科学研究设计六:有效性威胁
Posted somTian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了科学研究设计六:有效性威胁相关的知识,希望对你有一定的参考价值。
说明
这是Bangor University 2007年School of Sport Health & Exercise Sciences的教学讲义,大家可以在这里查看原课程的讲义
课程目录
为什么要看这个?
这个在我看来,适合大学生或者刚入学的研究生学习,主要为了提高科学素养、培养科学研究的思维以及一些研究设计中要考虑的很多细节问题。虽然里面没有很多高超的方法,而且课程也是十年前的,但是里面对于科学的理解以及思考问题的思维方式确实值得刚进入科研这条不归路的人学习。
格式说明
- 标题格式都按照markdown排版的,但是标题之间的关系可能没有排好,主要是参考了原课程网站的标题设计
- 书中一些专有名词或者大牛们说的话都没有翻译,以防止因为我的问题导致误解
- 名人名言和我自己的理解都是用引言格式标注的,不同的是,大牛们的话是英文,我自己的理解是中文
- 因为课程中有问答环节,问题我会用加粗来标识,问题的答案一般会用斜体来标识
最后一句话
因为本人英文水平有限,有些话翻译得可能很别扭,有能力的话建议大家去看原网址。

内部有效性和外部有效性 Internal and external validity
在第四课(实验设计)中,我们介绍了潜在的自变量问题:可能会有一些导致因变量变化的非受控因素。这些因素被称为研究的内部有效性威胁(threats to the internal validity)。因此,内部效度与研究的设计在多大程度上使我们将因果性归因于自变量并排除了潜在的其他解释。研究者的任务是设计研究,排除合理的替代解释,以确定是造成这一效应的自变量。
内部有效性就是说,研究的目的就是为了确定因变量的变化只受自变量影响,排除其他的不受控因素。国内也有人翻译为内部效度是因变量和自变量之间关系的确实性程度,是实验结论的真实性。
研究有效性的第二个方面涉及研究设计在多大程度上允许我们将结果推广到非抽样样本的人群,或不同环境或不同时间的类似人群。这被称为外部或生态效度(ecological validity)。外部效度是关于应用于现实世界的结果是否有意义。
外部有效性,或者叫外在效度(external validity)是指研究结果的代表性或普遍性。具体说来,就是指研究结果是否可以推广到类似情景中去的程度。
内部有效性(Internal validity):研究设计在多大程度上可以将因变量的变化归因于自变量的变化?
外部有效性(External validity):我们可以在多大程度上将研究结果推广到其他人或环境?
在本课中,我们将详细研究有效性面对的主要威胁以及不同的研究设计如何对其进行控制。从一开始就要注意到,需要考虑研究的特定环境来评估不同有效性威胁的可能性。在某些情况下,特定威胁可能根本不适用。
对有效性的威胁可以大致分为三类:与时间流逝(passage of time)相关的威胁,与参与者选择( selection of participants)相关的威胁以及与测试和操纵相关的威胁。后一类包括反应性安排,将分开处理的多种威胁。
与时间流逝有关的威胁 Threats relating to the passage of time
与时间的流逝相关的威胁无论何时使用重复的措施设计都是潜在的问题。 这个类别有五个主要的威胁:成熟(Maturation),历史(History),死亡率(Mortality),仪器(Instrumentation)和统计回归的平均值(Statistical regression to the mean)。
成熟(Maturation)
这种威胁与时间的推移有关,例如发展变化,衰老,饥饿,疲劳等。例如,假设一位教育研究人员有兴趣评估8岁儿童使用新的阅读方法的效果。 研究者考虑使用一个单一的组,前测(pretest)后测(posttest)设计:
O1−−−−−−−−−−−−−−−−−−X−−−−−−−−−−−−−−−−−−O2
对一类儿童的阅读能力先进行评估测量,进行一段时间的新方法阅读的课程,再对阅读能力进行评估测量。 这个设计有什么问题?
很明显,不论具体的教学方法如何,孩子的阅读能力都会随着时间的推移而改善。 因此,在前后测量之间观察到的任何改善可能是由于人本身成熟:儿童自身认知的变化。 新方法可能是有效的,但是我们不能把它的影响与那些已经发生的影响区分开来。
意识到他的错误后,研究人员决定采用随机前测后测控制组设计:
R——————O1——————X——————O2R——————O3——————X——————O4
儿童被随机分配到两组中的一组。 一组接受阅读课程,另一组接受“标准”教学方法。对这两个组的阅读能力进行前测试和后测试。 这是如何控制成熟的影响?
