Python学习第八篇:requests 库学习
Posted Goodric
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习第八篇:requests 库学习相关的知识,希望对你有一定的参考价值。
Python学习第八篇:requests 库学习
活动地址:CSDN21天学习挑战赛
——
这里主要学习requests这个http模块,该模块主要用于发送请求获取响应
urlib 模块也可以实现request模块s能实现的功能,但是用的最多的还是requests 模块, requests的代码简洁 易懂,相对于臃肿的urlib模块,使用requests编写的代码将会更少, 而且实现某-功能将会简单。
下载
pip install requests
或
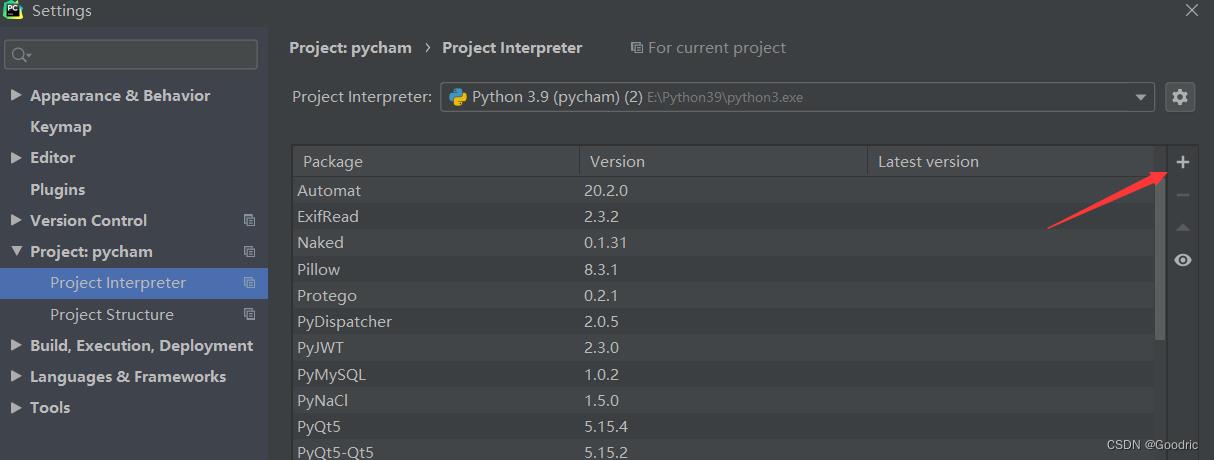
pycharm 中 setting 里进行下载,也是我常用的方式。
——
常用的属性和方法
response = requests.get(url): 发送请求获取的响应对象(最常用)
response = requests.post(url): 发送请求获取的响应对象
response.url: 响应的url;有时候响应的ur1和请求的urI并不一致
response.status_ code: 响应状态码,如:200,404
response.request.headers: 响应对应的请求头
response. headers: 响应头
response.request.cookies: 响应对应请求的cookie; 返回cookieJar类型
response.cookies: 响应的cookie (经过了set- cookie动作; 返回cookieJar类型)
response.json(): 自动将json字符串类型的响应内容转换为python对象 (dict or list)
response.text: 返回响应的内容,str类型
response.content: 返回响应的内容, bytes类型
——
response.text 和 response.content
都可以返回响应的内容。
