vimmakefilegdb
Posted Jocelin47
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了vimmakefilegdb相关的知识,希望对你有一定的参考价值。
makefile
1.makefile规则
命名规则:
makefile
Makefile
makefile三要素:
- 目标
- 依赖(先决条件)
- 规则命令
写法:
目标:依赖1 依赖2
tab键 规则命令
当“依赖”比“目标”新,执行命令
比如文件a.c b.c c.c include(include/head.h)
-I包含头文件的地址
app:main.c a.c b.c c.c
gcc -o app -I./include a.o b.o c.o
如果更改其中一个文件,所有的源码都重新编译
可以考虑编译过程分解,变成.o的,更改其中一个只需要改一个就可以了。
比如 b.o: b.c,b.o他依赖于b.c,当b.c比b.o新的时候,使用gcc -c -o b.o b.c.
makefile就是这样只要文件比目标文件新的时候,就会重新编译
或者:
test:a.o b.o
gcc -o test a.o b.o
a.o : a.c
gcc -o a.o -c a.c
b.o : b.c
gcc -o b.o -c b.c
make后 执行命令:
gcc -o a.o -c a.c
gcc -o b.o -c b.c
gcc -o test a.o b.o
再次执行的时候

,提示test已经是最新的了。
如果修改a.c就会只重新编译
gcc -o a.o -c a.c
gcc -o test a.o b.o
make 是通过文件的时间戳来判定哪些文件需要重新编译。通过前面已经提到的目标和先决条件之间的依赖关系, make 在分析一个规则以创建目标时, 如果发现先决条件中文件的时间戳大于目标的时间戳, 即先决条件中的文件比目标更新,就知道需要运行规则当中的命令重新构建目标。这意味着make 在编译项目时对于系统上的时间有一定的要求, 如果人为地变更系统时间或者将一个己编译好的项目拷贝到另一个主机上时,会造成make 不能正常工作。碰到这种问题时,可以尝试通过执行一次make clean 去解决。
2.makefile语法
2.1 从例子了解规则
2.1.1 example1
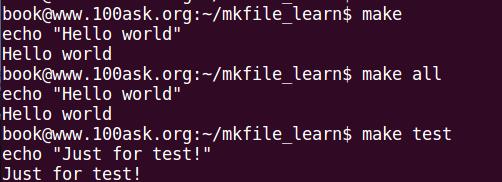
1 all:
2 echo "Hello world"
3 test:
4 echo "Just for test!"
make后的结果为
调换一下顺序:
1 test:
2 echo "Just for test!"
3 all:
4 echo "Hello world"
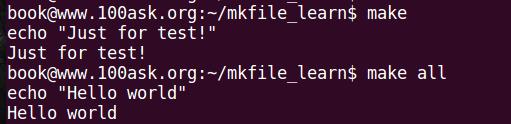
发现make在执行的之后会执行第一个默认的规则
2.1.2 example2
每次make的时候会把命令都输出出来,如果不想make输出命令在前面加入@
1 all:test
2 @echo "Hello world"
3 test:
4 @echo "Just for test!"
2.1.3 example3
1 all:test
2 @echo "Hello world"
3 test:
4 @echo "Just for test!"
