BERT模型解析
Posted zhiyong_will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BERT模型解析相关的知识,希望对你有一定的参考价值。
1. 概述
Bidirectional Encoder Representation from Transformers(BERT)[1],即双向Transformer的Encoder表示,是2018年提出的一种基于上下文的预训练模型,通过大量语料学习到每个词的一般性embedding形式,学习到与上下文无关的语义向量表示,以此实现对多义词的建模。与预训练语言模型ELMo[2]以及GPT[3]的关系如下图所示:
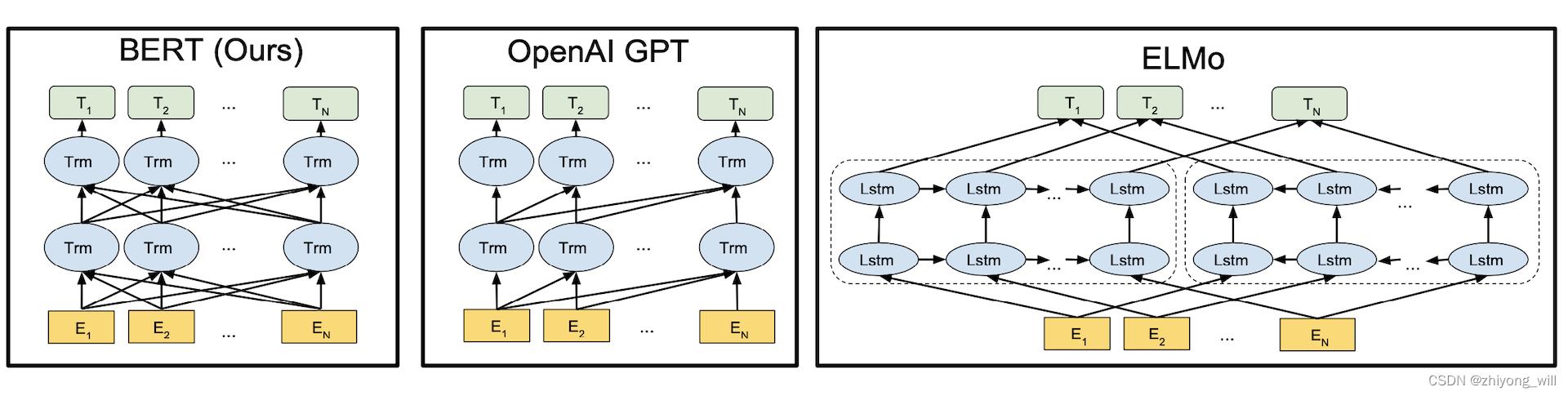
Embeddings from Language Models(ELMo)[2],Generative Pre-Training(GPT)[3]以及Bidirectional Encoder Representation from Transformers(BERT)[1]三者都是基于上下文的预训练模型,也都是采用两阶段的过程,第一阶段是利用无监督的方式对语言模型进行预训练,第二阶段通过监督的方式在具体语言任务上进行Fine-tuning。不同的是在ELMo中采用的双向的LSTM算法;在GPT中采用的特征提取算法是Transformer[4],且是单向的Transformer语言模型,相比较于ELMo中的LSTM模型,基于Transformer的模型具有更好的特征提取能力;在BERT中同样采用了基于Transformer的特征提取算法,与GPT中不同的是:
- 第一,在BERT中的Transformer是一个双向的Transformer模型,更进一步提升了特征的提取能力
- 第二,GPT中采用的是Transformer中的Decoder模型,BERT中采用的是Transformer中的Encoder模型。
2. 算法原理
2.1. Transformer结构
Transformer的网络结构如下图所示:
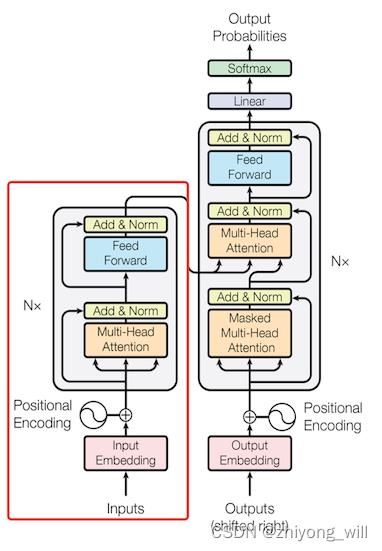
在Transformer中,包含了Encoder和Decoder两个部分,在对语言模型的训练中,摒弃了基于RNN和CNN的传统做法,采用了基于Attention的模型,能够提升特征的抽取能力,同时更利于并行的学习。BERT采用了Transformer的Encoder部分,如上图中的红色框内的部分。
2.2. BERT的基本原理
BERT是基于上下文的预训练模型,BERT模型的训练分为两步:第一,pre-training;第二,fine-tuning。
在pre-training阶段,首先会通过大量的文本对BERT模型进行预训练,然而,标注样本是非常珍贵的,在BERT中则是选用大量的未标注样本来预训练BERT模型。在fine-tuning阶段,会针对不同的下游任务适当改造模型结构,同时,通过具体任务的样本,重新调整模型中的参数。
