《最新开源 随插即用》SAM 自增强注意力深度解读与实践(附代码及分析)
Posted cv君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《最新开源 随插即用》SAM 自增强注意力深度解读与实践(附代码及分析)相关的知识,希望对你有一定的参考价值。
写在前面
大家好,我是cv君,前段时间忙碌工作,许久没更新,越发觉得对不起csdn的读者们,决定继续加油保持更新,保持一周2-3篇的高频率和高质量文章更新:论文分析、代码讲解、代码实操和训练、优化部署技巧。 今天更新一篇注意力的最新文章,附带代码,就在上周开源的代码,我觉得还是凑合的一份工作,可圈可点,我把他优秀的东西分析一下,看看大家能不能拿过来到大家的工作中使用,并附带一些使用教学。好的,正文开始。
自增强注意机制(SAM)简介
细粒度视觉识别的挑战通常在于发现关键的判别区域。虽然可以从大规模标记的数据集中自动识别这些区域,但当只有少数注释可用时,类似的方法可能会变得不那么有效。在低数据状态下,网络通常难以选择正确的识别区域,并且往往过度拟合训练数据中的虚假相关模式。
为了解决这个问题,本文提出了自增强注意机制,这是一种新的方法,用于正则化网络,以关注样本和类之间共享的关键区域。
方法流程:
1:该方法首先为每个训练图像生成注意力图,突出用于识别地面真实对象类别的判别部分。
2: 将生成的注意力图用作伪注释。强制网络将其作为辅助任务。
作者将这种方法称为自增强注意力机制(SAM)。并开发了一种变体,使用SAM以双线性池的方式创建多个注意力映射到池卷积映射,称为SAM双线性,涨点更多一些罢了,实际的Flops多少,我还没去查看。
对于方法流程1,作者是通过CAM 和Grad CAM 的注意力机制,获得注意力图,这是其SAM的基础。
CAM 通过将输出层的权重投影回卷积特征图来识别图像区域的重要性。CAM适用于使用全局平均池(GAP)层和分类器层作为最后两层的神经网络架构。
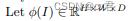 表示最后一个卷积层的激活特征图,其中I是输入图像,H、W和D分别是特征图的高度、宽度和通道数。因此,类y的logit,即softmax之前的决策值,可以计算为:
表示最后一个卷积层的激活特征图,其中I是输入图像,H、W和D分别是特征图的高度、宽度和通道数。因此,类y的logit,即softmax之前的决策值,可以计算为:

其中,Wy是第y类的分类器, GAP表示全球平均池. 表示位于第(i,j)网格的特征向量。类y的类激活图(CAM)定义为:
表示位于第(i,j)网格的特征向量。类y的类激活图(CAM)定义为:
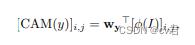
其中CAM(y)表示第y类的CAM。[CAM(y)]i,j表示第(i,j)个空间网格的重要性值。
CAM与GradCAM简述
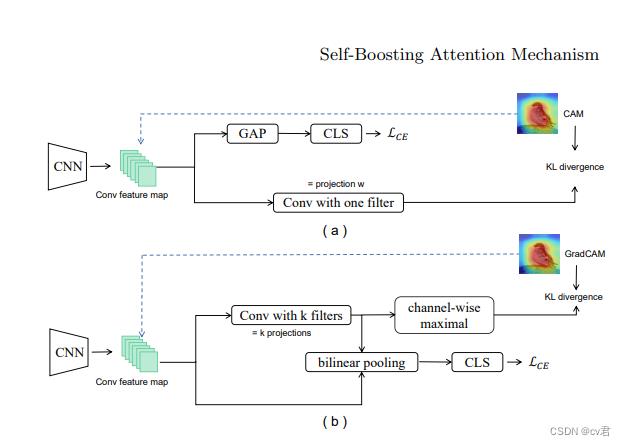
接着作者展示了基于CAM 和GradCAM的方法实现的SAM方案。
在上半部分(a),CNN网络中的最后一个卷积层特征映射通过全局平均池(GAP)和分类器(CLS)通过交叉熵损失函数CE。
这些通过线性投影的特征图也被强制用于拟合CAM生成的注意力图。下半部分(b)表示在双线性池中开发的方法。将多重投影应用于卷积特征映射以获得多个部分检测器。然后使用双线性池操作来获得新的特征表示。经过多次投影和通道最大化操作后的特征图也被强制用于拟合GradCAM生成的注意力图。
SAM改进策略
作者实验发现,训练样本的数量变小时,这种端到端训练策略在识别关键区域方面变得不那么有效。在这种情况下,虚假相关性和真实判别模式变得难以区分,网络经常错误地利用前者,导致泛化能力差。
作者首先计算CAM或者GradCAM等注意力的特征图,通过线性投影w强制ɕ(I)拟合g(In,yn)∈ 在不向网络提供groundtruth类信息的情况下进行R D,这可以实现为应用带有单个滤波器的卷积层

然后作者使用KL散度计算合并注意力图相关的计算损失:
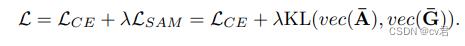
作者自问自答: SAM Loss 的引入似乎有点违反直觉。注意力图是从当前模型生成的,为什么认为模型拟合它会带来任何好处?
