操作系统进程与线程之线程篇
Posted tab_tab_tab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作系统进程与线程之线程篇相关的知识,希望对你有一定的参考价值。
1.1为什么要引入多线程?
从多个角度去分析下
- A.从用户角度分析 ,有得程序员需要写一个经常阻塞(比如I/O的程序),没人希望自己程序阻塞一次就挂起。
- B.从系统设计角度分析 ,许多系统搞出来的线程切换的速度都是远远大于进程切换速度的。而且线程切换好处是Cache里面的数据可以不抛弃,而进程切换后必须抛弃Cache里的数据,呃,总之是快…具体的差别请看下面
- C.从硬件上分析 ,多CPU环境下多线程是具有优势的。呃,这里我保留意见,因为CPU亲和力的存在使得进程也好线程也好都是尽可能在一个CPU上调度的,当然linux 有个叫CPU亲和力的东西
并且有两个设置亲和力函数
int sched_setaffinity(pid_t pid, size_t cpusetsize,
cpu_set_t *mask);//进程CPU亲和力
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize,
const cpu_set_t *cpuset);//线程CPU亲和力
根据我分析代码,pthread_setaffinity_np函数是绑定一个线程到cpuset这个参数表示的N个CPU上.这一个线程可以绑定到第0个、第1个……或第N个CPU上.我理解的对吗
从用户角度分析的举例
- A.服务器程序
- B.备份程序
- C.后台文本插入程序
以上的都是为了防止阻塞而引入的,很多时候,他们是为了友好的界面设计,比如文本编辑器。由于用户无法忍受在输入文件时候不能用鼠标,所以才有一个线程专门用于与用户交互;用户也无法忍受修改了一小小的文件内容,然后卡了半天,所以才有一个线程专门在后台专门疯狂计算;再比如用户无法忍受输入半天内容因为断电而彻底没了,所以才有一个专门定时备份的线程
现在考虑如何勾搭一个Web服务器。
- A.考虑存在多线程技术的情况下,使用Reactor设计模式,主线程负责处理链接和分派工作。工作线程负责读写交互。
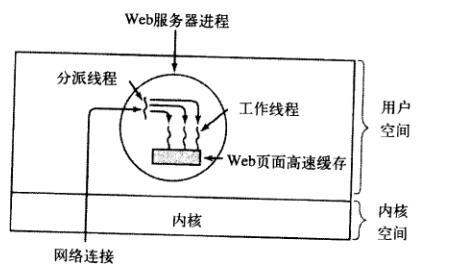
对应的伪代码:

-- B.考虑不存在多线程技术的情况下 。
- -- 设计一:只有一个主线程负责所有的工作 。,包括数据发送,每次只能处理一次链接
- -- 设计二:使用read的非阻塞版本 。,每次调动之前看看是否请求的东西已缓存好,如果不是,那么就使用一个非阻塞的磁盘读取系统调用。然后继续循环,这个过程中,每次计算都产生一个状态被保存,存在一个状态不断变化的集合,实际上我们是在模拟了多线程,但是这个过程给编程带来极度大的困难。而这个模型称之为有限状态机模型。
下面是三种模型的比较

1.2经典线程模型
矛盾:线程共享同一个地址空间,意味着线程可以修改其他线程地址空间上的函数堆栈(实际上这个是很难的,因为线程是同一个用户,而不是来自其他不同用户)
与进程的同一特性:具有自己的堆栈,为什么不共享堆栈?因为它们每个线程都得有自己的执行过程,如果使用同一堆栈,就极度难释放和开拓新的函数栈帧了。
进程与线程的内容
多线程中fork下场:在Linux中,fork的时候只复制当前线程到子进程,在 fork(2)-Linux Man Page中有着这样一段相关的描述:
The child process is created with a single thread–the one that called fork (). The entire virtual address space of the parent is replicated in the child, including the states of mutexes, condition variables, and other pthreads objects; the use of pthread_atfork(3) may be helpful for dealing with problems that this can cause.
