Java正则之Unicode属性匹配的那些事
Posted 于大圣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java正则之Unicode属性匹配的那些事相关的知识,希望对你有一定的参考价值。
前言:最近项目中客户要求只保留文本中的字母部分,比如将处理文本 [ 文本你 好 呀, PL-g;'.*o,o 121“‘2ds -> 你好呀PLgoods ]。使用如下Java代码可以达成目的,但是对于\\\\PL+这种非常规的正则表达式比较陌生,那么如果延伸下需求,比如要去除文本中的数字符号、货币符号、标点符号以及控制字符等可能就无能为力,始终停留在知其然而不知其所以然的状态。本人通过查阅资料结合个人理解整理成本篇博客,目标是记录下这种正则的本质,提供一种新的方式或手段来达成文本处理目的;
public static void main(String[] args) throws IOException
String contents = "你 好 呀, PL-g;'.*o,o 121“‘2ds";
contents = contents.replaceAll("\\\\PL+","");
System.out.println(contents);
1.1 unicode字符常识
首先明确一点计算机中显示的任何一个能正常显示的符号都算作一个unicode字符,unicode字符涵盖了各语言区域下出现的字母、数字、标点、空格换行、货币符号等;日常我们提及到unicode字符,更多地关注unicode字符编码(code point),其实与正则相关的还有另外三个属性:分别为Unicode Property、Unicode Block、Unicode Script。我们可以通过以下图片加强下认知,可以发现unicode字符的这三个属性分别从三个不同的角度来描述unicode字符

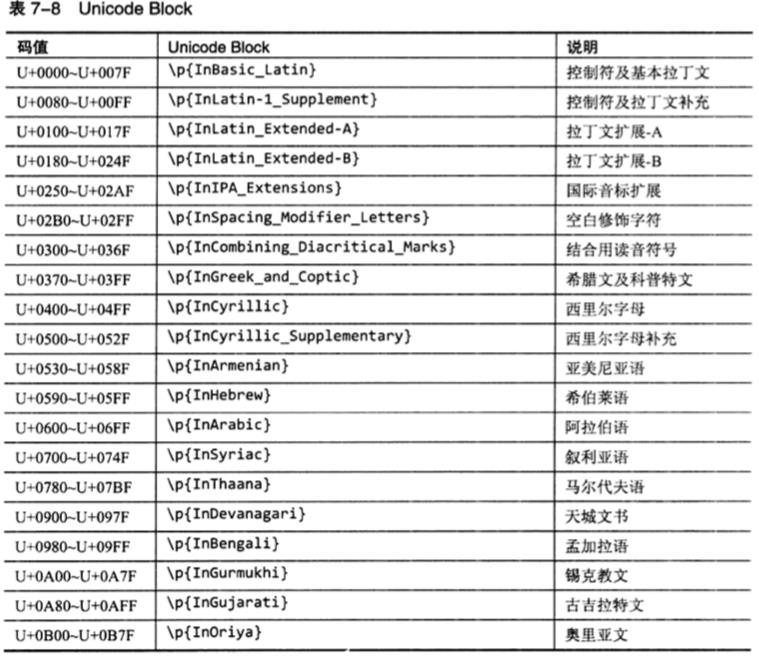
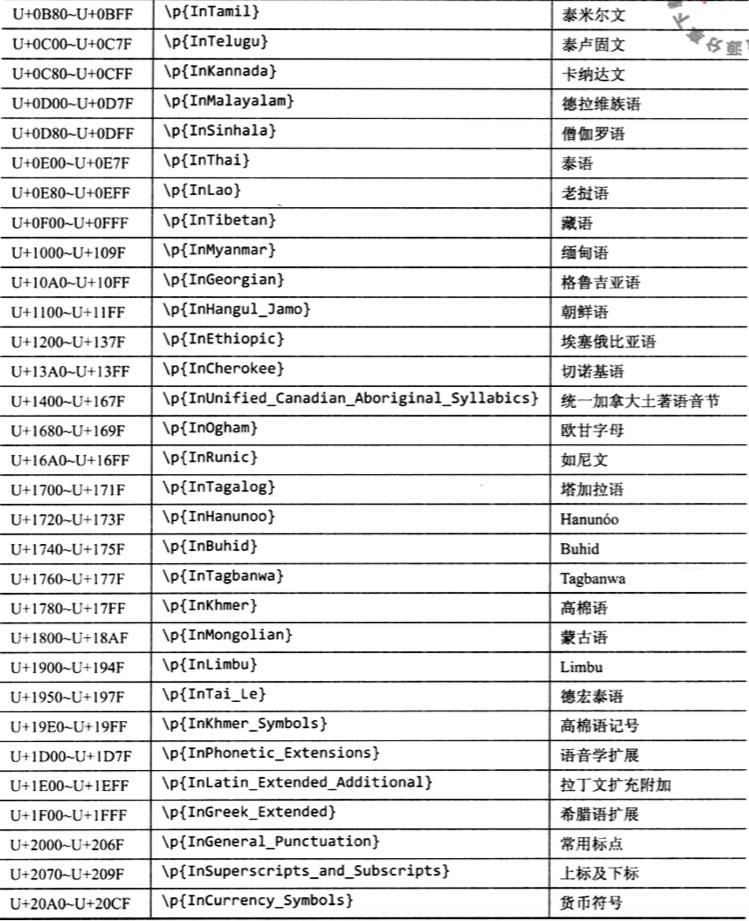
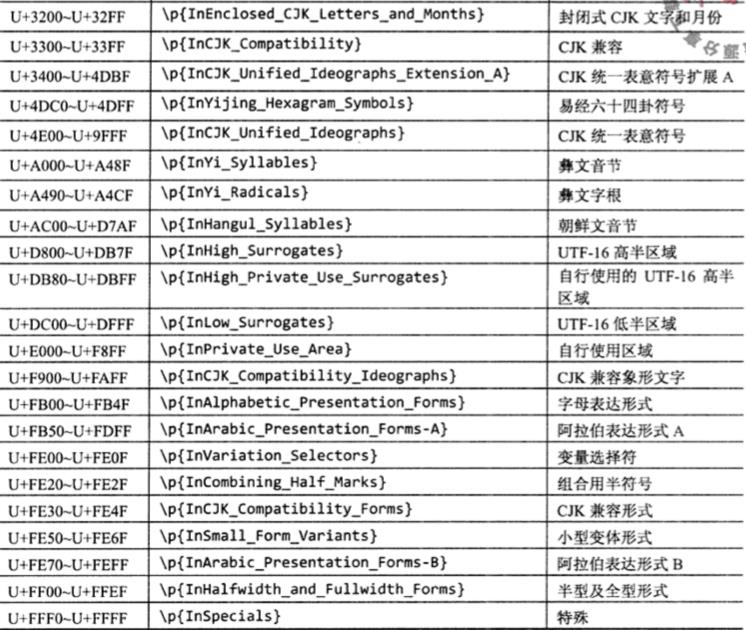
1.2 Unicode Block
按照编码去接划分Unicode字符,每个Unicode字符都有唯一归属的Unicode Block,各个区间彼此联系但互不相交;一般情况下同一种语言的字符通常落在同一区间内,所以Unicode Block可以粗略地表示某类语言的字符,可以通过Unicode块来查看详细的Block划分,简单Java示例如下。另外这个区间划分不太靠谱,比如涉及到全半角和不同语言区域下的标点时就需要具体确认到底在哪个区间下才可以使用,不要通过字面意思来断定,切记!