为了理解它的效果,我们应该注意到注意力图是基于GT真值类计算的。例如,如果我们使用CAM计算注意力图,则CAM通过w计算,即,选择与地面真值类yn对应的分类器来生成CAM。相反,投影向量w是类不可知的。因此,w⊤ν(I)倾向于适合所有类和实例的共享的公共部分。于是就创建了一个用于鼓励网络使用常见模式的归纳偏差进行预测的关键部分。我们将这种机制称为自增强注意力机制,因为模型将通过拟合其自身的注意力图来增强。
实验结论
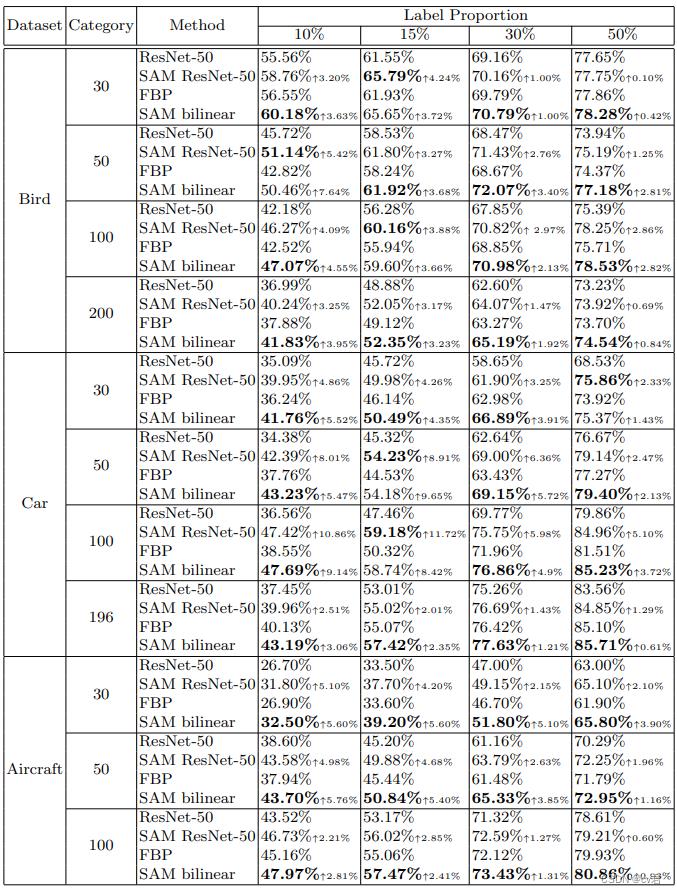
基于这个方法,在数据比例只有原有的10%情况下,提高了3%~10%,但是在数据量较多情况下,有0.几到2%左右的增长,整体来说,提升不是特别高,数据量越小提升越高。所以作者一直称在小数据中获得较高的提升。
不过有2%的提升,也还算不错了,毕竟现在很多水文可能至于0.1%的提升、更有甚者,拿久远的网络对比。
最后,作者和双线性池方法的sota网络做了对比:
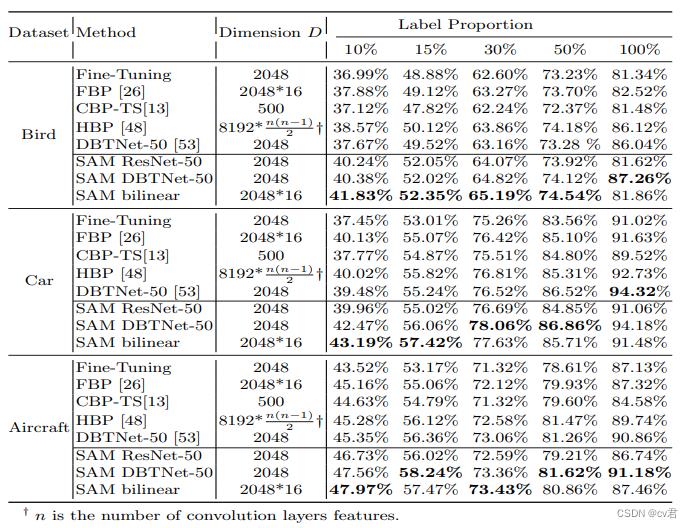
emm,我们仔细分析一下这个表:
DBTNet-50 在100% 数据时准确率 86.04%,作者的:SAM ResNet-50 时81.26,说明了resnet 和DBTNet 差距较大;作者的SAM bilinear(线性版本):81.86%,说明了线性版本普遍比原始版本好;另外作者在DBTNet基础上,加上了SAM注意力,达到了87.26%的准确率,提升了1.22%,还凑合,不过在数据量仅有10%时,却比DBTNet提高了4%,说明了这个SAM在小数据情况更好。

这是网络的注意力可视化

可以看到这个工作的方法远好于Resnet50学到的,也好于FBP方法。
我们做工程的,不要被论文世界迷惑了,年轻人,你把握不住的。比如,这篇工作我刚刚说到100%数据时提高了1%左右,那么他的Flops带来了多少的增长,他的速度带来了多少的下降呢?接下来,我们一起来看看代码,看看是否适合我们~
如果是打比赛,那无脑上,精度有提高就行,很多比赛不限制时间得分,我也是拿过很多比赛奖的老玩家了,比赛堆砌和工程优化,和学术优化,是不一样滴~ 不过以前我打的天池万人赛,和其他平台的比赛,还是有时间得分的哦~
代码解读
首先,SAM模块是串联在你的Backbone后的,不像其他注意力机制是在卷积后的。他的Flops上升并不高。可以接受。

class SAM(nn.Module):
def __init__(self, network, backbone, projector_dim=1024, class_num=200, pretrained=True,
pretrained_path=None):
"""
network: the network of the backbone
backbone: the name of the backbone
feature_dim: the dimension of the output from the backbone
class_num: the class number of the dataset
pretrained: loading from pre-trained model or not (default: True)
pretrained_path: the path of the pre-trained model
"""
super(SAM, self).__init__()
self.class_num = class_num
self.backbone = backbone
self.pretrained = pretrained
self.pretrained_path = pretrained_path
# create the encoders
self.encoder = network(projector_dim=projector_dim)
self.load_pretrained(network)
self.conv16 = nn.Conv2d(512, 16, kernel_size=1, stride=1, padding=0,
bias=False)
self.bn16 = nn.BatchNorm2d(16)
self.bncbp = nn.BatchNorm1d(500)
self.bncbp.bias.requires_grad_(False)
nn.init.constant_(self.bncbp.weight, 1)
nn.init.constant_(self.bncbp.bias, 0)
self.mcb = CompactBilinearPooling(512, 16, 500).cuda()
self.relu = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(7, stride=1)
def forward(self, im_q):
q_c, q_f, featmap_q = self.encoder_q(im_q)