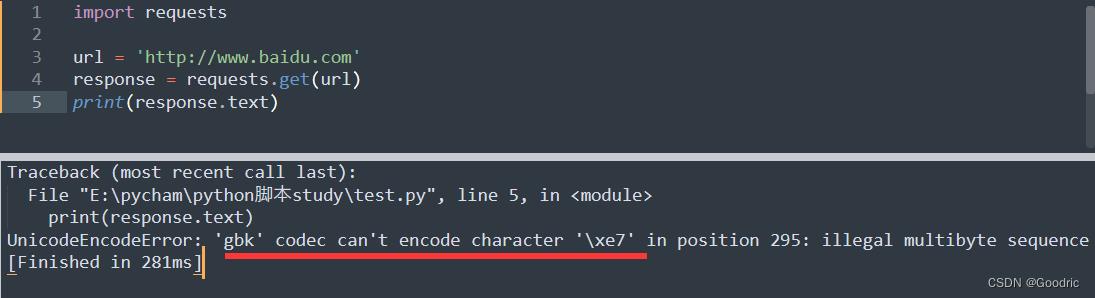
我这里我直接打印 response.text 的时候,出现报错,应该是关于 gbk 的一些编码问题。不知道为什么我这里会这样。
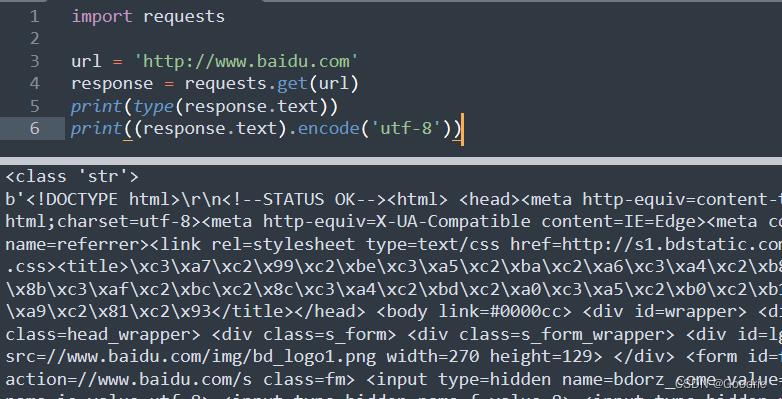
所以我这里打印 response.text 要进行编码一下。
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(type(response.text))
print((response.text).encode('utf-8'))
看到类型为 str
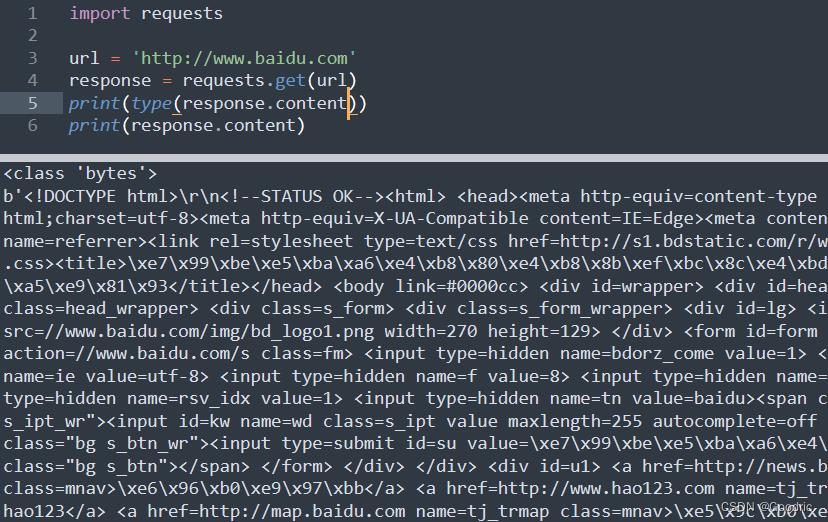
再看 response.content 的类型为 bytes 。但内容和 response.text 返回的是一样的。
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(type(response.content))
print(response.content)
——
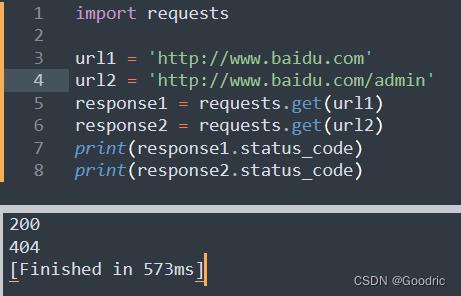
status_code
状态码可判断此网址能否正常访问。
import requests
url1 = 'http://www.baidu.com'
url2 = 'http://www.baidu.com/admin'
response1 = requests.get(url1)
response2 = requests.get(url2)
print(response1.status_code)
print(response2.status_code)
——
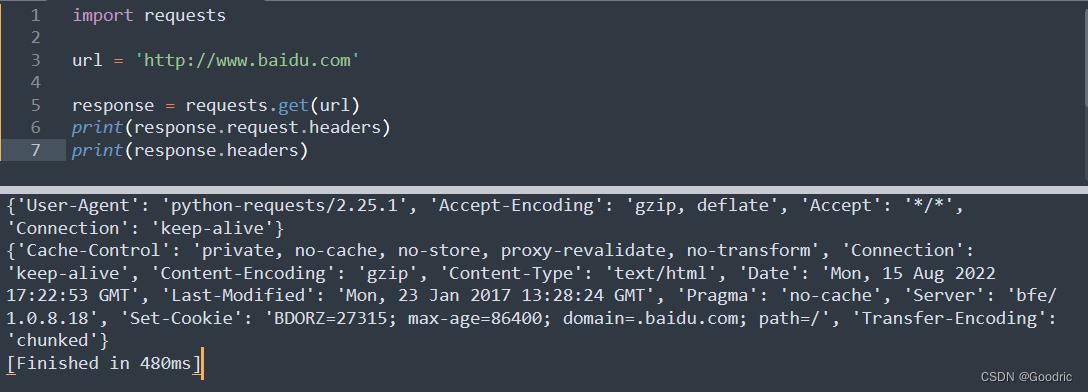
header 请求头信息
包含 user-agent、connection 等信息。
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(response.request.headers)
print(response.headers)