为了使得BERT能够适配更多的应用,模型在pre-training阶段,使用了Masked Language Model(MLM)和Next Sentence Prediction(NSP)两种任务作为模型预训练的任务,其中MLM可以学习到词的Embedding,NSP可以学习到句子的Embedding。在Transformer中,输入中会将词向量与位置向量相加,而在BERT中,为了能适配上述的两个任务,即MLM和NSP,这里的Embedding包含了三种Embedding的和,如下图所示:
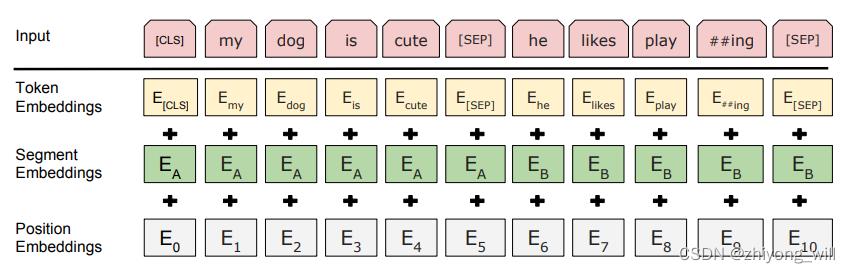
其中,Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任,Segment Embeddings用来区别两种句子,这是在预训练阶段,针对NSP任务的输入,Position Embeddings是位置向量,但是和Transformer中不一样,与词向量一样,是通过学习出来的。此处包含了两种标记,一个是[CLS],可以理解为整个输入特征的向量表示;另一个是[SEP],用于区分不同的句子。
2.2.1. 预训练之MLM
Masked Language Model的原理是随机将一些词替换成[MASK],在训练的过程中,通过上下文信息来预测被mask的词。文献[1]中给出了如下的例子:“my dog is hairy”,此时被随机选中的词是“hairy”,则样本被替换成“my dog is [MASK]”,训练的目的是要使得BERT模型能够预测出此处的“[MASK]”即为“hairy”。同时,随机替换的概率为
15
%
15\\%
15%。同时,对于这
15
%
15\\%
15%的随机选择,分为以下的三种情况:
- 选中词的 80 % 80\\% 80%替换成[MASK],如:“my dog is [MASK]”
- 选中词的 10 % 10\\% 10%随机替换,如替换成apple,即:“my dog is apple”
- 选中词的 10 % 10\\% 10%保持不变,即:“my dog is hairy”
这样做的目的是让模型知道该位置对应的token可以是任何的词,这样就强迫模型去学习更多的上下文信息,不会过多的关注于当前的token。
2.2.2. 预训练之NSP
Next Sentence Prediction的目的是让模型理解两个橘子之间的关系,训练的输入是两个句子,BERT模型需要判断后一个句子是不是前一个句子的下一句。在Input中,有Segment Embeddings,就是标记的不同的句子。在选择训练数据时,输入句子A和B,B有50%的概率是A的下一句,具体的例子如:

2.3. BERT的网络结构
根据Transformer的Encoder结构,对于单个的Attention过程,有如下的BERT结构:
