java:jvm:JVM堆区新生代为什么有两个Survivor
Posted 花和尚也有春天
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java:jvm:JVM堆区新生代为什么有两个Survivor相关的知识,希望对你有一定的参考价值。
JVM内存模型中, Heap区被分为新生代和老年代两个区域, 新生代又分为Eden+Survivor1+Survivor2. 新生代收集算法主要使用复制算法, 老年代收集算法主要使用标记-清理或标记-整理算法。

堆内存划分
新生代在发生首次YGC的时候, Eden内存活的对象会被复制到S1。

再发生YGC的时候, Eden内存活的对象和S1内存活的对象会被复制到S2, 同时清除Eden内的对象和S1内的对象.
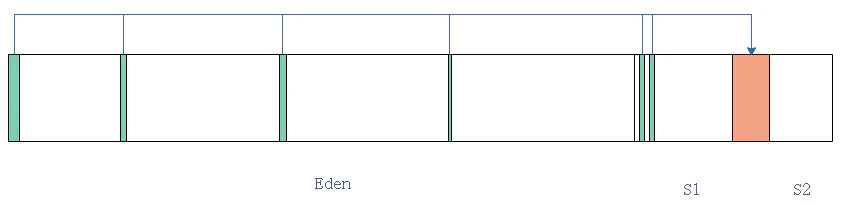
再发生YGC的时候, Eden内存活的对象和S2内存活的对象会被复制到S1, 同时清除Eden内的对象和S2内的对象.
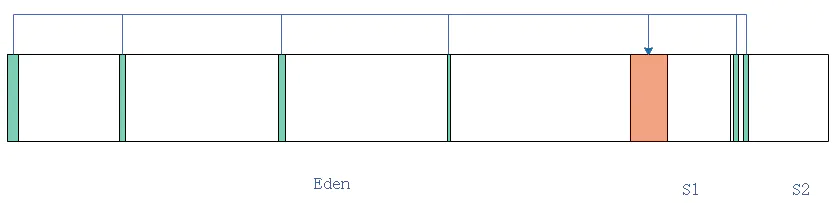
以此往复循环. 生存次数超过阈值的对象进入老年代. 可以总结得出: 每次YGC发生之后, S1和S2总会有一个是空的, 这样子的目的是避免内存碎片化带来的空间与性能损失. 请注意笔者画图的时候故意画出间隔很大的不同内存区域, 实际情况中这就是存活对象的内存分布.
现在想象一下如果只有一个Survivor区, 那么每次YGC的时候, Eden区和S区都会有内存碎片, 这是无疑的一点, 此时如果将Eden区内存活的对象直接复制到S区, 那么内存情况将会是如下:
(惨不忍睹...)

随着一次次的YGC, S区内的内存碎片无疑会变得越来越多.内存浪费非常严重. 这里有人可能会想: 我们好像也可以在每次YGC的时候, 对S区内的对象进行重排列, 使得S区内的对象一个个紧挨着彼此, 避免内存碎片化. 这个想法是可以的, 但是要考虑到YGC是JVM垃圾收集中最最最频繁的活动. 如果每次YGC时都要花费这么多时间去重排列对象, 对象重排列相比直接复制, 是很耗时的计算. 因此划分出两个Survivor区域, 以空间为代价(每次都有一个S区为空)换取GC时间, 是很值得的事情. 提升了服务器响应性。
以上是关于java:jvm:JVM堆区新生代为什么有两个Survivor的主要内容,如果未能解决你的问题,请参考以下文章