Apache Kafka 核心组件和流程-日志管理器-设计-原理(入门教程轻松学)
Posted 程序员小熊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Kafka 核心组件和流程-日志管理器-设计-原理(入门教程轻松学)相关的知识,希望对你有一定的参考价值。
作者:稀有气体
来源:CSDN
原文:https://blog.csdn.net/liyiming2017/article/details/82805479
版权声明:本文为博主原创文章,转载请附上博文链接!
本入门教程,涵盖Kafka核心内容,通过实例和大量图表,帮助学习者理解,任何问题欢迎留言。
目录:
- kafka简介
- kafka安装和使用
- kafka核心概念
- kafka核心组件和流程--控制器
- kafka核心组件和流程--协调器
- kafka核心组件和流程--日志管理器
- kafka核心组件和流程--副本管理器
- kafka编程实战
上一节介绍了协调器。协调器主要负责消费者和kafka集群间的协调。那么消费者消费时,如何定位消息呢?消息是如何存储呢?本节将为你揭开答案。
3 日志管理器
3.1 日志的存储
Kafka的消息以日志文件的形式进行存储。不同主题下不同分区的消息是分开存储的。同一个分区的不同副本也是以日志的形式,分布在不同的broker上存储。
这样看起来,日志的存储是以副本为单位的。在程序逻辑上,日志确实是以副本为单位的,每个副本对应一个log对象。但实际在物理上,一个log又划分为多个logSegment进行存储。
举个例子,创建一个topic名为test,拥有3个分区。为了简化例子,我们设定只有1个broker,1个副本。那么所有的分区副本都存储在同一个broker上。

第二章中,我们在kafka的配置文件中配置了log.dirs=/tmp/kafka-logs。此时在/tmp/kafka-logs下面会创建test-0,test-1,test-2三个文件夹,代表三个分区。命名规则为“topic名称-分区编号”
我们看test-0这个文件夹,注意里面的logSegment并不代表这个文件夹,logSegment代表逻辑上的一组文件,这组文件就是.log、.index、.timeindex这三个不同文件扩展名,但是同文件名的文件。
- .log存储消息
- .index存储消息的索引
- .timeIndex,时间索引文件,通过时间戳做索引。
这三个文件配合使用,用来保存和消费时快速查找消息。