也就是说除了调用fork的线程外,其他线程在子进程中“蒸发”了。
这就是多线程中fork所带来的一切问题的根源所在了。之所以要这样处理,是因为太多要处理的东西了,如果连线程都拷贝,假设有个线程专门用来蹲输入的,如果你把这个线程也拷贝了一份,那么最后你的输入是给两个人还是只给一个人??还有一个原因是共享数据结构,假设两个线程共享一些数据结构,一个修改了另外一个怎么处理,,,,太蛋疼了,所以linux系统干脆采取策略只拷贝调动fork的线程的状态,但是这样也会带来一系列的问题,比如这个线程的锁还在其他线程手中呢……………子进程只拷贝了带上枷锁的线程,而持有锁的线程却没有拷贝到。
那么如果fork后再pthread_create呢?、
1.3线程API接口
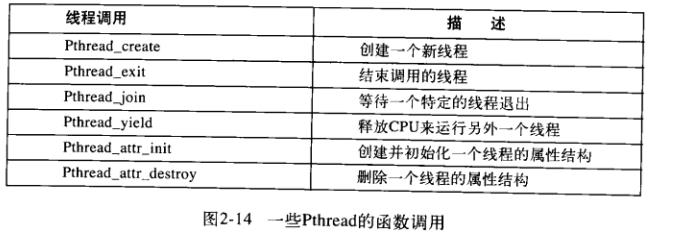
其中倒数第三个pthread_yield特别重要,因为很多用户空间模拟出来的线程是对内核空间不可见的,一个线程执行了一段时间后可以自己主动调用这个函数来释放CPU所有权,让其他线程跑。
1.4线程实现的方式
1.在用户空间实现
不是所有的操作系统都支持线程,有得操作系统至今依然不支持线程,而支持线程和不支持线程的系统,或者说内核线程和用户线程最大的架构上的区别是:
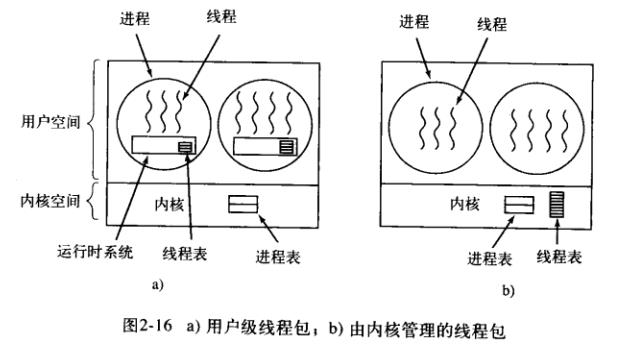
由于对内核而言是完全不知道用户级线程这回事的,因而线程库必须得在用户态空间下进行线程的维护,呃, 这样带来的好处无疑就是线程切换的速度非常快(因为原因一:不用陷入到内核态中去,仅仅更新一下堆栈寄存器和程序计数器 就可以让其他线程跑起来了。原因二:不需要内核线程的陷阱,不需要上下文切换,不需要更新内存中的高速缓存),而且还有一个好处就是用户是可以在制定自己的线程调度方法。呃,总结一下把。
用户态线程的好处:
优点1:可以在不支持线程的操作系统上实现
优点2:线程切换的速度非常快
优点3:是用户是可以在制定自己的线程调度方法
那么对于用户态的线程的操作而言,对于以下操作是如何实现的呢?
其中阻塞操作最为恶心,几乎可以称之为这是一个极度恶心的操作,因此它也是最难模拟的。这时候我们要深刻并且虔诚记住,内核是完全不知道用户线程的存在的,也就是说一个线程调用了阻塞,那么整个线程组都会阻塞,这是极度不合理的。内核使用的是类似包装器的概念。 = =简单来说就是用一个用于确定一个或多个套接口的状态的函数select函数,其中对于select函数对每一个套接口,调用者可查询它的可读性、可写性及错误状态信息。这样就可以知道该线程什么时候阻塞完成,而且不会阻塞到整个“线程组”
切换:保存当前线程的寄存器,再把新的线程对应的寄存器装载入来,把堆栈寄存器和程序计数器一换,那么就可以完全线程的阻塞操作了。
阻塞:包装器+select。 = =简单来说就是用一个用于确定一个或多个套接口的状态的函数select函数,其中对于select函数对每一个套接口,调用者可查询它的可读性、可写性及错误状态信息。这样就可以知道该线程什么时候阻塞完成,而且不会阻塞到整个“线程组”
页面故障:类似阻塞过程处理过程!