输出结果:

从输出结果可以发现,当不带参数运行make 时,构建all 目标之前test 目标先被构建了。
现在需要引入Makefile 中的依赖关系这一概念。
all目标后面的test是告诉make, all目标依赖于test 目标,这个依赖目标又被称为(all 目标的)先决条件。
即:
目标:先决条件(依赖)
命令
2.1.4 example4
最上面刚开始的实例中,可以增加了一个clean 目标用于删除编译所生成的文件,包括目标文件和test可执行程序。
test:a.o b.o
gcc -o test a.o b.o
a.o : a.c
gcc -o a.o -c a.c
b.o : b.c
gcc -o b.o -c b.c
clean:
rm test a.o b.o
由于make在工作时,如果文件时间戳不一致会重新构建,如果最开始的构建目标不是test而是all,如下:
all:a.o b.o
gcc -o test a.o b.o
则每次make的时候发现all文件都不存在,都会重新构建。这是因为Makefile 中的第一条规则中的目标是all ,而all文件在编译过程中并不生成,即make在第二次编译时找不到它,所以又重新构建all目标, 而这导致了test被再一次生成。因此这个例子在一开始把构建的目标改为了test,避免重复构建。
2.2 让makefile更专业
2.2.1 假目标的用处
在example4项目中,假设Makefile 所在目录下存在一个clean 文件(可以通过touch 命令来创建〉。如果此时运行 make clean, 将发现make总是提示clean文件是最新的,而不是按我们所期望的那样对项目进行文件清除操作。
出现这种情形,是因为我们对于clean 目标的定义与make 所理解的有所出入。目录文件名与Makefile 中的目标名重名在现实项目中是难免的,假目标(phony target)概念的提出正是为了解决这种问题的。
假目标采用.PHONY 关键字来定义, 注意必须是大写字母。更新后的makefile如下所示:
.PHONY: clean
test:a.o b.o
gcc -o test a.o b.o
a.o : a.c
gcc -o a.o -c a.c
b.o : b.c
gcc -o b.o -c b.c
clean:
rm test a.o b.o
采用.PHONY 关键字声明一个目标后,make 并不会将其当做一个文件来处理。由于假目标并不与文件关暇,所以每次构建假目标时它所在规则中的命令一定会被执行。
2.2.2 运用“变量提高可维护性”
编写专业的Makefile 同样离不开运用变量,通过使用变量使得Makefile更具可维护性。
.PHONY: clean
CC = gcc
RM = rm
EXE = test
OBJS = a.o b.o
$(EXE):$(OBJS)
$(CC) -o $(EXE) $(OBJS)
a.o : a.c
$(CC) -o a.o -c a.c
b.o : b.c
$(CC) -o b.o -c b.c
clean:
$(RM) -fr $(EXE) $(OBJS )
定义了CC 、RM 、EXE 、OBJS 四个变量。定义变量时其值可以为空,即无右值。引用变量需要采用 $ (变量名) 或 ${变量名}的形式。
引入变量的好处很明显, 比如引入CC变量以后,如果需要更改编译器, 只需更改变量赋值这一个点即可。Makefile 中变量的数据类型,可以理解为C语言中的字符串。
1. 自动变量
上面test项目中,存在目标名和先决条件名在规则的命令中重复出现。如果目标名或先决条件名发生了改变, 那得在相应的命令中跟着改, 这很麻烦。为了省去这种麻烦,我们可以借助如下一些自动变量。
- $ @: 用于表示一个规则中的目标. 当一个规则中有多个目标时,$@所指的是其中任何造成规则命令被运行的目标。
- $^: 表示的是规则中的所有先决条件.
- $<: 表示的是规则中的第一个先决条件.
例子:
1 .PHONY: all
2
3 all: first second third
4 @echo "\\$$@ = $@"
5 @echo "$$^ = $^"
6 @echo "$$< = $<"
7
8 first second third:
上例中还有几个地方需要注意。第一, 在Makefile 中 $ 具有特殊的意思, 如果想采用echo 输出 " $ ",则必须用两个连着的 " $ ";第二,“ $ @”对于Bash Shell 也有特殊的意思, 需要在$$@之前再加一个脱字符‘\\’。make结果为:
$@ = all
$^ = first second third
$< = first
如果把依赖test去掉:
1 .PHONY: all
2
3 all:
4 @echo "\\$$@ = $@"
5 @echo "$$^ = $^"
6 @echo "$$< = $<"
结果为:
$@ = all
$^ =
$< =
因此test项目可以改成:
.PHONY: clean
CC = gcc
RM = rm
EXE = test
OBJS = a.o b.o
$(EXE):$(OBJS)
$(CC) -o $(EXE) $(OBJS)
a.o : a.c
$(CC) -o $@ -c $^
b.o : b.c
$(CC) -o $@ -c $^
clean:
$(RM) -fr $(EXE) $(OBJS )
2. 变量的类别与赋值
(1)递归扩展变量
foo = $(bar)
bar = $(ugh)
ugh = Huh?
all:
@echo $(foo)
结果输出为Huh?