假设结果提示新的教学方法优于标准方法:

两组阅读能力都有所提高,但接受新教学方法的实验组提高得更多。由于孩子是随机分组的,所以应该在阅读能力和其他相关因素上应该是相同的。因此,任何发生的成熟的变化将同样适用于这两个群体。对照组的改善是由于正常的年龄变化,而实验组的更大的改善则可归因于新的教学方法,只要在操作中没有其他潜在的自变量(有效性威胁)。例如,管理新教学方法的人只是一个更好的老师,或者比使用标准方法课程的人更有动力,更热衷于使用新方法的前景。正因为如此,实验组的人员才能以更快的速度发展。那你怎么能避免这些潜在的影响因素呢?
要想完全避免是很困难的!当然,你可以让同一位老师使用这两种不同的方法教学,但是再一次,他们可能会更有动力使用新方法。 在某些情况下,比如医药领域建立的研究可以使实验者不知道他们正在提供哪种治疗以避免上述提到的问题。例如,在评估新药疗效的医学研究中,采用双盲(double-blind)程序是正常的:参与者本身和实验者都不知道参与者是否正在接受药物(或药物的剂量)还是安慰剂(即没有药效的试剂)。但是显然,在这个例子中你不能用这个方法。 老师怎么会不知道他们使用了哪种教学方法? 如果你能想到一个方法来解决这个设计问题,你将会对科学做出重大贡献!
成熟(Maturation)我们可以理解为参与实验的人自身的年龄的变化会导致认知等的变化,如果试验周期长,这种变化是研究者无法避免的。现在面对这个问题,主要的方法就是使用双重差分模型(difference-in-differences model),就是第二个改进的设计。这在预测问题中经常出现,比如我们要考虑汽车的销量,那么我们第一个要避免的就是随着年份的增长,经济形势的好转,汽车销量自然是增长的,首先要将这个原因排除在外。
历史(History)
历史是指除了可能影响因变量的实验操作之外,在事前和事后测试之间发生的事件。成熟(maturation )效应是参与者自身发生的事件(happening within participants),历史效应是除了实验人员的干预因素外,发生在参与者身上的事件(happening **to **participants)。
举一个例子,假设一家大公司决定推广健康饮食,减少吸烟和增加劳动力的体力活动。为推行这些与健康有关的行为而给予工人财政奖励。该方案通过测量实验之前和之后随机抽取的工人样本的饮食,吸烟和活动习惯来评估。在这里,我们有一个单一的组,再次进行前测后测设计。假设在该计划运行的同时,地方卫生当局开展了针对整个社区的重大健康促进举措。这些举措包括提供关于健康生活方式的信息和建议,通过当地超市,休闲中心,媒体等宣传。在这里,我们有一个可能影响公司方案结果的历史事件。劳动力队伍中的任何健康行为的改善都可能是由于他们所面对的更广泛的社会的健康促进举措,而不是公司的财务激励。
随机对照组设计(有或没有预先测试)的历史威胁完全相同,正如他们控制成熟的影响一样。如果这些组通过随机分配进行了前测,那么任何历史效应都应该平等地影响这些实验组。因此,除了由于历史事件而在对照组中观察到的任何变化之外,实验组中的任何变化都可以归因于自变量。
这个已经不算是什么大问题了,随机对照组就可以避免这个问题
死亡(Mortality)
