五种IO模型与多路转接
Posted 楠c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五种IO模型与多路转接相关的知识,希望对你有一定的参考价值。
IO=等待+数据拷贝,读IO=等读事件就绪+内核数据拷贝至用户空间。写IO=写事件就绪,用户空间拷贝至内核空间。
那么怎么将IO变的高效呢?本质就是尽可能的减少等的比重。
五种IO模型
举一个钓鱼的例子,钓鱼=等待+将鱼钓上去
- 张三:一直死盯着鱼竿,有鱼上钩然后然后钓上来。
- 李四:李四一会看一下鱼竿,发现没有异动,在这个间隔的期间他可以看书。当再次看的时候有鱼上钩就会吊起。
- 王五:买了一个铃铛挂在杆上,他看都不看鱼竿一眼,没鱼上钩的时候,一直在看书,有鱼上钩的时候,铃铛响的时候再去钓上来。
- 赵六:我有100个鱼竿,然后在岸边来回踱步。假设他可以忙过来,有鱼上钩再去对应的那个杆,把鱼吊起来。他本质是概率增加了。
- 田七:田七给了司机小刘所有的钓鱼设备并告诉小刘,你想怎么钓就怎么钓,反正钓到了给我打电话。当小刘在钓鱼的时候,田七甚至不再现场,他想干啥就干啥。
前四种,自己等自己钓,它叫做同步IO。后一种叫异步IO

多路转接:select,poll,epoll。他就是单独设计了一套系统调用,专门让他们负责等待多个文件描述符。

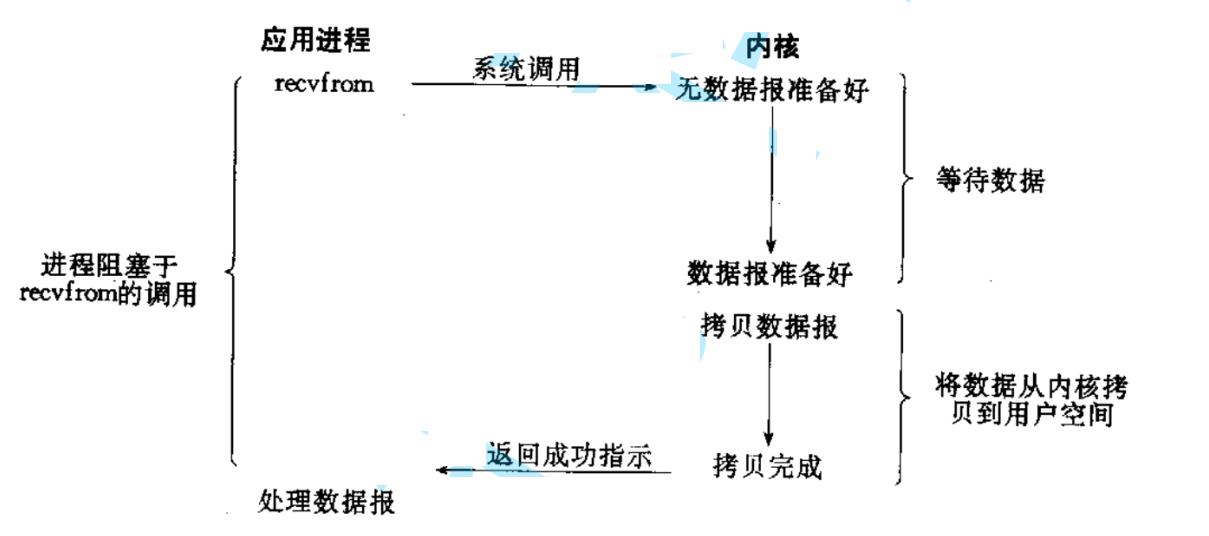
阻塞IO
阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式
非阻塞IO
非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULDBLOCK错误码.
