Deformable ConvNets v2: More Deformable, Better Results
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deformable ConvNets v2: More Deformable, Better Results相关的知识,希望对你有一定的参考价值。
之前介绍过dai老师的DCN v1Deformable Convolutional Networks解读,现在出了V2效果更赞,实验分析也很充分。
分析DCN
Spatial Support Visualization
- Effective receptive fields
理论上现在很多深层网络最后feature上每个位置的视野域都是铺满全图的,但是实际视野域中每个点对响应的不同,有效视野域即为输入扰动后实际能对输出产生影响的区域。比如求conv2上某一位置的有效视野域,那就依次扰动图像观察该位置处的输出变化,看看哪些像素点能对输出产生影响。一般来说输出点对应回去的中心点对输出影响最大。 - Effective sampling/bin locations
DCNv1中只对采样位置进行了可视化,但是每个采样位置的权重也是不一样的,现在对采样点或者采样的bin的位置和权重都进行了可视化 - Error-bounded saliency regions
已经有一些工作做mask掉图片一些区域使最后输出没有变化,在这个基础上我们可以可视化出最小的能给出和原始一样的输出,也即是最小的最有效识别部分
spatial support of nodes in the last layer of the conv5 stage
图中第一行是Effective sampling/bin locations,第二行是Effective receptive fields,第三行是Error-bounded saliency regions,注意这里第一行和第二行与上面的介绍顺序不是一致的。c中第一行Effective sampling/bin locations和b类似就省略了(有点疑问,v2不是加了权重项嘛,怎么会和v1类似呢奇怪),每个子图的三列分别代表中小物体,大物体和背景。

分析以上可视化结果
- 传统的Conv还是能一定程度上建模几何变换的
- 加入DCN后对几何变换的建模能力得到了提升加入DCN后对几何变换的建模能力得到了提升,前景对应的feature点能更多的覆盖整个物体,背景对应的feature点能更多的包含context,确保没有物体漏下,但是spatial support是不精确的,前景的effective receptive field和error-bounded saliency region还是会有一些无关的背景混入。
- 以上3种spatial support的可视化比DCN V1中用的采样位置可视化包含更多的信息。比如传统的卷积采样位置是固定的,但是通过网络权重的变化可以改变它effective spatial support,dcn v1也类似可以通过offset和权重改变effective spatial support
spatial support of the 2fc node in the per-RoI detection head