CFLAGS = $(include_dirs) -o
include_dirs = -Ifoo -Ibar
代码中CFLAGS 变量被拓展为-Ifoo -Ibar -o,
一个“=”符号定义的变量被称为递归扩展变量,两个例子的都是递归的进行传递赋值
(2)简单扩展变量
简单扩展变量( simply expanded variable )是用“:=”操作符来定义的.对于这种变量,make 只对其进行一次展开。
objects = main.o foo.o bar.o utils.o
objects := $(objects) another.o
all:
@echo $(objects)
结果为
main.o foo.o bar.o utils.o another.o
(3)条件赋值
条件赋值使用“?=”来实现: 当变量没有被定义时就定义它 ,并将右边的值赋值给它;如果变量已经定义了,则不改变其原值。
foo = x
foo ?= y
bar ?= y
all:
@echo "foo = $(foo), bar = $(bar)"
输出结果为foo= x, bar = y
(4)追加赋值
+= 实现追加赋值
objects = main.o foo.o bar.o utils.o
objects += another.o
all:
@echo $(objects)
结果与 (2)简单扩展变量 中的效果一致。
(5)变量及其值的来源
-
①对于自动变量,其值在每个规则中根据规则的上下文自动获得的。
-
②在运行make 时,通过命令参数定义变量。
通过make bar=x的形式运行下面的makefile文件foo = x foo ?= y bar ?= y all: @echo "foo = $(foo), bar = $(bar)"输出为:foo = x, bar = x
运行make foo=haha
结果为:foo = haha, bar = y -
③变量还可以来自于Shell 环境
对于上面的例子,在shell终端下使用export bar = x,再使用make。
输出结果为:foo = x, bar = x

2.2.3 借助“模式”精简规则
.PHONY: clean
CC = gcc
RM = rm
EXE = test
OBJS = a.o b.o
$ (EXE): $ (OBJS)
# $(CC) -o $(EXE) $(OBJS)
$(CC) -o $@ $^
#a.o : a.c
# $(CC) -o $@ -c $^
#
#b.o : b.c
# $(CC) -o $@ -c $^
%.o :%.c
$(CC) -o $@ -c $^
clean:
$(RM) -fr $(EXE) $(OBJS )
test项目与之前自动变量的代码相比,将两条构建目标文件的规则变成了一条.使用通配符的形式,用“%”加以表示。采用了模式以后,不论有多少个源文件要编译那可以应用同一条规则,这极大地简化了Makefile。
