抛开spark-submit脚本提交spark程序
Posted 拱头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了抛开spark-submit脚本提交spark程序相关的知识,希望对你有一定的参考价值。
在往yarn中提交spark程序的时候,需要使用到spark-submit脚本,spark-submit脚本会启动SparkSubmit类,再反射启动用户写的spark程序。如果我们能够抛开spark-submit脚本和SparkSubmit类启动spark程序,那么spark程序就能够方便的镶嵌到其他大型程序中,为其他程序提供计算引擎,例如镶嵌到tomcat中,为web程序提供守护程序。 为了解决以上问题,首先想到的是要抛弃spark-submit,保证能够用java指令提交spark程序到yarn中。具体的分析步骤如下:- 先写一个简单的示例代码用来测试,并打包,这里打包完jar包地址为/root/IdeaProjects/java-scala-practice/target/java-scala-practice-1.0.jar:
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.SparkConf , SparkContext
object StartSparkWithoutSparkSubmit
def main(args: Array[ String])
val sparkConf = new SparkConf().setAppName( "local-yarn-test")
val sc = new SparkContext(sparkConf)
val hc = new HiveContext(sc)
hc.sql( "select * from pokes").show()
- 查看spark-submit脚本是如何提交程序的,看到spark-submit是调用spark-class提交代码的。在spark-class脚本的最后,执行了exec "$CMD[@]",猜测应该是使用这行指令将程序提交到yarn上的。使用echo "$CMD[@]"把这行指令打印出来,看看具体是什么指令。

- 使用spark-submit提交代码,查看打印信息,执行指令,$SPARK_HOME/bin/spark-submit --master yarn --verbose --class spark.freedomstart.StartSparkWithoutSparkSubmit /root/IdeaProjects/java-scala-practice/target/java-scala-practice-1.0.jar,其中 --verbose参数是用来打印debug信息的,看到控制台弹出上一步的echo的信息,可以知道spark-class其实是用java启动了SparkSubmit来提交用户写的代码:

- 通过查看SparkSubmit类的源码,用户写的spark程序通过SparkSubmit中的submit->runMain方法启动,runMain方法有childArgs, childClasspath, sysProps, childMainClass四个参数影响用户提交的程序,先用--verbose,将四个参数使用spark-submit提交的时候,对应的内容打印出来。再看看能不能直接将这部分内容添加到用户程序中。这就可以抛开spark-submit脚本执行了。
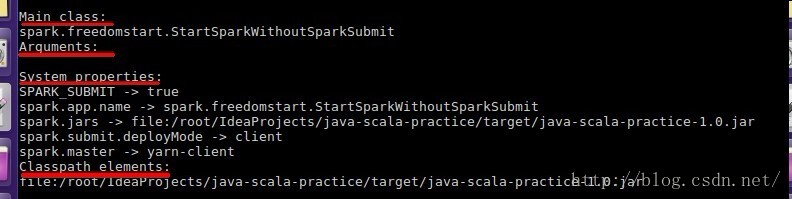
可以看到4个参数的内容,Main class 和 Arguments就是启动的主类和参数,没什么好说的。System properties使用System.setProperty 加入到系统变量中;Classpath elements 是程序需要使用到的额外classpath,这部分包括--jars配置的jar包路径也要加进来,在提交程序的时候 使用java -cp指定。
- 通过以上几步分析,现在可以尝试修改代码,增加需要的配置,使用java指令尝试提交。
- 修改StartSparkWithoutSparkSubmit代码,增加需要的配置。
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.SparkConf , SparkContext
/**
* 以下程序可以直接使用 java 指令 启动 ,不需要使用 spark-submit 启动 ,也能 让 spark 程序提交到 yarn 中。
* 脱 离 spark-submit 脚本和 SparkSubmit 类 ,能 够 令 spark 程序更好的 镶 嵌到其他大型程序中。
*/
object StartSparkWithoutSparkSubmit
System. setProperty( "SPARK_SUBMIT" , "true")
System. setProperty( "spark.jars" , "file:/root/IdeaProjects/java-scala-practice/target/java-scala-practice-1.0.jar")
System. setProperty( "spark.submit.deployMode" , "client")
System. setProperty( "spark.master" , "yarn-client")
def main(args: Array[ String])
val sparkConf = new SparkConf().setAppName( "local-yarn-test")
val sc = new SparkContext(sparkConf)
val hc = new HiveContext(sc)
hc.sql( "select * from pokes").show()
- 使用java指令提交spark代码,java指令需要使用 -cp参数,参数中加入的路径报错,spark的lib路径,scala的lib路径,spark的配置文件路径,hadoop的配置文件路径,用户jar包的路径和spark提交的时候--jars用到的jar包的路径。在本例中,指令如下:
/usr/local/spark/spark-1.6.1-bin-hadoop2.6/lib/*:\\
/usr/local/spark/spark-1.6.1-bin-hadoop2.6/conf/:\\
/usr/local/spark/spark-1.6.1-bin-hadoop2.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar:\\
/usr/local/spark/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:\\
/usr/local/spark/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:\\
/usr/local/spark/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar:\\
/usr/local/hadoop/hadoop-2.6.4/etc/hadoop/:\\
/usr/local/scala/scala-2.10.6/lib/*:\\
/root/IdeaProjects/java-scala-practice/target/java-scala-practice-1.0.jar\\
-Xms1g -Xmx1g spark.freedomstart.StartSparkWithoutSparkSubmit 执行的过程中可能报错java.lang.NoSuchMethodException: akka.remote.RemoteActorRefProvider.<init>,这是因为scala中带的actor版本和spark中akka的actor版本有差异导致的,解决方法也很简单,使用java -cp提交代码的时候,要将$SCALA_HOME/lib/*放在$SPARK_HOME/lib/*后面就可以了。
到此spark程序能够通过java指令提交成功~就是这样使用的时候,参数是静态设置的,不能修改,虽然比较麻烦,但是镶嵌在别的程序中,参数从执行开始就是固定的,也比较合理。
以上是关于抛开spark-submit脚本提交spark程序的主要内容,如果未能解决你的问题,请参考以下文章