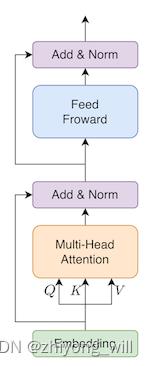
具体的Attention的计算逻辑可以参见参考文献[5],文献[5]对于Transformer的基本原理有详细的介绍。参考文献[6]给出了BERT的代码实现,其中transformer部分的代码如下所示:
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads) # self-attention的头
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0] # batch的大小
seq_length = input_shape[1] # 句子长度
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"): # attention的计算
attention_heads = []
with tf.variable_scope("self"):
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head) # 多头注意力
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1) # concat多头的输出
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob) # dropout
attention_output = layer_norm(attention_output + layer_input) # layer norm
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
2.3.1. BERT是双向Transformer
GPT模型中使用的是Transformer的Decoder部分(对原始的Decoder部分做了些许改动),而BERT则是采用了Transformer的Encoder部分,下图给出了两者在一个Transformer模块上的对比:
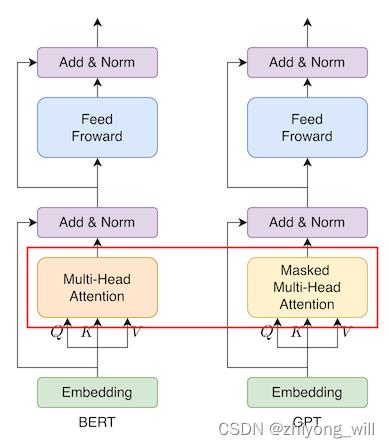
从上图中可以看出,唯一的不同是在Multi-Head Attention部分,如图中的红色框,在BERT中使用的是Multi-Head Attention,而GPT中使用的是Masked Multi-Head Attention。在Masked Multi-Head Attention是应用在Decoder阶段的生成模型,即在 t t t时刻,根据 t − 1 t-1 t−1时刻及之前的词预测 t t t时刻的词,对于 t t t时刻以及 t t t时刻之后的词是不可见的,因此Masked Multi-Head Attention是一个单向的模型,同时不便于并行。
对于Multi-Head Attention,其计算方法如下图所示:

在计算Attention的过程中,会同时利用上文和下文的信息,只是对于上图中的“it_”会以一定的概率被[MASK]标记替换。因此,BERT模型是一个双向的语言模型,同时,BERT中的Attention计算利于并行计算。
2.3.2. Fine Tune
对于NLP的任务,主要分为四大类:
- 序列标注,如中文分词,词性标注,命名实体识别(特点:句子中每个单词要求模型根据上下文都要给出一个分类类别)
- 分类任务,如文本分类,情感计算(特点:总体给出一个分类类别)
- 句子关系判断,如QA,语意改写(特点:给定两个句子,模型判断出两个句子是否具备某种语义关系)
- 生成式任务,如机器翻译,文本摘要,写诗造句,看图说话(特点:输入文本内容后,需要自主生成另外一段文字)
而生成式任务在Transformer中有了详细的介绍。对于其他的三类任务,典型的场景如下图所示:
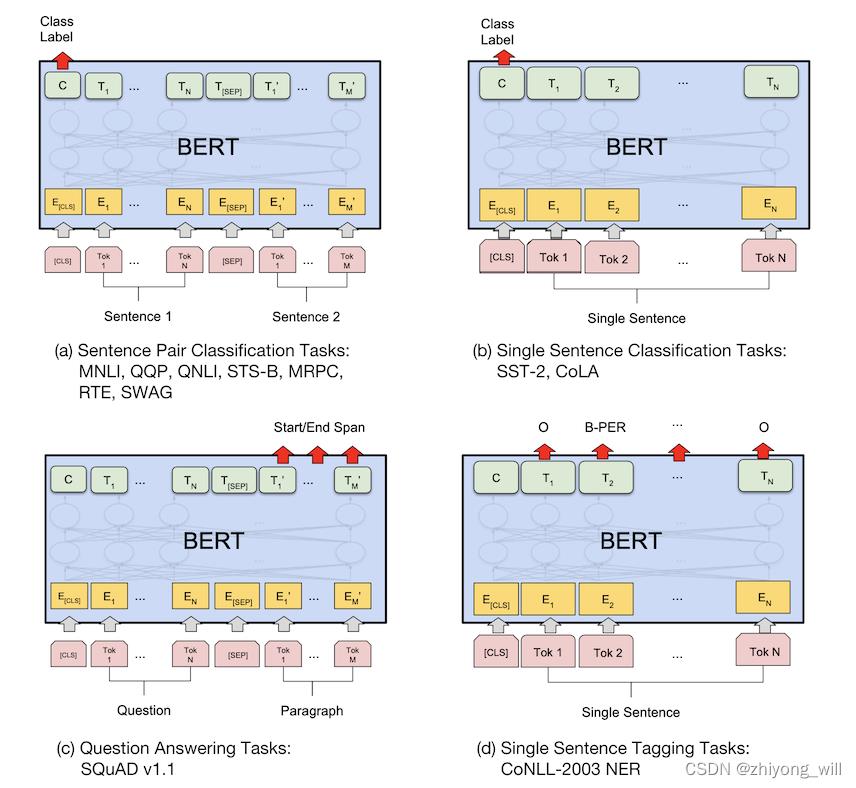
第一,句子对的分类任务,即输入是两个句子,输入如下图所示:
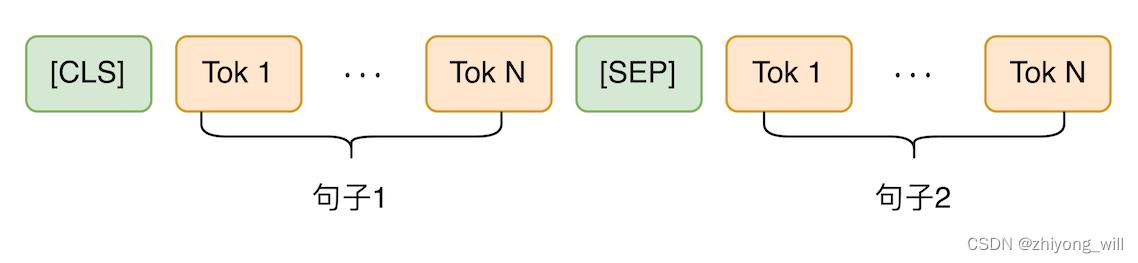
输出是BERT的第一个[CLS]的隐含层向量
C
∈
R
H
C\\in \\mathbbR^H
C∈RH,在Fine-Tune阶段,加上一个权重矩阵
W
∈
R
K
×
H
W\\in \\mathbbR^K\\times H
W∈RK×H,其中,
K
K
K为分类的类别数。最终通过Softmax函数得到最终的输出概率。
第二,单个句子的分类。相对于句子对的分类任务来说要简单,其输入是单个句子,如下图所示:
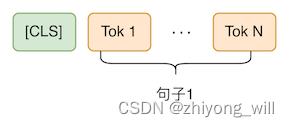
其输出同句子对分类的输出。
第三,问答任务,其输入如句子对的输入,不同的是第一个句子是问题,第二个句子是段落。
第四,针对每个词的tagging,其输入如单个句子的输入,输出是针对每个token的隐含层输出进行tagging。
3. 总结
BERT模型的提出对于NLP预训练的效果有了较大提升,在ELMo模型的基础上使用了Self-Attention作为文本特征的挖掘,同时避免了GPT模型中的单向语言模型,充分利用文本中的上下文特征。
参考文献
[1] Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[2] Peters M , Neumann M , Iyyer M , et al. Deep Contextualized Word Representations[J]. 2018.
[3] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[5] Transformer的基本原理
[6] https://github.com/google-research/bert
以上是关于BERT模型解析的主要内容,如果未能解决你的问题,请参考以下文章