2.2.4 通过函数增强功能
下面的代码利用wildcard和patsubst函数实现对test项目拓展,当增加源文件时,并不需要对makefile进行任何编辑。
.PHONY: clean
CC = gcc
RM = rm
EXE = test
SRC = $(wildcard *.c)
OBJS = $(patsubst *.c, %.o, $(SRCS))
#OBJS = a.o b.o
$ (EXE): $ (OBJS)
# $(CC) -o $(EXE) $(OBJS)
$(CC) -o $@ $^
#a.o : a.c
# $(CC) -o $@ -c $^
#
#b.o : b.c
# $(CC) -o $@ -c $^
%.o :%.c
$(CC) -o $@ -c $^
clean:
$(RM) -fr $(EXE) $(OBJS )
1. wildcard
wildcard是通配符函数,通过它可以得到工作目录中满足_pattern模式的文件或目录名列表。其形式是:
$(wildcard _pattern)
下面就是makefile目录中通过wildcard函数得到所有C源文件的名字列表:
SRCS = $(wildcard *.c)
all:
@echo $(SRC)
2. patsubst
patsubst 函数被用来将名字列表_text 中符合_pattern 模式的名字替换为_replacement 。
$(patsubst _pattern, _replacement, _text)
如目录下有a.c b.c c.c
SRCS = $(wildcard *.c) # 把当前目录下所有的.c文件选择
OBJS = $(patsubst %.c, %.o, $(OBJS)) # 再将SRCS中所有的.c替换成.o
all:
@echo $(OBJS)
输出结果为:a.o b.o c.o
3. abspath
abspath 函数被用于将每一names 中的各路径名转换成绝对路径,并将转换后的结果返回。
$(abspath _name)
ROOT = $(abspath /usr/../lib)
all:
@echo $(ROOT)
结果:
/lib
4. addprefix
addprefix函数被用于给名字列表_names 中的每一个名字增加前缀_prefix,并返回。
$(addprefix _prefix, _name)
without_dir = a.c b.c c.c
with_dir := $(addprefix objs/, $(without_dir))
all:
@echo $(with_dir)
结果:
objs/a.c objs/b.c objs/c.c
5. addsuffix
addsuffix函数被用于给名字列表_names 中的每一个名字增加后缀_suffix,并返回。
$(addsuffix _suffix, _name)