死亡威胁与前期和后期测试之间实验参与人员的退出有关。我们已经在采样课上遇到了这个问题。退出可能与留在研究中的参与者有着系统的不同。因此,当参与者退出时,样本的性质发生变化。在一个单独的小组研究中,这意味着在预测试开始的样本至少可以合理地代表感兴趣的人群,但是在后测中可能不具有代表性。例如,假设进行一项研究来检查激励强化治疗对坚持使用单一组的锻炼计划的效果,即前测后测设计。没有动力的参与者可能会退出,留下更多积极的参与者。任何明显的锻炼增加都可能是因为最后离开的参与者无论如何都有强烈的动机去坚持这个计划,与治疗可能无关。
但是,我们已经讨论了单组设计薄弱的两个原因,还有更多的原因。一个随机前测后测的对照组设计成什么样?在这里,和前两次的威胁一样,随机化也是为了弥补这个问题。如果参与者被随机分配到组,那么他们应该在动机和任何其他可能导致推出的因素上是相同的。因此,如果有推出的情况,同一类人应该会从两个群体中推出。
然而,死亡仍然可能会出现问题,特别是如果治疗费时或需要代表参与者的努力。假设我们使用随机前测 - 后测对照组设计实施了研究,以评估动机治疗对于坚持锻炼的有效性,并且使用包括参加四个一小时长的激励增强课程,另外还提供了一个遵守数据的锻炼课程。对照组不需要参加任何这样的课程,仅仅是练习课程。尽管这两组在初始随机化方面动机因素是等同的,但由于涉及的时间和精力,动力较小的参与者可能会退出治疗组。因此,治疗组缩小的方式与对照组无法比拟。对照组中有更多或更少动力的个体在后测中保持混合,但实验组仅包含更多有动力的个体。因此,在后测中治疗的任何明显的优势可能仅仅是由于参与者的动力而不是治疗。
所以,死亡率只有在群体之间没有差别死亡(differential mortality)(即不同类别的人从不同群体中退出)时才被控制。如果你做了这项研究,想想可能会有什么后果,而且你遇到了退出,但没有差别死亡率。这可能导致其他的问题吗?
这里的问题是,虽然这些群体的性质可能没有差别,但它们将会发生变化。 假设有些人从两组中推出,人数相似,因为他们觉得练习课太难了。 现在对操控变量的任何明显的优势只适用于那些没有发现这些课程太难的人(比如更有动机的人,更合适的人,或者已经习惯了的人等等)。 这意味着我们不能把结果推广到为动机不强,不适应,不活跃的人。 那么在这种情况下,我们就有一个外部效度的问题:不能将我们的研究结果推广到其他类型的人。
仪器(Instrumentation)
通常情况下,这是一个更直接的威胁。当测量因变量的方式在试验前和试验后或者在不同组之间有变化时,这是一个问题。这可能是由于仪器的校准错误,使用不同的仪器,或者由实验者以不同方式使用仪器所致。
在我以前作为医院手术室技术员时,我曾经测试过五个电子血压计,都是同样的品牌。他们给了五个不同的读数,变化多达10毫米汞柱!假设我在研究中使用它们来评估放松对血压的影响。我使用一个组,前测后测设计。在预测试中,我碰巧使用了一个低于在正确的值5毫米汞柱的测量仪,而在后测中我使用了一个测量值超过正确值的5毫米汞柱的测量仪。即使实际上治疗已经使血压降低了5毫米汞柱,我也不得不得出结论,放松实际上会增加血压!因此,教训是,确保您使用的是正确校准的仪器。
如同观察性研究,当研究人员本身就是仪器时,仪器也可能是一种威胁。假设进行一项研究来评估训练教练是否给予正面的反馈,实际上是增加了他们对正面反馈的使用的机会。我们通过观察员在训练期间记录实例来评估提供的积极反馈,然后我们给予治疗,并再次观察教练,看看他们是否使用更积极的反馈。假设实际上培训没有效果,教练对积极反馈的使用不会增加。你能想出为什么观察者可能会在后测中记录更多正面反馈实例的原因吗?