# print()
featcov16 = self.conv16(featmap_q)
featcov16 = self.bn16(featcov16)
# bp————————————————————————
feat_matrix = torch.zeros(featcov16.size(0), 16, 512)
for i in range(16):
matrix = featcov16[:, i, :, :]
matrix = matrix[:, None, :, :]
matrix = matrix.repeat(1, 512, 1, 1)
PFM = featmap_q * matrix
aa = self.avgpool(PFM)
feat_matrix[:, i, :] = aa.view(aa.size(0), -1)
bp_out_feat = feat_matrix.view(feat_matrix.size(0), -1)
'''
#CBP
cbp_dim = 500
N,C1,H,W = featcov16.shape
_,C2,_,_ = featmap_q.shape
feat_part = featcov16.clone().permute(0,2,3,1).contiguous().view(-1,C1)
feat_whole = featmap_q.clone().permute(0,2,3,1).contiguous().view(-1,C2)
bp_out_feat = self.mcb(feat_whole.cuda(), feat_part.cuda())
bp_out_feat = bp_out_feat.view(N,H,W,cbp_dim).permute(0,3,1,2).contiguous()
bp_out_feat = bp_out_feat.view(N,cbp_dim,-1).sum(-1)
bp_out_feat = self.bncbp(bp_out_feat.cuda())
'''
return q_f, featmap_q, featcov16, bp_out_feat
def load_pretrained(self, network):
if 'resnet' in self.backbone:
q = network(projector_dim=1000, pretrained=self.pretrained)
# temp =q.fc
self.encoder_q = q
# self.encoder_q.fc = nn.Linear(in_features=2048, out_features= 1000, bias=True)
# print()
def inference(self, img):
y, feat, featmap = self.encoder_q(img)
featcov16 = self.conv16(featmap)
featcov16 = self.bn16(featcov16)
featcov16 = self.relu(featcov16)
feat_matrix = torch.zeros(featcov16.size(0), 16, 512)
for i in range(16):
matrix = featcov16[:, i, :, :]
matrix = matrix[:, None, :, :]
matrix = matrix.repeat(1, 512, 1, 1)
PFM = featmap * matrix
aa = self.avgpool(PFM)
feat_matrix[:, i, :] = aa.view(aa.size(0), -1)
bp_out_feat = feat_matrix.view(feat_matrix.size(0), -1)
'''
# CBP
cbp_dim = 500
N, C1, H, W = featcov16.shape
_, C2, _, _ = featmap_q.shape
feat_part = featcov16.clone().permute(0, 2, 3, 1).contiguous().view(-1, C1)
feat_whole = featmap_q.clone().permute(0, 2, 3, 1).contiguous().view(-1, C2)
bp_out_feat = self.mcb(feat_whole.cuda(), feat_part.cuda())
bp_out_feat = bp_out_feat.view(N, H, W, cbp_dim).permute(0, 3, 1, 2).contiguous()
bp_out_feat = bp_out_feat.view(N, cbp_dim, -1).sum(-1)
bp_out_feat = self.bncbp(bp_out_feat.cuda())
'''