可以看到其中'User-Agent': 'python-requests/2.25.1' 代表的是浏览器信息,因为这里是用 python 访问的,所以 user-agent 是python 的一些信息。
并且有请求头和响应头。
response.request.headers是请求头 ,response.headers是响应头。
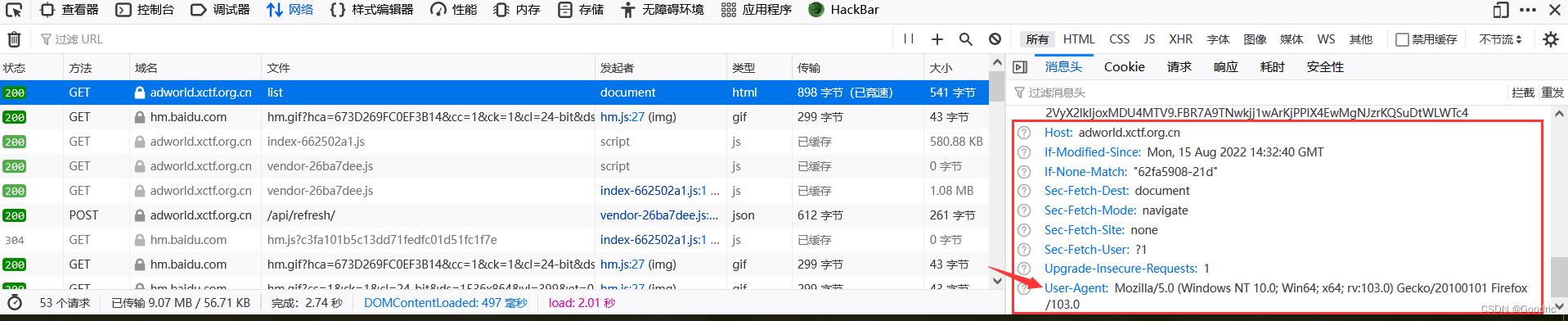
比如查看一下浏览器中真实的 header 参数值。F12 打开 “网络” 模块即可看到。
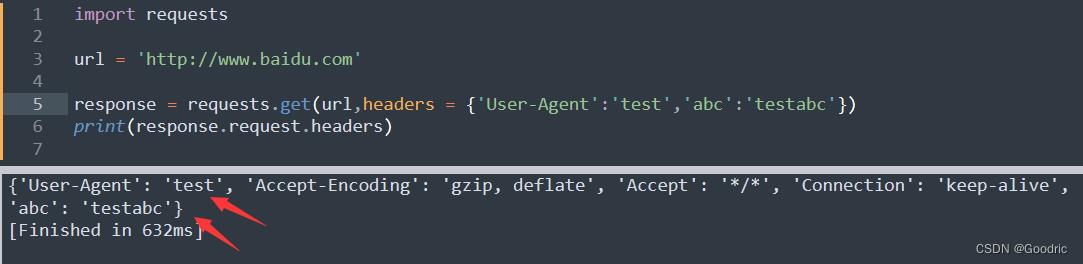
同时这些 header 参数也是可以伪造的。
import requests
url = 'http://www.baidu.com'
response = requests.get(url,headers = 'User-Agent':'test','abc':'testabc')
print(response.request.headers)
header 参数在 get() 请求中添加 headers 参数,需要构造的请求header 参数以字典的形式添加。
——
发送 get 参数
通过params构造参数字典
字典中的键值分别表示参数名和参数值。
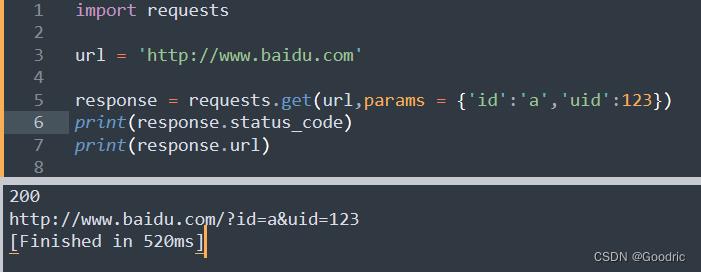
import requests
url = 'http://www.baidu.com'
response = requests.get(url,params = 'id':'a','uid':123)
print(response.status_code)
print(response.url)
get 参数的话其实方便一点可以直接在 url 上填写即可,如修改请求的 url 为:
url ='http://www.baidu.com/?id=a&uid=123'
——
发送post 请求参数
构造 post 请求就不像 get 请求一样可以在 url 上修改即可,在实际应用中 post 请求的数据我们是看不到的,不会显现出参数名信息给我们,像 get 请求的参数名信息就表现在 url 中。