观察员可以更加熟练地注意和记录正面反馈的情况,因为他们有更多的观察教练的经验,因此即使实际上没有变化,他们在后测中也会比在前测中记录更多的实例。 由于这个原因,观察性研究通常使用多个的观察者,并在观察中训练他们,直到他们达到预定的一致性水平(回顾测量课的评价者间信度)。
这种现象同样出现在数据分析中,特别是如果你的代码中需要随机值(比如在切分训练集和测试集时),请确保每次实验的随机值是一致的。另外,如果你需要记录实验时间,请确保你的计算机两次实验都在相同或类似的资源使用条件下。
统计回归的平均值(Statistical regression to the mean)
这是一个复杂的统计现象,可能发生在试验前后测量设计中。每当我们进行试验前测量时,因为某些在后测中不会出现的因素,有些人会在变量上得分较低或较高。那么当你采取后测方法时,那些人不会再得分那么低或者高。例如,假设我在本课中给了“研究方法”课多选题测验。你们中的一些人会做一些幸运的猜测,并给出你不知道答案的问题的正确答案,所以你的分数将被夸大(即蒙对答案了)。这样做的效果就是把课程的平均分数向上拖动。如果我稍后再给你们进行第二次相同的测试,那么第一次碰运气的人不太可能再做对。所以在后测中班级的平均值会更低(运气没有那么好,不可能每次都蒙对)。
许多因素可以产生这种回归假象。对于个人,可能只是觉得这一天很糟糕天,心情不好,没有集中注意力或者什么的,而且可能很难确定是什么导致了这个问题。当在一些准实验设计中根据前测的极端分数选择组时,统计回归极可能发生。回想一下,我们在前一课中讨论了这种方法(the regression-discontinuity or cutoff design)。这里的问题是,一些参与者只会在前测中得到极高的分数,这只是由于在后测中不会运行的因素(比如,运气)。当参与者被随机分配到组中时,回归不会是一个问题(提供随机化的工作),因为导致“误导性”极端分数的因素将随机分布在组中。
不幸的是,随机化并不总是奏效。我们曾进行过一项研究,评估松弛治疗对术前焦虑和麻醉困难的影响。将松弛治疗与在相似时间段中听短文(注意控制条件;稍后更多)和使用随机前测后测对照组设计的无治疗对照条件进行比较。当绘制时,放松和不治疗组状态焦虑的变化结果如下所示:
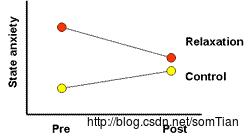
为清楚起见,我在这里省略了注意控制条件的结果。 他们一直在中间。 只要你看到这样的结果,就应该想起这些警告。 显然,尽管随机分配,这些群体在试验前的测试中焦虑并不相同。 因此治疗组的焦虑明显减少和对照组的增加可能归因于统计回归。 当我们把这项研究提交出版的时候,我们很快就指出了这一点。 幸运的是,我们还有其他数据来解释,并且这篇文章发表了。
与参与者选择相关的威胁 Threats relating to selection of participants
这些威胁涉及在多个小组研究中给参与者分配治疗条件时引入的偏差。
选择偏差 Selection bias
这种威胁涉及将参与者分配给群体时由差异选择产生的偏差。 如果一开始这些小组是不同的,那么在对其中一个小组实施治疗之后,无论治疗是否有效,他们很可能会有所不同。 例如,假设在我们放松术前焦虑研究中,我们将更多焦虑的参与者分配给控制条件,而不那么焦虑的参与者放松治疗条件,并使用静态组比较设计:
N——————X——————O1N——————X——————O2
我们可能会发现,放松组治疗后焦虑不如对照组。 显然,这可能是因为放松小组无论如何都不那么焦虑。 很显然,随机分配到组可以避免这个问题,因为这些组在预测试中是相等的。
威胁可以相互影响 Threats can interact
在多组研究中,选择偏差可能与我们已经遇到的以及未来的威胁相互影响。 例如,我们可以选择X为成熟。 在这里,如果存在差别选择,则因变量的变化可能是由于一些群组中的成熟变化而不影响其他群组。 例如,如果一个治疗组的成员比对照组年轻,那么治疗组的任何变化都可能是由于成熟,而不是治疗本身。 或者我们可以选择X为历史。 在这里,如果存在差别选择,则因变量的变化可能是由于在另一组中经历的历史事件而导致的。 如果一组在预测试中是极端的(相对于总体均值),那么我们也可以选择X回归,而其他组则不是。
选择X Selection X manipulation
选择X互动是相当不同的。在这种情况下,操纵的效果只适用于特定人群的抽样。因此这是对外部有用性的威胁。例如,大量的心理学研究已经使用本科生作为参与者,只是因为他们很容易掌握。然而,本科生与普通人群在很多方面有所不同。例如,人们希望他们比一般人更聪明,受教育程度更高。那么,我们可能会质疑,从本科生获得的结果是否适用于一般人群。
同样,在体育科学方面,大量的研究都使用竞技表现较低的体育表演者,因为很难有更多精英表演参与到我们的研究中来。假设我们发现当与较低水平的表演者进行测试时,一些干预“有效”。我们无法知道,除非我们继续用这种人群进行测试,否则同样的干预措施是否会对精英运动员有效。更进一步。如果我们继续在英超球员上测试干预措施,那么我们怎么知道同样的干预措施对顶级短跑运动员来说同样适用呢?无论内部有效性如何强大,没有设计可以回答这个问题。实际上,这是一个我们必须始终牢记的的普遍的外部效度问题。从逻辑上讲,我们不能将内部有效研究的结果推广到与用于测试干预的人群不同的人群( Logically, we cannot generalise the results of an internally valid study to populations other than the one used to test an intervention)。但是,我们通常没有资源对每一个可能的人口采取干预措施。在结束的时候,我们必须对我们的发现在多大程度上能够推广到不同的人群进行一般化的判断。这就成了一个有效性的问题:从不同的人群中获得同样的结果是否合理?