# return bp_out_feat, featcov16
return feat.cuda(), featcov16
这边是SAM的模块细节,
class BaseCAM:
def __init__(self,
model,
target_layers,
use_cuda=False,
reshape_transform=None,
compute_input_gradient=False,
uses_gradients=True):
self.model = model.eval()
self.target_layers = target_layers
self.cuda = use_cuda
if self.cuda:
self.model = model.cuda()
self.reshape_transform = reshape_transform
self.compute_input_gradient = compute_input_gradient
self.uses_gradients = uses_gradients
self.activations_and_grads = ActivationsAndGradients(
self.model, target_layers, reshape_transform)
""" Get a vector of weights for every channel in the target layer.
Methods that return weights channels,
will typically need to only implement this function. """
def get_cam_weights(self,
input_tensor,
target_layers,
target_category,
activations,
grads):
raise Exception("Not Implemented")
def get_loss(self, output, target_category):
loss = 0
for i in range(len(target_category)):
loss += output[1][target_category[i]]
# loss = loss + output[i][target_category[i]]
# loss = loss + output[i, target_category[i]]
return loss
def get_cam_image(self,
input_tensor,
target_layer,
target_category,
activations,
grads,
eigen_smooth=False):
global weights
weights = self.get_cam_weights(input_tensor, target_layer,
target_category, activations, grads)
weighted_activations = weights[:, :, None, None] * activations
if eigen_smooth:
cam = get_2d_projection(weighted_activations)
else:
cam = weighted_activations.sum(axis=1)
return cam
def forward(self, input_tensor, target_category=None, eigen_smooth=False):
if self.cuda:
input_tensor = input_tensor.cuda()
if self.compute_input_gradient:
input_tensor = torch.autograd.Variable(input_tensor,
requires_grad=True)
output = self.activations_and_grads(input_tensor)
if isinstance(target_category, int):
target_category = [target_category] * input_tensor.size(0)
if target_category is None:
output = output[0]
target_category = np.argmax(output.cpu().data.numpy(), axis=-1)
else:
assert(len(target_category) == input_tensor.size(0))
if self.uses_gradients:
self.model.zero_grad()
loss = self.get_loss(output, target_category)
loss.backward(retain_graph=True)