退出:调动pthread_yield,让线程切换 注意,这是多进程没有的步骤 !
最后说一下这种用户态线程组的缺点:
1.对于线程调度,除非是线程主动调用pthread_yield会引起切换,其他情况下很难如系统线程一样,拥有着一个时钟让它去进去时钟中断。也就是线程调度 的问题。虽然一定程度上是可以通过定时向CPU请求时钟中断来解决,但是这样的解决方法是极度生硬并且可能极大损耗性能的。也许就也许是后来的混合型线程产生的原因吧。。。。
2.对于大量的IO阻塞情景,也许使用用户级线程是个不错的选择,可是当是CPU密集型的操作呢???你觉得开多个用户线程去解决一个大型矩阵相乘问题,或者是你觉得具有极大的相互独立性的一个可以分而治之的问题时候,你却根本没有发现,这个用户级本来就是用一份内核给的线程时间片来执行N个线程的操作,一方面总的时间片没有增加,另外一方面线程的切换,同步之类也增加了时间损耗。你们觉得这样有意义么。这就是用户态线程第二个致命性的缺点。对于IO密集型线程能够提高性能,但是对于CPU密集型操作就看不到好处在哪里.,.,
2. 在内核空间实现
在这种实现策略中,带来的好处和坏处也是显然得知的。参考上面的图2-16不难得知当线程在内核空间实现时候,那么上面讨论的复杂的阻塞也好,页面故障也好,时钟中断也好。他们都是比较容易处理的,之所以我们觉得复杂的阻塞也好,页面故障也好,时钟中断这些东西让我们无处下手,而在内核空间能轻易下手处理。这事因为核心的原因是这个线程所处的地位和身份不一样 。
计算机模拟着我们的现实世界,举例子来说,操作系统就像是一个政府,它拥有着绝对的权利,拥有绝对的话语权,没有操作系统做不到的事情。但是申请让政府帮忙干活也是极度繁琐的,就像是去进行系统调用一样,代价是极度昂贵的,它会放弃当前进程的剩余时间片,还会引发好多的一连锁的反应,比如说会置CPU里面的高速缓存为过期状态。
内核级的线程处于的位置就相当于处于政府中的工作人员一样,用户级的线程处于的位置就相当于在一个企图模仿政府体系的企业工作人员一样。两者的地位和能够使用的资源是不在同一个档次上的。
而带来的缺点也是显然而知的,内核态实现线程,那么线程的创建和销毁过程代价是比较昂贵的。因此有得内核级线程使用的是比较廉价的做法,就是回收时候标识该线程项为不可用,等到要创建时候,再启动一个旧的线程。这样比较廉价点。
内核级线程可以处理大部分情况,但是还是不能处理相当一部分的事情。
1.一个多线程进程创建新的进程将会怎么样?
这个问题来说,对于linux系统采取的做法是只拷贝fork线程所在的堆栈空间,不过这样还是有很多问题滴。。。。具体的请看本人的另外一篇文章《操作系统进程与线程之进程篇》
2.如果两个线程注册了同样的信号,将会怎么样?这里注意一点,信号是发送给进程而不是线程的,意味着所有属于该进程的线程组是共享这个信号的
这儿问题的话,可以说是为什么进程间通信使用的信号量与线程间通信所使用的信号量是两组不同的函数的原因。。。。。或者这样说吧为了解决这个问题,linux系统后来引入了一套线程间信号量通信的手段。
3.混合实现
一定程度上是受到数学家的影响,假设模型A,B分别具有一些各自没有的优点,还有一些各自没有的缺点。这时候数学家就很喜欢采取一种叫做加权平均一下的技术来建立一个新的模型C。而这个思想被应用到线程模型就是混合实现线程这个玩意了。混合线程综合了用户线程和内核线程各自的优缺点而引出来的东西,优点和缺点几乎都是两者的一个加权平均。

以上是关于操作系统进程与线程之线程篇的主要内容,如果未能解决你的问题,请参考以下文章