比如在一个登录界面中的用户名和密码参数的传递一般是通过 post 请求。
通过 data 构造参数字典
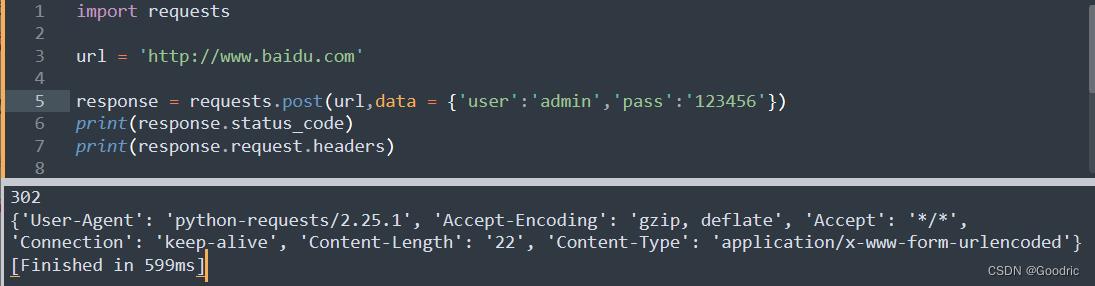
import requests
url = 'http://www.baidu.com'
response = requests.post(url,data = 'user':'admin','pass':'123456')
print(response.status_code)
print(response.request.headers)
在python 中也不太好展现出 post 的数据,但是header 中这个content-length 代表的就是 post 数据的长度:user=admin,pass=123456
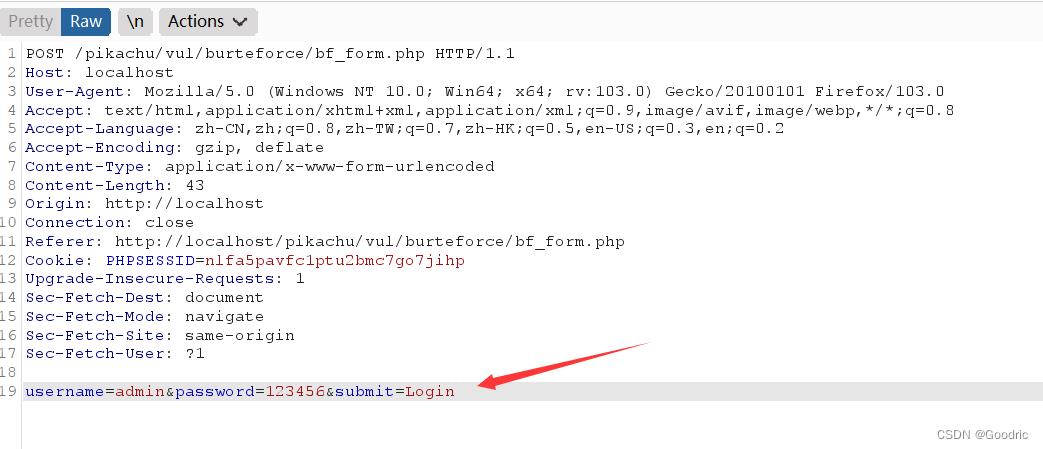
这里给出一个完整的请求包展示:
——
header 参数中携带 cookie
cookie 可用于模拟用户信息。服务器识别你为某个用户的信息之一。
和前面演示了的构造 user-agent 参数方法基本一致。
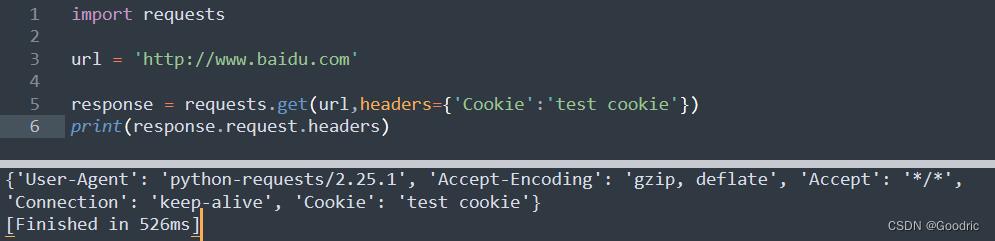
import requests
url = 'http://www.baidu.com'
response = requests.get(url,headers='Cookie':'test cookie')
print(response.request.headers)
——
proxies 代理参数使用
语法格式:
response = requests.get(url, proxies=proxies)
如
response = requests.get(url,proxies='http':'http://127.0.0.1:80')
如果proxies字典中包含有多个键值对,发送请求时将按照ur地址的协议来选择使用相应的代理ip
加上了proxies参数,具体不知道怎么用。。实际情况可能也用不上这个。
以上是关于Python学习第八篇:requests 库学习的主要内容,如果未能解决你的问题,请参考以下文章