# In most of the saliency attribution papers, the saliency is
# computed with a single target layer.
# Commonly it is the last convolutional layer.
# Here we support passing a list with multiple target layers.
# It will compute the saliency image for every image,
# and then aggregate them (with a default mean aggregation).
# This gives you more flexibility in case you just want to
# use all conv layers for example, all Batchnorm layers,
# or something else.
cam_per_layer = self.compute_cam_per_layer(input_tensor,
target_category,
eigen_smooth)
return self.aggregate_multi_layers(cam_per_layer), weights
def get_target_width_height(self, input_tensor):
width, height = input_tensor.size(-1), input_tensor.size(-2)
return width, height
def compute_cam_per_layer(
self,
input_tensor,
target_category,
eigen_smooth):
activations_list = [a.cpu().data.numpy()
for a in self.activations_and_grads.activations]
grads_list = [g.cpu().data.numpy()
for g in self.activations_and_grads.gradients]
target_size = self.get_target_width_height(input_tensor)
cam_per_target_layer = []
# Loop over the saliency image from every layer
for target_layer, layer_activations, layer_grads in \\
zip(self.target_layers, activations_list, grads_list):
cam = self.get_cam_image(input_tensor,
target_layer,
target_category,
layer_activations,
layer_grads,
eigen_smooth)
scaled = self.scale_cam_image(cam, target_size)
cam_per_target_layer.append(scaled[:, None, :])
return cam_per_target_layer
def aggregate_multi_layers(self, cam_per_target_layer):
cam_per_target_layer = np.concatenate(cam_per_target_layer, axis=1)
cam_per_target_layer = np.maximum(cam_per_target_layer, 0)
result = np.mean(cam_per_target_layer, axis=1)
return self.scale_cam_image(result)
def scale_cam_image(self, cam, target_size=None):
result = []
for img in cam:
img = img - np.min(img)
img = img / (1e-7 + np.max(img))
if target_size is not None:
img = cv2.resize(img, target_size)
result.append(img)
result = np.float32(result)
return result
def forward_augmentation_smoothing(self,
input_tensor,
target_category=None,
eigen_smooth=False):
transforms = tta.Compose(
[
tta.HorizontalFlip(),
tta.Multiply(factors=[0.9, 1, 1.1]),
]
)
cams = []
for transform in transforms:
augmented_tensor = transform.augment_image(input_tensor)
cam = self.forward(augmented_tensor,
target_category, eigen_smooth)
# The ttach library expects a tensor of size BxCxHxW
cam = cam[:, None, :, :]
cam = torch.from_numpy(cam)
cam = transform.deaugment_mask(cam)
# Back to numpy float32, HxW
cam = cam.numpy()
cam = cam[:, 0, :, :]
cams.append(cam)
cam = np.mean(np.float32(cams), axis=0)
return cam
def __call__(self,
input_tensor,
target_category=None,
aug_smooth=False,
eigen_smooth=False):
# Smooth the CAM result with test time augmentation
if aug_smooth is True:
return self.forward_augmentation_smoothing(
input_tensor, target_category, eigen_smooth)
return self.forward(input_tensor,
target_category, eigen_smooth)
def __del__(self):
self.activations_and_grads.release()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_value, exc_tb):
self.activations_and_grads.release()
if isinstance(exc_value, IndexError):
# Handle IndexError here...
print(
f"An exception occurred in CAM with block: exc_type. Message: exc_value")
return True
这是CAM的部分。
class CompactBilinearPooling(nn.Module):
"""
Compute compact bilinear pooling over two bottom inputs.
Args:
output_dim: output dimension for compact bilinear pooling.
sum_pool: (Optional) If True, sum the output along height and width
dimensions and return output shape [batch_size, output_dim].
Otherwise return [batch_size, height, width, output_dim].
Default: True.
rand_h_1: (Optional) an 1D numpy array containing indices in interval
`[0, output_dim)`. Automatically generated from `seed_h_1`
if is None.
rand_s_1: (Optional) an 1D numpy array of 1 and -1, having the same shape
as `rand_h_1`. Automatically generated from `seed_s_1` if is
None.
rand_h_2: (Optional) an 1D numpy array containing indices in interval
`[0, output_dim)`. Automatically generated from `seed_h_2`
if is None.
rand_s_2: (Optional) an 1D numpy array of 1 and -1, having the same shape
as `rand_h_2`. Automatically generated from `seed_s_2` if is
None.