刚才说到同一个logSegment的三个文件,文件名是一样的。命名规则为.log文件中第一条消息的前一条消息偏移量,也称为基础偏移量,左边补0,补齐20位。比如说第一个LogSegement的日志文件名为00000000000000000000.log,假如存储了200条消息后,达到了log.segment.bytes配置的阈值(默认1个G),那么将会创建新的logSegment,文件名为00000000000000000200.log。以此类推。另外即使没有达到log.segment.bytes的阈值,而是达到了log.roll.ms或者log.roll.hours设置的时间触发阈值,同样会触发产生新的logSegment。
3.2 日志定位
日志定位也就是消息定位,输入一个消息的offset,kafka如何定位到这条消息呢?
日志定位的过程如下:
1、根据offset定位logSegment。(kafka将基础偏移量也就是logsegment的名称作为key存在concurrentSkipListMap中)
2、根据logSegment的index文件查找到距离目标offset最近的被索引的offset的position x。
3、找到logSegment的.log文件中的x位置,向下逐条查找,找到目标offset的消息。
结合下图中例子,我再做详细的讲解:
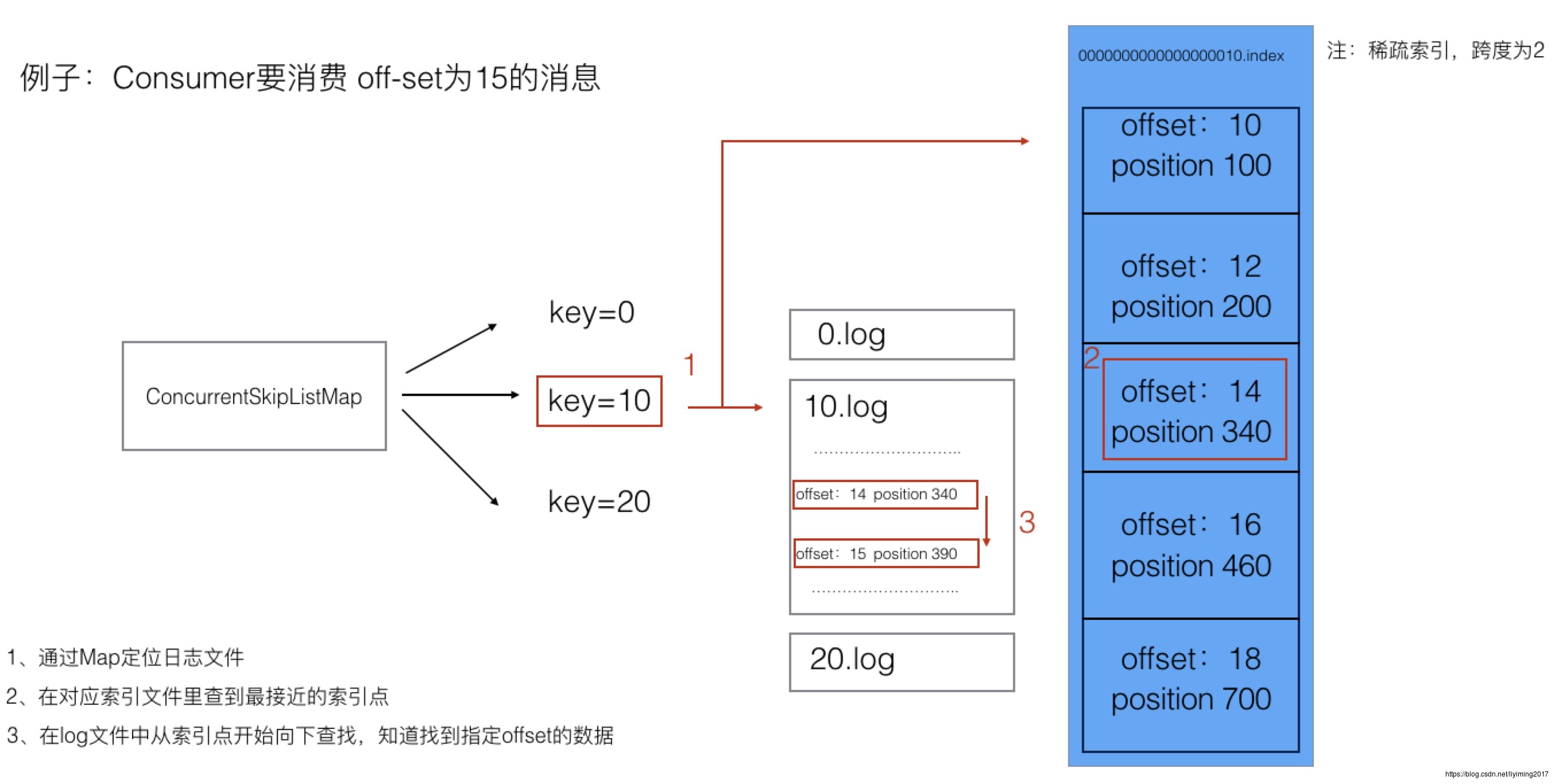
这里先说明一下.index文件的存储方式。.index文件中存储了消息的索引,存储内容是消息的offset及物理位置position。并不是每条消息都有自己的索引,kafka采用的是稀疏索引,说白了就是隔n条消息存一条索引数据。这样做比每一条消息都建索引,查找起来会慢,但是也极大的节省了存储空间。此例中我们假设跨度为2,实际kafka中跨度并不是固定条数,而是取决于消息累积字节数大小。
例子中consumer要消费offset=15的消息。我们假设目前可供消费的消息已经存储了三个logsegment,分别是00000000000000000,0000000000000000010,0000000000000000020。为了讲解方便,下面提到名称时,会把前面零去掉。
下面我们详细讲一下查找过程。
- kafka收到查询offset=15的消息请求后,通过二分查找,从concurrentSkipListMap中找到对应的logsegment名称,也就是10。
- 从10.index中找到offset小于等于15的最大值,offset=14,它对应的position=340
- 从10.log文件中物理位置340,顺序往下扫描文件,找到offset=15的消息内容。
可以看到通过稀疏索引,kafka既加快了消息查找的速度,也顾及了存储的开销。
以上是关于Apache Kafka 核心组件和流程-日志管理器-设计-原理(入门教程轻松学)的主要内容,如果未能解决你的问题,请参考以下文章