正则表达式学习之一
Posted sysu_zjl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式学习之一相关的知识,希望对你有一定的参考价值。
这次爬取页面所用到的正则表达式
\\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \\f\\r\\n\\t\\v]
\\S 匹配任何非空白字符,等价于 [^ \\f\\n\\r\\t\\v]。
\\w 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。
. 匹配除 “\\n” 之外的任何单个字符
* 匹配前面的子表达式0次或1次
? 匹配前面的子表达式零次或一次
+ 匹配前面的子表达式一次或多次
[a-z] 匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符
[0-9] 匹配 ‘0’ 到 ‘9’ 范围内的任意字符
[\\s\\S] 匹配任何字符
[\\s\\S]* 匹配0个到任意多个字符
[\\s\\S]*? 匹配任何字符前的位置
用[\\s\\S]*?能发挥出强大功能接下来应用到再细说
这次用到的正则表达式大概就这些但感觉好像面对html的提取已经足够用了
python用于正则表达式的findall()方法
1、
import re
s = "adfad asdfasdf asdfas asdfawef asd adsfas "
reObj1 = r'((\\w+)\\s+\\w+)'
re.findall(reObj1, s) [(‘adfad asdfasdf’, ‘adfad’), (‘asdfas asdfawef’, ‘asdfas’), (‘asd adsfas’, ‘asd’)]
\\w+匹配一个单词 \\s匹配空白字符
((\\w+)\\s+\\w+) 其中的第一个 \\w+
‘adfad asdfasdf’ => ‘adfad’
‘asdfas asdfawef’ => ‘asdfas’
‘asd adsfas’ => ‘asd’
当给出的正则表达式中带有多个括号时,列表的元素为多个字符串组成的tuple,tuple中字符串个数与括号对数相同,字符串内容与每个括号内的正则表达式相对应,并且排放顺序是按括号出现的顺序。
2、
reObj2 = r'(\\w+)\\s+\\w+'
re.findall(reObj2, s) [‘adfad’, ‘asdfas’, ‘asd’]
当给出的正则表达式中带有一个括号时,列表的元素为字符串,此字符串的内容与括号中的正则表达式相对应(不是整个正则表达式的匹配内容)。
3、
reObj3 = re.compile('\\w+\\s+\\w+')
reObj3.findall(s) [‘adfad asdfasdf’, ‘asdfas asdfawef’, ‘asd adsfas’]
当给出的正则表达式中不带括号时,列表的元素为字符串,此字符串为整个正则表达式匹配的
接着我们先看下我们需要抓取的文章页面,及html


我们现在要爬取时间,我们先观察html上标记时间的样式有什么特点

1、
在时间左边 class=”time”在html上是唯一能找到的,这就好办了
re_time = r’class=”time”[\\s\\S]*?>([0-9]+-[0-9]+-[0-9]+)<’
create_time = re.findall(re_time, html)
print create_time[0]这里的
[\\s\\S]*?匹配class=”time”到第一个尖括号’>’中的任何字符(包括0个字符)
[0-9]+匹配1个以上的数字
-匹配-
括号()代表提取括号内的字符串
如果要匹配(需加转义字符(
([0-9]+-[0-9]+-[0-9]+)对应的匹配2016-08-07这串字符串
运行上段代码如下

接着我们需要爬取文章内容了

同样的先找到文章内容前的唯一标志进行爬取,由于这里要爬取的内容后面不能通过匹配尖括号来唯一缺点所以还需要找文章内容后的唯一标签

文章内容后的唯一标签

re_content=r'class="arc-body mt20 clearfix”[\\s\\S]*?>([\\s\\S]*)</div[\\s\\S]*?class="end-source"'
content = re.findall(re_content, html)
print content[0]第一个[\\s\\S]*?匹配类型名到第一个尖括号之间的任意字符或空白字符

第三个[\\s\\S]*?匹配</div到class=”end-source”之间的字符
第二个[\\s\\S]*尽可能匹配某个字符串前多个字符
观察[\\s\\S]*后面的正则表达式可发现
第二个[\\s\\S]*会匹配到离class=”end-source”最近一个</div后停止