without_suffix = a b c
with_dir := $(addsuffix .c, $(without_suffix))
all:
@echo $(with_dir)
结果:
a.c b.c c.c
6. filter
filter 函数被用于从一个名字列表_text 中根据模式_pattern 得到满足需要的名字列表并返回。
$(filter _pattern, _text)
sources = a.c b.c c.s c.h
sources := $(filter %.c %.s, $(sources))
all:
@echo $(sources)
结果为a.c b.c c.s
7. filter-out
filter-out 函数被用于从一个名字列表_text 中根据模式_pattern滤除一部分名字,并返回。
$(filter-out _pattern, _text)
objects = main1.o main2.o foo.o bar.o
objects := $(filter-out main%.o, $(objects))
all:
@echo $(objects)
结果为foo.o bar.o
8. realpath
获取_names 所对应的真实路径名
$(realpatht _names)
ROOT := $(realpatht ./。。)
all:
@echo $(ROOT)
pwd
/home/project
make
/home
9. strip
消除名字列表中的多余空格(字符串)
ori = foo.c bar.c
stripped := $(strip $(ori))
all:
@echo "$(ori)"
@echo "$(stripped)"
#@echo $(ori) 如果没有双引号结果都是foo.c bar.c 没有多余空格
foo.c bar.c
foo.c bar.c
gdb
使用gdb:编译的时候加-g
启动gdb: gdb app(对应程序名)
run:直接运行完
start:运行到main函数之前
next/n:执行下一条指令
step/s:执行下一条指令,跟next的区别是可以进入到函数内部(库函数不能进)
quit:退出gdb
set args 10 6: 设置启动参数:传入的第1,第2个参数,即会设置参数argv[1]为10、argv[2]为6
或者run 10 6 效果是一样的
此时argc为3.如果我们不指定输入的参数,argc是=1的,我们可以在程序运行的时候认为的修改变量的值:比如:set argc = 3
但是argv没有设置,set argv[1] =“12”、set argv[2]=“7”
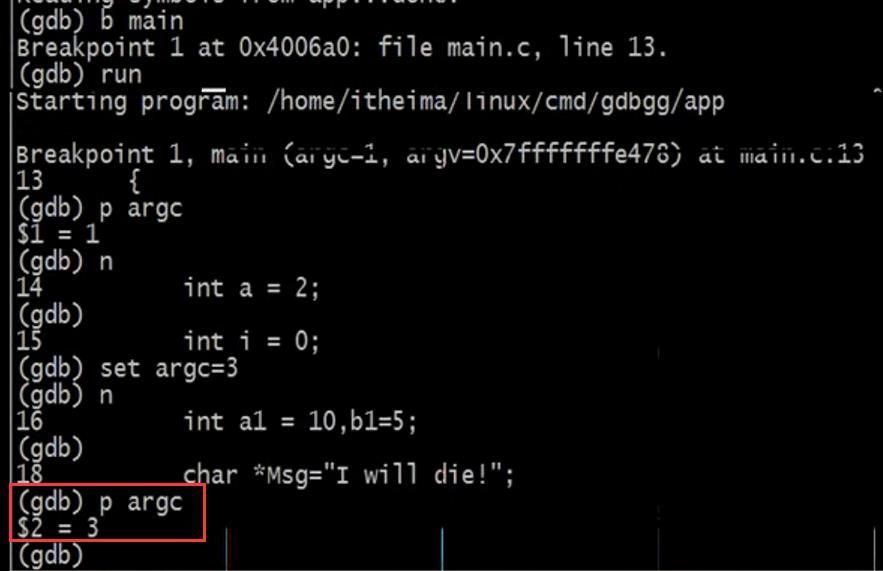

list:查看代码,默认是10行,只能看到主函数,再按list接着显示
list a.c:1 ----- 查看a.c的第1行开始,直接list a.c是不可以的