- Aligned RoIpooling就是采样7*7的bin,而Deformable RoIpooling的bin加了offset。可以看到Deformable RoIpooling的采样的bin更好的覆盖在物体前景上
- 但是也可以看到Aligned RoIpooling和Deformable RoIpooling的error-bounded saliency regions都没有很精准地focus在物体前景上,这在Revisiting RCNN: On Awakening the Classification Power of Faster RCNN提到这样的特征可能会干扰识别的。
- v2(Modulated Deformable RoIpooling)error-bounded saliency regions更集中地focus在物体前景上,加了R-CNN Feature Mimicking后更集中。
DCN V2
dcn v2在v1的基础上不仅有每个采样位置的偏移 Δ p k \\Delta p_k Δpk给每个采样位置还计入了不同的权重 Δ m k \\Delta m_k Δmk,这里肯定会有一个疑问就是这里采样位置的权重和卷积本来的权重不是重复的嘛?这里又提到了之前说过的数据驱动的问题,卷积的权重的是固定的,而 Δ m k \\Delta m_k Δmk是跟数据相关的,不同的输入过来产生的权重是不同的。
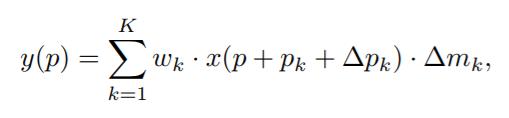
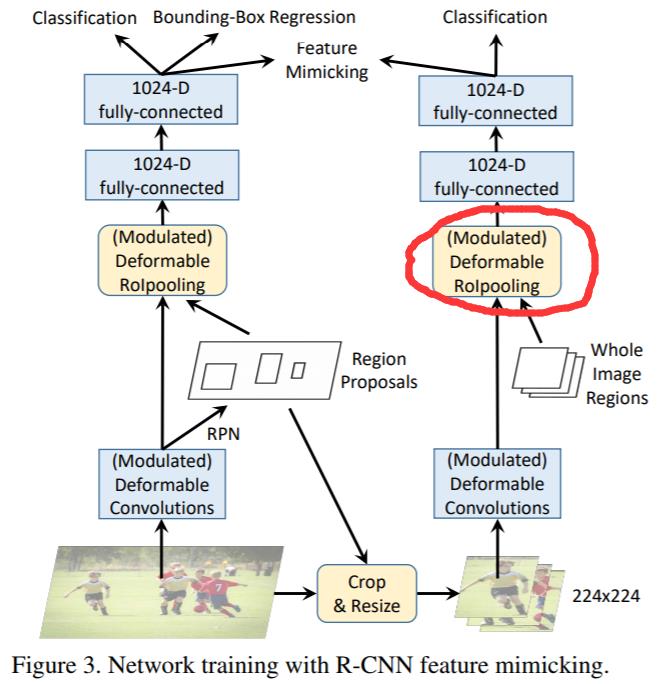
R-CNN Feature Mimicking
在Revisiting RCNN: On Awakening the Classification Power of Faster RCNN中讲过,它是加了一个RCNN的分支去改善检测,训练和测试都需要这个分支,速度受到影响,而DCN v2是采用知识蒸馏的方法,RCNN在训练时当老师,测试时不再需要了。
注意一个细节就是RCNN分支也加了一个Modulated Deformable RoIpooing,和student分支一致
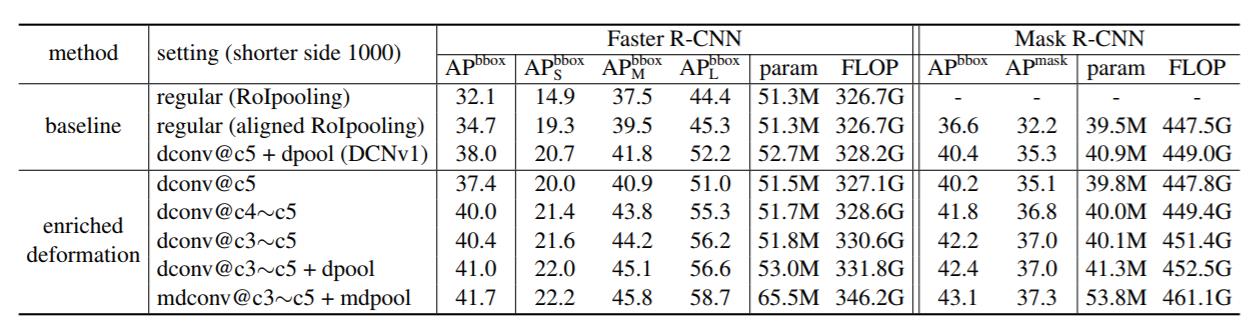
experiment
- 更多的conv换成deformable conv后效果提升
- dcn v1换成dcn v2(dconv-> mdconv, dpool->mdpool)效果提升
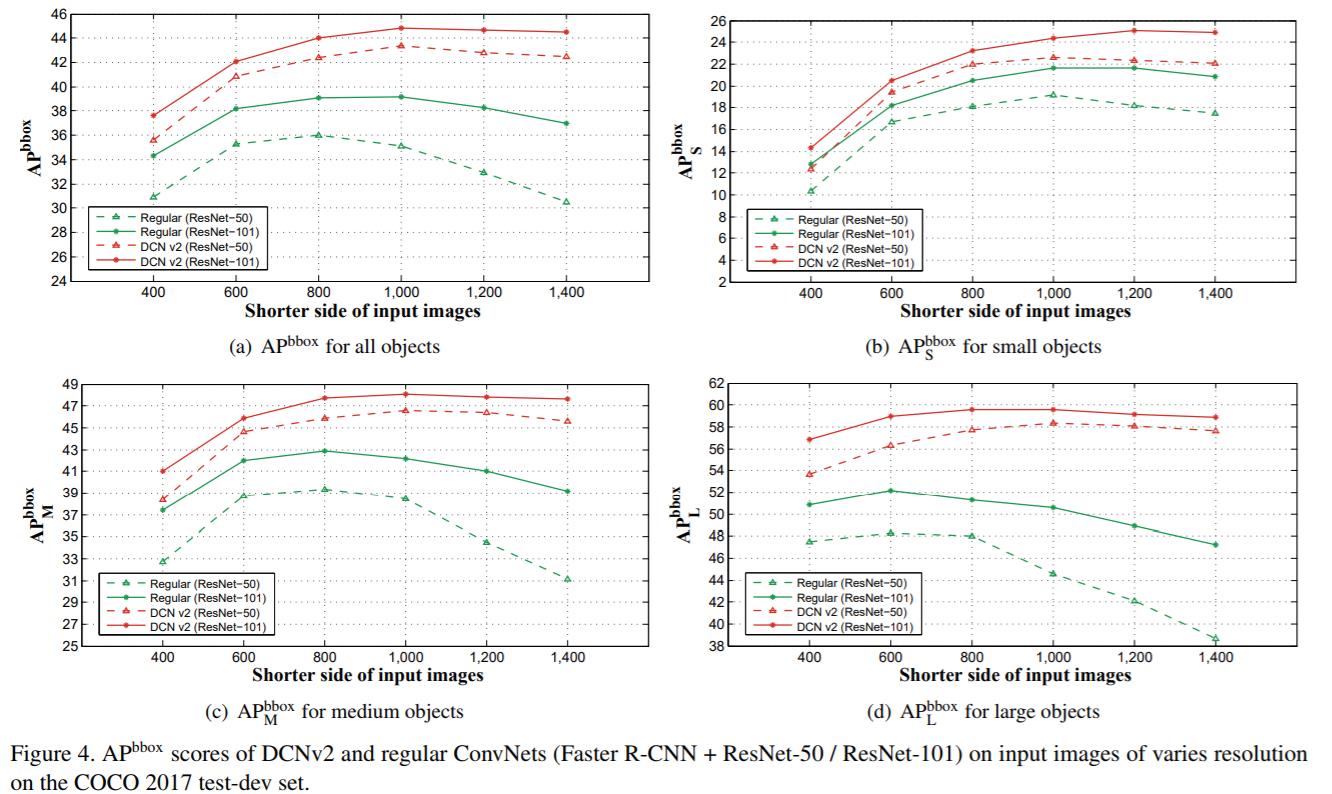
还有一个重要的实验,就是dcn v2随着测试时输入图片的增大,精度并没有像Mask RCNN那样降低,而是稳步增长到一定程度,这也进一步说明了dcn v2对几何变换的建模能力。
- Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
- 谈知识蒸馏(Knowledge Distillation)
以上是关于Deformable ConvNets v2: More Deformable, Better Results的主要内容,如果未能解决你的问题,请参考以下文章