非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符, 这个过程称为轮询. 这对CPU来说是较大的浪费, 一般只有特定场景下才使用

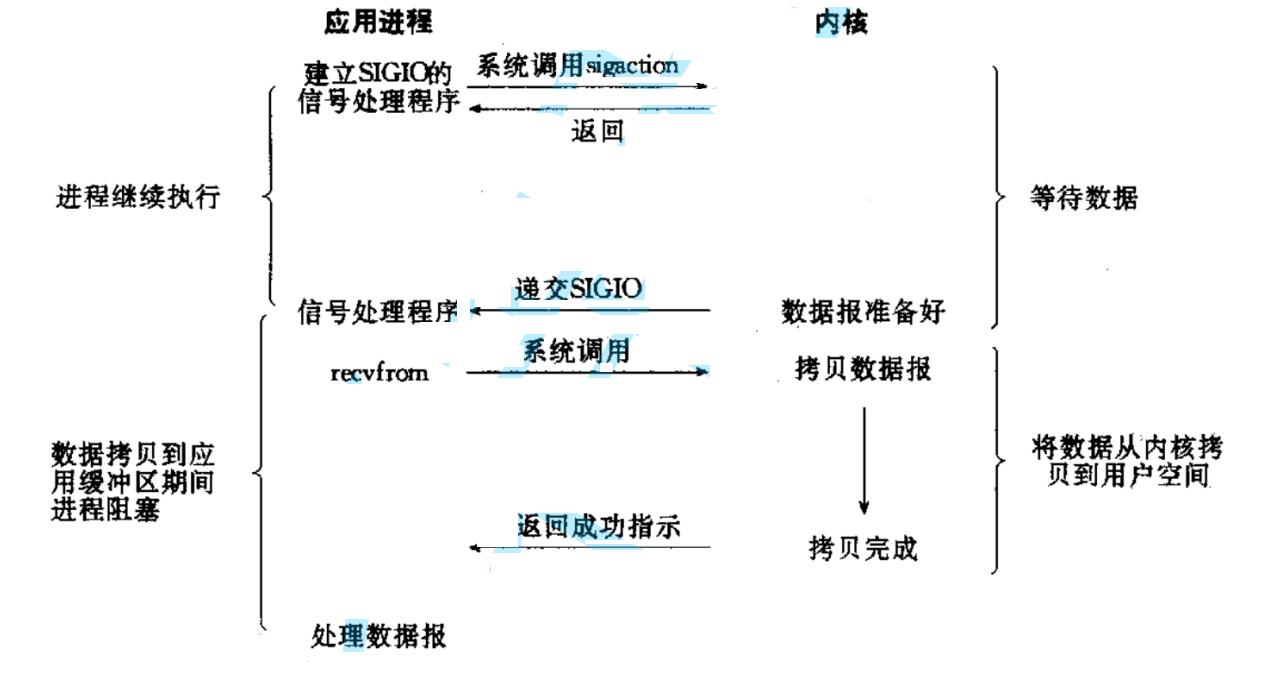
信号驱动IO
内核将数据准备好的时候, 使用SIGIO信号通知应用程序进行IO操作
多路转接
虽然从流程图上看起来和阻塞IO类似.但他可以同时等待多个文件描述符的就绪状态.

异步IO
异步IO: 由内核在数据拷贝完成时, 通知应用程序
与信号驱动IO不同的是,异步IO中用户不需要做拷贝动作。

Fcntl
将文件描述符设置为非阻塞
获得/设置文件状态标记(cmd=F_GETFL或F_SETFL)
void SetNoBlock(int fd)
int fl = fcntl(fd, F_GETFL);
if (fl < 0)
perror("fcntl");
return;
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
多路转接
核心就是将等待的过程抽离出来,而且一次等待多个文件描述符。它是一种就绪事件通知方案。
select
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout)
- 参数nfds是需要监视的最大的文件描述符值+1;(文件描述符是下标么)
- rdset,wrset,exset分别对应于需要检测的可读文件描述符的集合,可写文件- 描述符的集 合及异常文件描述符的集合;
- 参数timeout为结构timeval,用来设置select()的等待时间
参数timeout取值:
- NULL:则表示select()没有timeout, select将一直被阻塞,直到某个文件描述符上发生了事件;
- 0:仅检测描述符集合的状态,然后立即返回,并不等待外部事件的发生。
- 特定的时间值:如果在指定的时间段里没有事件发生, select将超时返回
fd_set,wrset,exset既做输入又做输出参数,输入时用户告诉操作系统,输出操作系统告诉用户
他们是一个个位图结构,位置代表哪一个文件描述符,内容代表是否存在。
输入,代表需要关心的文件描述符
输出,代表对应文件描述符是否就绪
所以每次在使用select就需要重新设置,各个输入参数,来表明本轮想要关心的新的文件描述符。同样的time_wait也要重新设置。
select缺点
- 每次调用select, 都需要手动设置fd集合, 从接口使用角度来说也非常不便.
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
- 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
- select支持的文件描述符有上限,数量太小。(因为他是一个位图结构)
Poll
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// pollfd结构
struct pollfd
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
- fds是一个poll函数监听的结构列表. 每一个元素中, 包含了三部分内容: 文件- - 描述符, 监听的事件集合, 返回的事件集合.
- nfds表示fds数组的长度.
- timeout表示poll函数的超时时间, 单位是毫秒(ms)
poll的特征
select将输入输出用一个变量表示,所以每次都要重新添加,而且他的最大数量有限制。所以poll对这两方面做出了改变。
poll的优点
- poll并没有最大数量限制 (但是数量过大后性能也是会下降).
- pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式. 接口使用比select更方便
而且不同与select使用三个位图来表示三个fdset的方式, poll使用一个pollfd的指针实现.