break/b:
b 17 ----- 在17行设置断点,run的时候直接停留在断点
b sum -----sum是一个函数的名字,直接在函数打断点
b main.c:25 ----- 设置main.c的25行打断点
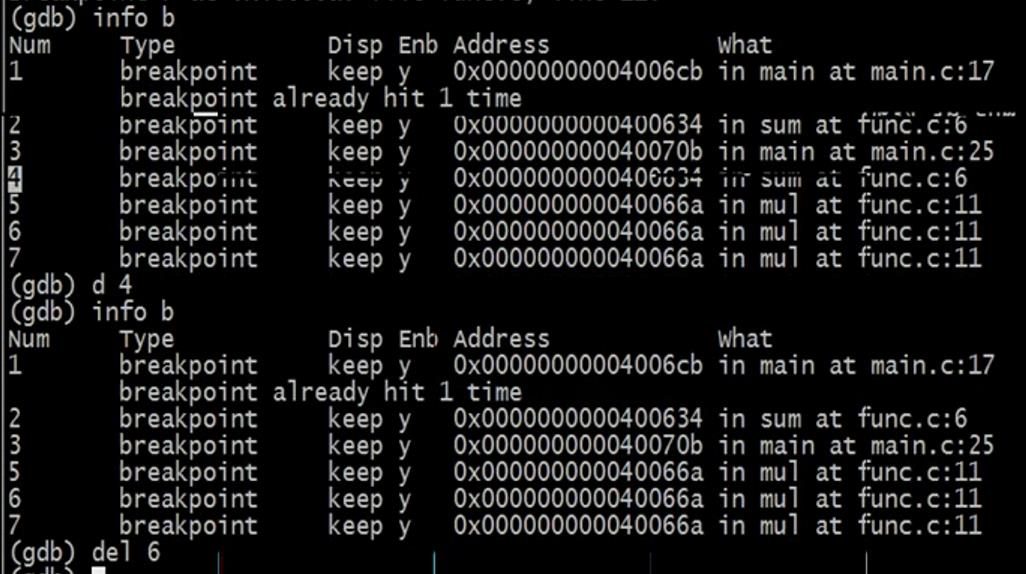
info break:查看所有的断点
delete 4:删除4号断点
-
conitnue/c:跳到下一个断点
-
print/p argc
p命令不仅可以打变量,结构体的信息都可以打印出来

-
ptype i
查看变量类型
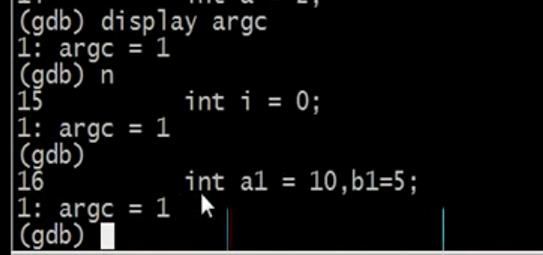
display:跟踪变量
跟踪argc变量,每执行一个指令都会把变量的值打印出来
想要删除跟踪的变量,也是info dispaly
undisplay 1 (这时候不能用红del去删了,因为del删的是断点,这个时候用undisplay + 变量的编号)
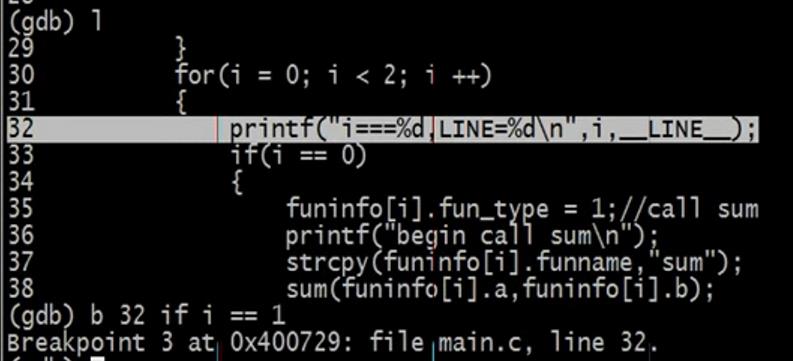
条件断点:
当for循环里面当i = 1的时候进行打断点,我就不需要自己人工跳到i=1的情况。
语法:b line if i ==1
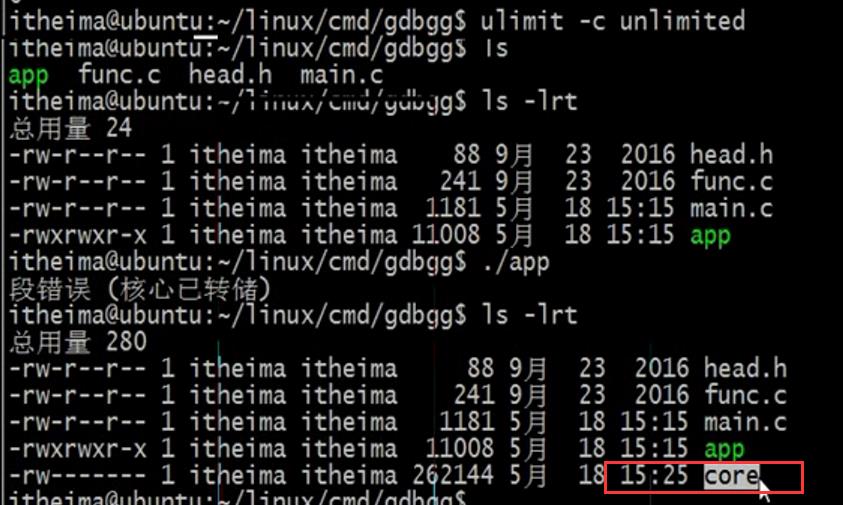
我们使用gdb还是为了调试bug,但是bug在哪你都不知道,调试bug的方法要么产生日志,要么使用gdb。
- gdb跟踪core(段错误调试)
ulimit -c :查看core文件大小 ulimit -c 1024 / ulimit -c unlimited
:用于指定存放生成的core文件的大小为1024或者无限制大小
发现运行完成程序后,会生成一个core文件,相当于案发现场
-
如何使用core文件查看调试
gdb app core
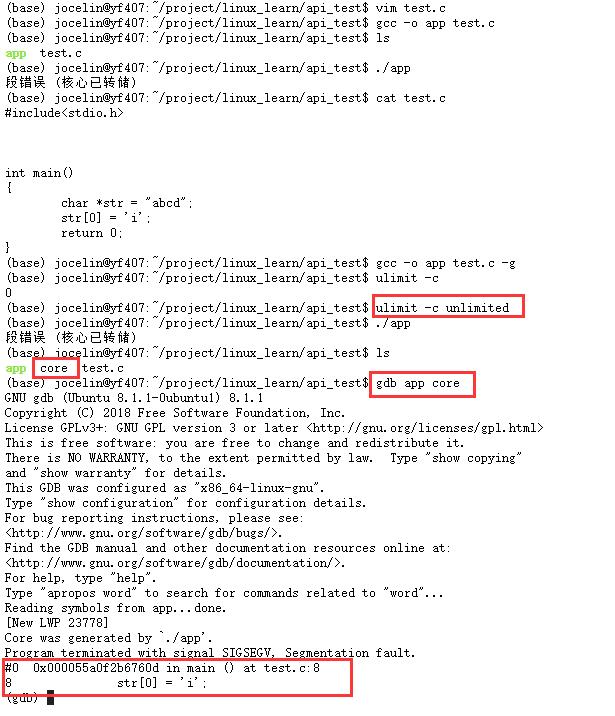
此时就可以看到我们代码出现的问题的位置了
取消core文件的话使用ulimit -c 0 -
通过where文件查看代码崩溃位置
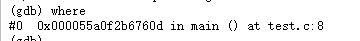
-
自定义core文件的格式信息
通过修改/proc/sys/kernel/core_pattern

使用下面的命令导入到core_pattern文件夹中
sudo su#进入root账户
echo "core-%e-%t" > /proc/sys/kernel/core_pattern
exit

-
info threads 查看不同的线程
-
thread n 进入到对应的线程编号
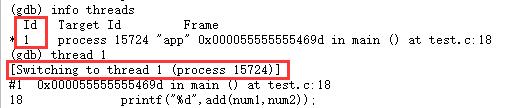
-
bt 查看栈的信息
-
frame n切换不同程序的栈

以上是关于vimmakefilegdb的主要内容,如果未能解决你的问题,请参考以下文章