"""
def __init__(self, input_dim1, input_dim2, output_dim,
sum_pool=True, cuda=True,
rand_h_1=None, rand_s_1=None, rand_h_2=None, rand_s_2=None):
super(CompactBilinearPooling, self).__init__()
self.input_dim1 = input_dim1
self.input_dim2 = input_dim2
self.output_dim = output_dim
self.sum_pool = sum_pool
if rand_h_1 is None:
np.random.seed(1)
rand_h_1 = np.random.randint(output_dim, size=self.input_dim1)
if rand_s_1 is None:
np.random.seed(3)
rand_s_1 = 2 * np.random.randint(2, size=self.input_dim1) - 1
self.sparse_sketch_matrix1 = Variable(self.generate_sketch_matrix(
rand_h_1, rand_s_1, self.output_dim))
if rand_h_2 is None:
np.random.seed(5)
rand_h_2 = np.random.randint(output_dim, size=self.input_dim2)
if rand_s_2 is None:
np.random.seed(7)
rand_s_2 = 2 * np.random.randint(2, size=self.input_dim2) - 1
self.sparse_sketch_matrix2 = Variable(self.generate_sketch_matrix(
rand_h_2, rand_s_2, self.output_dim))
if cuda:
self.sparse_sketch_matrix1 = self.sparse_sketch_matrix1.cuda()
self.sparse_sketch_matrix2 = self.sparse_sketch_matrix2.cuda()
def forward(self, bottom1, bottom2):
"""
bottom1: 1st input, 4D Tensor of shape [batch_size, input_dim1, height, width].
bottom2: 2nd input, 4D Tensor of shape [batch_size, input_dim2, height, width].
"""
assert bottom1.size(1) == self.input_dim1 and \\
bottom2.size(1) == self.input_dim2
batch_size, _, height, width = bottom1.size()
bottom1_flat = bottom1.permute(0, 2, 3, 1).contiguous().view(-1, self.input_dim1)
bottom2_flat = bottom2.permute(0, 2, 3, 1).contiguous().view(-1, self.input_dim2)
sketch_1 = bottom1_flat.mm(self.sparse_sketch_matrix1)
sketch_2 = bottom2_flat.mm(self.sparse_sketch_matrix2)
fft1 = afft.fft(sketch_1)
fft2 = afft.fft(sketch_2)
fft_product = fft1 * fft2
cbp_flat = afft.ifft(fft_product).real
cbp = cbp_flat.view(batch_size, height, width, self.output_dim)
if self.sum_pool:
cbp = cbp.sum(dim=1).sum(dim=1)
return cbp
@staticmethod
def generate_sketch_matrix(rand_h, rand_s, output_dim):
"""
Return a sparse matrix used for tensor sketch operation in compact bilinear
pooling
Args:
rand_h: an 1D numpy array containing indices in interval `[0, output_dim)`.
rand_s: an 1D numpy array of 1 and -1, having the same shape as `rand_h`.
output_dim: the output dimensions of compact bilinear pooling.
Returns:
a sparse matrix of shape [input_dim, output_dim] for tensor sketch.
"""
# Generate a sparse matrix for tensor count sketch
rand_h = rand_h.astype(np.int64)
rand_s = rand_s.astype(np.float32)
assert(rand_h.ndim == 1 and rand_s.ndim ==
1 and len(rand_h) == len(rand_s))
assert(np.all(rand_h >= 0) and np.all(rand_h < output_dim))
input_dim = len(rand_h)
indices = np.concatenate((np.arange(input_dim)[..., np.newaxis],
rand_h[..., np.newaxis]), axis=1)
indices = torch.from_numpy(indices)
rand_s = torch.from_numpy(rand_s)
sparse_sketch_matrix = torch.sparse.FloatTensor(
indices.t(), rand_s, torch.Size([input_dim, output_dim]))
return sparse_sketch_matrix.to_dense()这是作者论文里的线性模式。
写在最后
作者是几位华人学生,在阿德莱德大学和澳大利亚大学
这份码起码有20多个大Bug,包括有好几处的变量未定义就使用的,网络的输入输出对不上等等,并且连数据读取、数据下载部分都有问题........
cv君的Debug能力还算比较好的,在我花了一个晚上改了20多个bug后,亲妈都快不认识这份顶会的代码了,终于能跑了。
个人建议,大家不要碰这份代码,看看他的论文思路就行,他的Block可以拿出来看看,不要碰他的代码,不然你将拥有一份和cv君一样的高强的Debug能力。
本来昨天就写完文章了,就因为去看他的代码,导致晚了一天。。
本文的名字是:《最新开源 随插即用》SAM 自增强注意力深度解读与实践(附代码及分析)
看完代码,我想改名字:《论新出的顶会论文代码写得有多差》
最后,附上论文原文https://arxiv.org/pdf/2208.00617.pdf和代码链接:GitHub - GANPerf/SAM
如果大家对SAM,或者其他注意力机制感兴趣,可以和cv君联系,cv君比较熟悉注意力机制。

以上是关于《最新开源 随插即用》SAM 自增强注意力深度解读与实践(附代码及分析)的主要内容,如果未能解决你的问题,请参考以下文章