因为是一个结构体数组,所以他可以定义任意大。但是内存是有上限的,但这和poll没关系,是你的操作系统不行。
poll的缺点
和select函数一样, poll返回后,需要轮询pollfd来获取就绪的描述符.
每次调用poll都需要把大量的pollfd结构从用户态拷贝到内核中.
同时连接的大量客户端在一时刻可能只有很少的处于就绪状态, 因此随着监视的描述符数量的增长, 其效率也会线性下降
epoll
man手册中提出epoll是为了处理大量句柄而生,改进了poll。
虽然poll也能处理大量句柄,但是效率难免降低
多路转接更适合处理长连接的情况。
集齐了所有优点,几乎摒弃了所有缺点。
select,poll只提供了一个系统调用,epoll提供了系统调用有3个。操作系统帮我们做的事情更多了。
int epoll_create(int size);
自从linux2.6.8之后, size参数是被忽略的.
返回一个文件描述符,用完之后, 必须调用close()关闭
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
它不同于select()是在监听事件时告诉内核要监听什么类型的事件, 而是在这里先注册要监听的事件类型.
第一个参数是epoll_create()的返回值(epoll的句柄).
第二个参数表示动作,用三个宏来表示.
第三个参数是需要监听的fd.
第四个参数是告诉内核需要监听什么事
- 第二个参数的取值:
EPOLL_CTL_ADD :注册新的fd到epfd中;
EPOLL_CTL_MOD :修改已经注册的fd的监听事件;
EPOLL_CTL_DEL :从epfd中删除一个fd
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
- 参数events是分配好的epoll_event结构体数组.
epoll将会把发生的事件赋值到events数组中 (events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存). - maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size.
- 参数timeout是超时时间 (毫秒, 0会立即返回, -1是永久阻塞).
如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时, 返回小于0表示函数失败。
在poll中一个接口实现用户高速内核,内核告诉用户,但是通常内核告诉用户是更高频的。epoll将两个接口分离出来。
epoll的工作原理

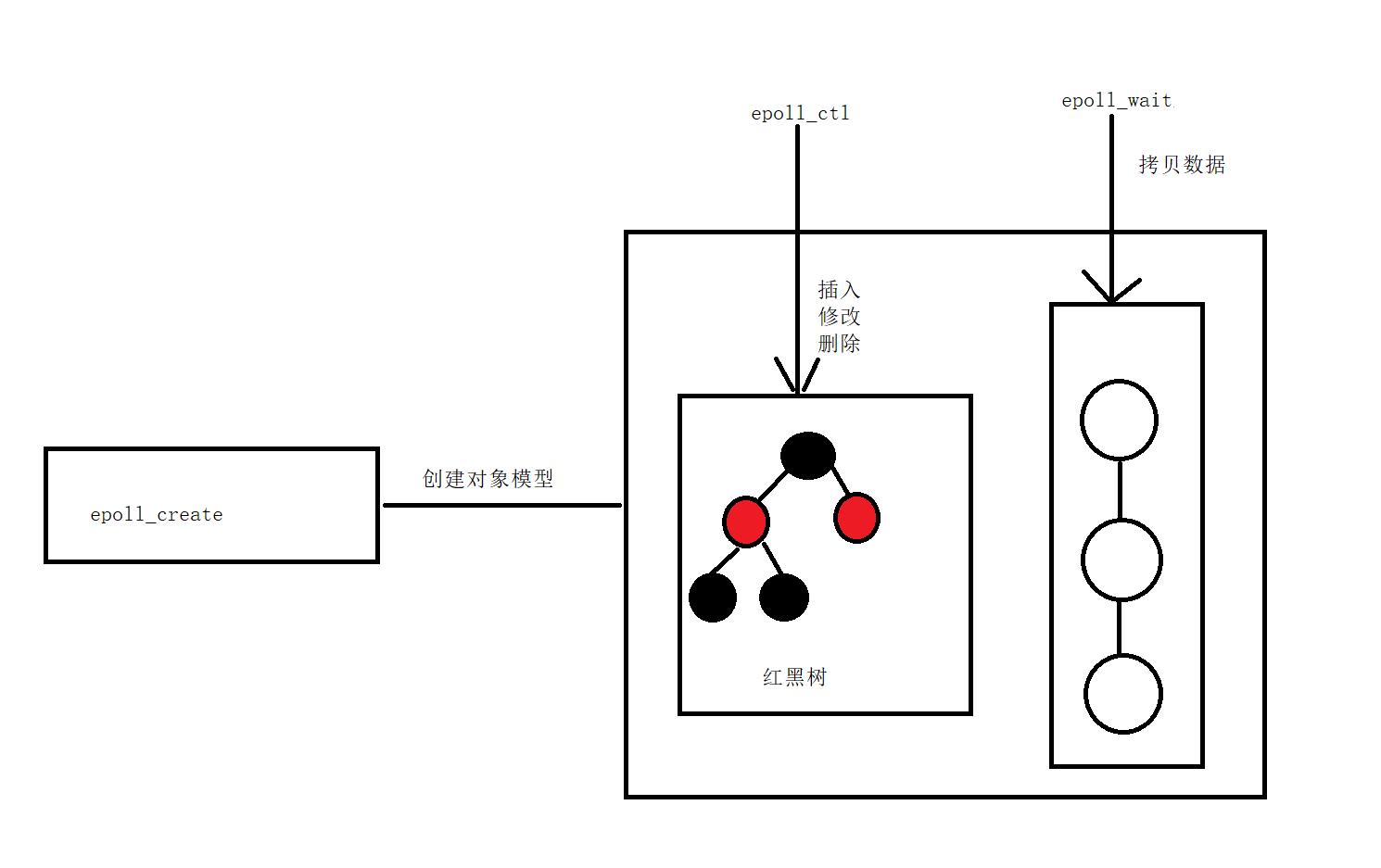
即使海量的数据过来,但我们始终是从队列中拿取数据,数据增多他是不会引起效率降低的。
epoll的工作方式
水平触发Level Triggered
epoll默认状态下就是LT工作模式.