即为我们所想要的文章内容

这里可以想想用
a、re_content=r'class=”arc-body mt20 clearfix”[\\s\\S]*?>([\\s\\S]*)</div'
b、re_content=r'class=”arc-body mt20 clearfix”[\\s\\S]*?>([\\s\\S]*?)</div'用a、的话会匹配到整个html最后的</div
用b、的话会匹配到第一个</div从图中可以分析到文章内容也包含了</div
所以都无法正确匹配
接着整理文章内容,除去<span>、</span>、<br>、<br/>标签
并将img标签嵌套一层<p></p> 标签
首先讲去除span标签的
reobj = re.compile(r’<span[\\s\\S]*?>’)
s = reobj.sub(‘’, content[0])利用python中的sub函数进行正则表达式的替换
<span[\\s\\S]*?>匹配了<span>及<span class=””>和这些类似的span属性标签
并将他们替换为空,赋值给s字符串
前后对比
前:

后:

接着</span>、<br/> 、<br>这些都直接用python的replace函数替换为空,不缀述。
接着我们希望在img外嵌套一层<p>,这个首先观察img标签附近都有何格式,这里就把一些文章中img嵌套情况整合在这
嵌套在<center>上

不被任何标签嵌套的<img>

被div嵌套

#获得所有img标签,并在前后加<p>,</p>
reobj = re.compile(r'<img[\\s\\S]*?>')
img_list = re.findall(reobj, s)
for i 从 0 到img_list.__len__()
s = s.replace(img_list[i], '<p>'+img_list[i]+'</p>')
#同时去除div标签,及center标签
reobj = re.compile(r'<div[\\s\\S]*?>')
s = reobj.sub('', content[0])
s = s.replace('</div>', '')结果

并把img标签中除去src的其他属性去掉
reobj = re.compile(r'(<img[\\s\\S]*?(src="[\\s\\S]*?")[\\s\\S]*?>)')
img_list = re.findall(reobj, s)
for i 从 0 到img_list.__len__()
s = s.replace(img_list[0][0], '<img ' + img_list[0][1] + '>')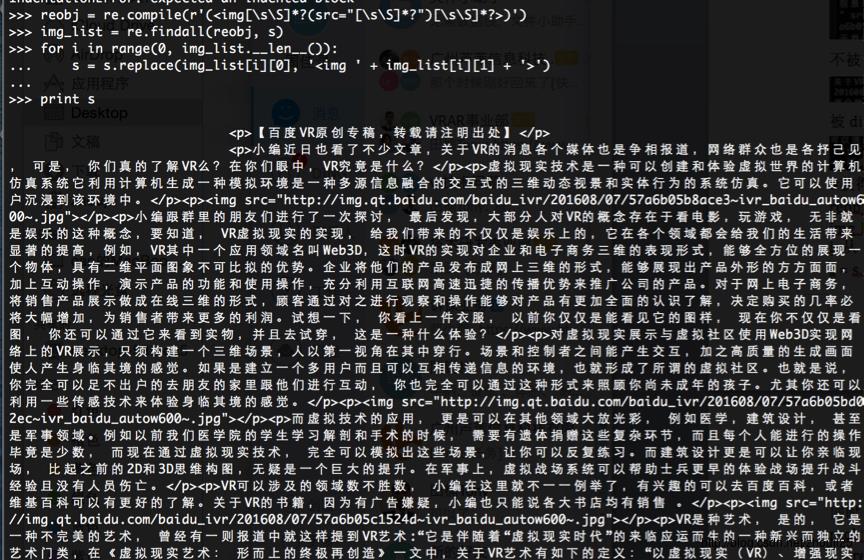
去<p>标签前面的空白符
reobj = re.compile(r’\\s+<p>’)
s = reobj.sub(‘’<p>, s)
#去除<p></p>内容中一些某网站特有句子
reobj = re.compile(r'(<p[\\s\\S]*?/p>)')
p_content= re.findall(reobj, s)
for i 从 0 到 p_content.__len__()
if p_content[i].find('百度VR原创专稿') != -1:
s = s.replace(p_content[i], '')大概就这些,正则表达式的语法,规则可以查看以下网站
http://www.runoob.com/regexp/regexp-syntax.html
以上是关于正则表达式学习之一的主要内容,如果未能解决你的问题,请参考以下文章