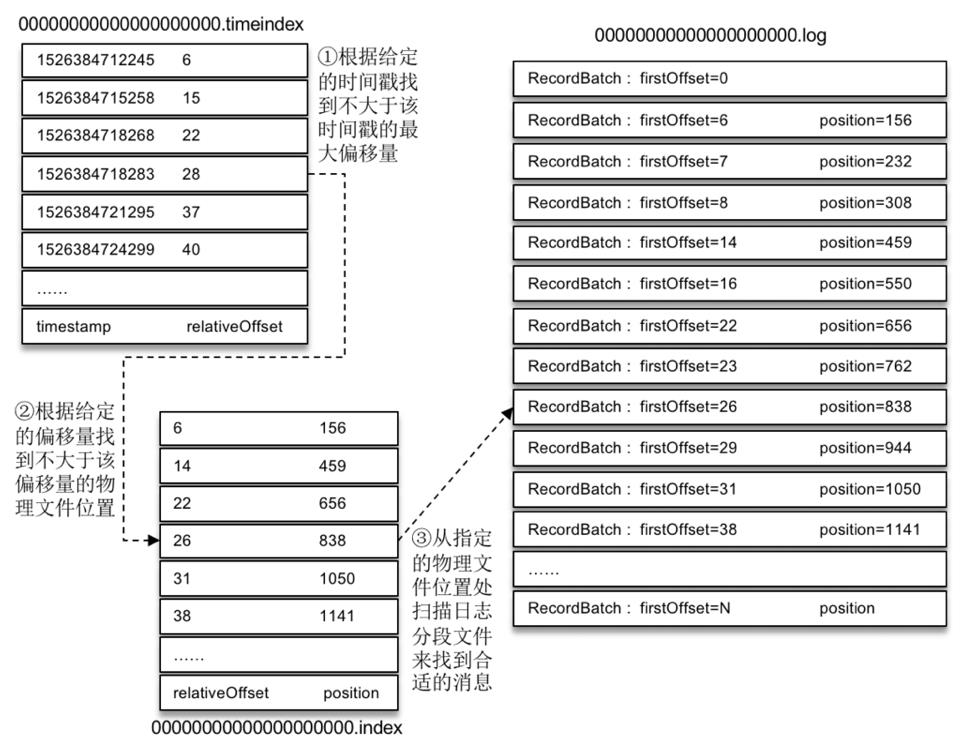
偏移量索引

来一个示意图:

具体如何查找?使用二分法查找index文件,定位到position,再从position开始的batch里顺序查找。
当然这里是已知索引文件的情况下的过程,那么如何定位到索引文件?kafka在内存中使用跳表结构存储所有的索引文件名(理论上二分也行)。
时间戳索引

时间戳索引没有存物理位置而是存了偏移量,所以定位消息时,还得再查询一次偏移量索引。
(注:图片均来自掘金小册)
以上是关于Kafka日志及索引文件的主要内容,如果未能解决你的问题,请参考以下文章