当epoll检测到socket上事件就绪的时候, 可以不立刻进行处理. 或者只处理一部分.
如上面的例子, 由于只读了1K数据, 缓冲区中还剩1K数据, 在第二次调用 epoll_wait 时, epoll_wait仍然会立刻返回并通知socket读事件就绪.
直到缓冲区上所有的数据都被处理完, epoll_wait 才不会立刻返回.
支持阻塞读写和非阻塞读写
边缘触发Edge Triggered
如果我们在第1步将socket添加到epoll描述符的时候使用了EPOLLET标志, epoll进入ET工作模式.
当epoll检测到socket上事件就绪时, 必须立刻处理.
如上面的例子, 虽然只读了1K的数据, 缓冲区还剩1K的数据, 在第二次调用 epoll_wait 的时候,epoll_wait 不会再返回了.
也就是说, ET模式下, 文件描述符上的事件就绪后, 只有一次处理机会.
ET的性能比LT性能更高( epoll_wait 返回的次数少了很多). nginx默认采用ET模式使用epoll.只支持非阻塞的读写。
为什么不能阻塞,由于et模式只会通知一次,所以对于我们的程序会采取类似的循环读取,以免丢失数据,假如此时文件描述符阻塞那么没有数据读取时进程就会阻塞在读取函数那里无法继续下去。所以以非阻塞读取,当没有数据接口会返回一个错误,然后退出。
总结
select和poll其实也是工作在LT模式下. epoll既可以支持LT, 也可以支持ET。
LT更安全,ET效率比较高。
最基础的TCP的Socket编程,它是阻塞I/O模型,基本上只能一对一通信,那为了服务更多的客户端,我们需要改进网络I/O模型。
比较传统的方式是使用多进程/线程模型,每来一个客户端连接,就分配一个进程/线程,然后后续的读写都在对应的进程/线程,这种方式处理100个客户端没问题,但是当客户端增大到10000个时,10000个进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
IO的核心就是等+数据拷贝,多路转接就是把等的事件抽离出来,然后专门用系统调用处理。select,poll,epoll。
- select,它将我们想要关注的文件描述符集合放入三个参数中,拷贝到内核态。内核遍历位图检测是否有时间发生,然后标记拷贝进用户态。用户在遍历找到对应文件描述符,进行处理。
这个过程中两次拷贝,两次遍历。
select有3个缺点。
三个参数读位图,写位图,异常位图,他既做输入又做输出,而且每次用完都要重新设置。
由于内核限制,只能标记1024个文件描述符,所以他能监听的数量是有限的。 - poll,用一个参数表示要监听的事件。而且不同于位图的结构,他用一个变长数组用链表串起来,所以可以定义任意大小。突破文件描述符的限制,和参数用起来方便两个问题,他还有一个问题没有解决,那就是效率,他们两个都是线性结构,遍历为On,需要在用户态和内核态之间拷贝。
- epoll,使用三个系统调用来帮我们完成,系统调用做的事多了,我们做的事就少了,create创建红黑树,网卡建立对应事件的回调函数。ctl控制插入,修改,删除,事件信息。实际就是一个fd,event的kv结构。每次只需要控制单个节点。wait直接从就绪队列中拷贝数据。当有事件发生触发回调函数,那么就会放入队列之中,大量的数据也不会影响,因为我们始终是存队列中取数据。
- LT与ET。select与poll是LT。epoll可以LT,也可以ET。ET需要注意设置非阻塞。一般用循环读,假如阻塞就会一直再循环里,等待。
以上是关于五种IO模型与多路转接的主要内容,如果未能解决你的问题,请参考以下文章