每个 Unicode Block 都对应一个连续的 Unicode 码值区间,U+0000 到U+FFFF 之间的字符一共划分为 105 个 Block,点此查看每个Block所包含的所有Unicode字符。使用时应该注意,Java 使用的 Unicode Block 是\\pIn...形式的,比如InCJK_Unified_Ideographs;而 .NET 使用的 Unicode Block 是\\pIs...形式的,同时不包含下划线,比如IsCJKUnifiedIdeographs。

Java代码示例:
// CJK -> China Japanese Korea 兼容 CJK(中文、日文、韩文)统一表意字符
System.out.println("我".matches("\\\\pInCJK_Unified_Ideographs"));1.3 Unicode Script
按照字符所属的书写系统来划分 Unicode 字符,比如\\pGreek表示希腊语字符,\\pHan表示汉语(中文字符)。它的写法类似 Unicode Block,只是名字的开头没有 Is 或者 In。由于Java目前不支持,所以就不演示了;

1.4 Unicode Property
按照字符的功能对Unicode进行分类,每个Unicode字符只能属于一个Unicode Property。语法类型/p大类[小类],小类可忽略。诸如:/pL、/pSc、/pPc等。从功能角度描述字符;比如有些字符是语言字母,有些用作标点符号,有些又来处理空格字符;需要注意的是它并不关心字符所属的语言,不在乎全角半角,不介意是中文还是英文,只关注这个字符的功能本身,即在不同语言区域下的功能是一致的;目前Java是支持Unicode Property的,前言部分谈及的需求就是利用了Java支持Unicode Property这个特性实现的,其它语言是否支持请自行查阅确认;
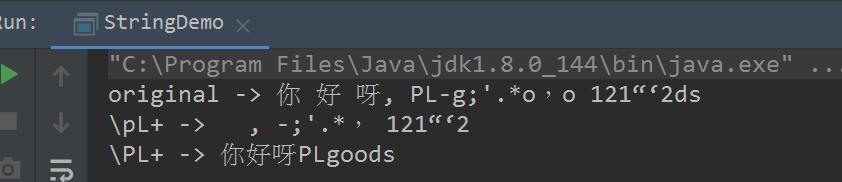
另外可以将/p -> /P,含义相反;比如/pL表示匹配各种语言区域下的字母,那么/PL表示匹配各种语言区域下的非字母内容,简单理解为/pL和/PL匹配内容截然相反,逻辑非的关系,如下一个简单DEMO体会下区别:
public static void main(String[] args) throws IOException
String contents = "你 好 呀, PL-g;'.*o,o 121“‘2ds";
System.out.println("original -> " + contents);
System.out.println("\\\\pL+ -> " + contents.replaceAll("\\\\pL+",""));
System.out.println("\\\\PL+ -> " + contents.replaceAll("\\\\PL+",""));
每个 Unicode 字符都只能属于一个 Unicode Property。所有的Unicode Property 共分为7大类,30小类。大类的名字只有1个字母,小类的名字则不知1个字母,开头字母与所在大类的名字相同,小类包含的字符都属于它所在的大类。
| Unicode Property | 说明 | |