采样结果能够视为普遍结果,在样本人群上的研究结果能否视为普遍结果。现在人们说大数据可以不用采样了,我们可以获取全部的信息,但是你确定你获取的是大数据?你的大数据是全部信息吗?
测试和操纵相关的威胁 Threats relating to testing and manipulations
这些威胁与测试参与者的行为有关,而且与那些预期行为不同的操纵的潜在影响。
测试 Testing
测试效果与在前测对于后测成绩的影响有关。后测分数可能受到前测行为的影响,即在记忆、熟悉测试设置等方面获得的练习的影响。 例如,提高智商分数的最好方法就是进行智商测试! 通常情况下,从第一次IQ测试到第二次测试,分数提高了大约3-5分。 当然,这并不意味着进行智商测试会提高你的智力!
单组前测后测设计显然会面临这种威胁。 随着时间的推移,任何明显的变化可能只是由于采取了预先测试的行为,而不是由于任何干预。 那么随机前测 - 后测对照组设计怎么样?
希望现在你已经得到了技能! 如果参与者被随机分配到组中,那么测试效果将在所有组中均等地表现出来。 因此,我们可以确定操纵对实验组的影响,超过了测试本身的影响。
测试的反应性影响 Reactive effects of testing
前测可以以更微妙的方式改变人们面对后测反应的方式。例如,假设我们让一些年轻运动员完成关于体育运动中毒品的态度问卷。填写问卷的行为可能会让他们离开,对体育药物的思考比以前更加深入。然后,如果您在以后再次提交同样的调查问卷,他们可能会以不同的方式回答预先测试的问题,而不考虑旨在改变态度的任何干预措施的效果。这也被称为预测试敏感性:预测试使参与者对干预敏感,以便他们以不同于没有参与预测的应答的方式做出反应。测试的反应效果实际上是预测试和干预之间的相互作用。这是对外部效度的威胁,因为如果根据我们的研究,我们认定我们的干预是有效的,那么当我们外出并在现实生活中应用干预时,我们通常不会预先测试个人。你能想到一个可以避免这个问题的设计吗?
随机后测只控制组设计控制测试效果和测试的反应效果,因为没有预测试!因此,它可以比随机前测后测控制组设计(因为没有预测试致敏的可能性)提供显着的优势,当然,随机化将在预测试中的组视为等同的。
所罗门四组设计:
R——————O1——————X——————O2R——————O3————————————O4R————————————X——————O5R——————————————————O6
也控制了测试的反应性效应,而且由于有一些小组既可以进行前期测试,也可以进行后期测试,因此可以确定干预前后干预期间是否有任何变化,没有干预(即由于时间的推移)。正如前面所讨论的,这是随机的只有后测试的对照组设计不可能的,因为用这种设计,我们不能说出对照组在没有干预的情况下随时间变化了多少,因为没有预先测试。*
但是,正如前一课所述,所罗门设计的实施费用昂贵且耗时。
反应性安排 Reactive arrangements
反应性安排不应与测试的反应性影响相混淆。这些是与参与者对研究背景的反应有关的更普遍的一类威胁。本质上,问题归结为:研究环境不是自然的情况,所以我们可能期望研究的参与者表现不自然。换句话说,研究设置可能会影响到参与者做出和现实生活
以上是关于科学研究设计六:有效性威胁的主要内容,如果未能解决你的问题,请参考以下文章