|---|---|---|
| \\pC | 不可见的控制字符和未使用的码值 | |
| \\pCc | ASCII 编码中 0x00 到 0x1F 或 Latin-1 编码中 0x80 到 0x9F 的控制字符 | |
| \\pCf | 不可见的格式字符 | |
| \\pCo | 留作私用的码值 | |
| \\pCs | UTF-16 编码中 surrogate pair 的一半 | |
| \\pCn | 未指定的码值 | |
| \\pL | 各种语言中的字母 | |
| \\pLl | 具有大写形式的字母的小写形式 | |
| \\pLt | 只有在单词首位才大写的字符 | |
| \\pL& | 等于Ll、Lu、Lt的组合 | |
| \\pLo | 没有大小写形态的字母 | |
| \\pLu | 具有小写字母的字母的大写形式 | |
| \\pM | 用来与其他字符结合的字符(声调、元音变化音等) | |
| ">\\pMc | 与其他字符组合,并且会占用空间的字符(常见于东亚语言) | |
| \\pMe | 需要成对出现的字符,比如圆括号、方括号 | |
| \\pMn | 用来与其他字符结合,但并不占用额外空间的字符 | |
| \\pN | 各种书写系统中的数字字符 | |
| \\pNd | 各种书写系统中的 0~9 的字符 | |
| \\pNl | 形如字符的数字,比如罗马数字 | |
| \\pNo | 上标或者下标数字,或者是0~9之外的数字(不包括表一书写系统中的数字) | |
| \\pP | 各种标点符号 | |
| \\pPd | 各种连字符号 | |
| \\pPs | 成对但不同的符号的前半部分(包括英文括号、中文括号、书名号) | |
| \\pPe | 成对但不同的符号的后半部分(包括英文括号、中文括号、书名号) | |
| \\pPi | 成对但不同的符号的前半部分(比如单引号、双引号) | |
| \\pPf | 成对但不同的符号的后半部分(比如单引号、双引号) | |
| \\pPc | 类似下划线之类的标点字符 | |
| \\pPo | 除横线、括号、引号和连接符之外的任何标点符号 | |
| \\pS | 数字符号、货币符号 | |
| \\pSm | 数字符号 | |
| \\pSc | 货币符号 | |
| \\pSk | 由多个字符构成的组合字符 | |
| \\pSo | 数字符号、货币符号和组合字符之外的符号字符 | |
| \\pZ | 空白字符,或者不可见的字符 | |
| \\pZs | 不可见但占用空间的空白字符 | |
| \\pZl | 分行符 U+2028 | |
| \\pZp | 分段符 U+2029 | |
至此,相信大家应该对Java中采用支持Unicode Property的正则表达式有了一定的了解,回头再看如下代码时是不是就会觉得很简单了呢!
以上,完了,以便自己与后来者!
以上是关于Java正则之Unicode属性匹配的那些事的主要内容,如果未能解决你的问题,请参考以下文章