初识ElasticSearch -文档查询之match查询 | 分词器
Posted 做猪呢,最重要的是开森啦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识ElasticSearch -文档查询之match查询 | 分词器相关的知识,希望对你有一定的参考价值。
1. 分词器:
2. match查询:
- 支持filed类型为text、number、date 、 boolean的查询;text类型查询还支持分词器(analyzer),默认使用内置standard 分词器
- 分词匹配查询共有三种模式,分别是布尔(boolean)、短语(phrase)和短语前缀(phrase_prefix),默认的匹配查询是布尔类型
- 查询过程:先对查询字符串进行分词,找出于索引库匹配的稳定
2.1. 数据准备 - 创建带分词器的索引映射
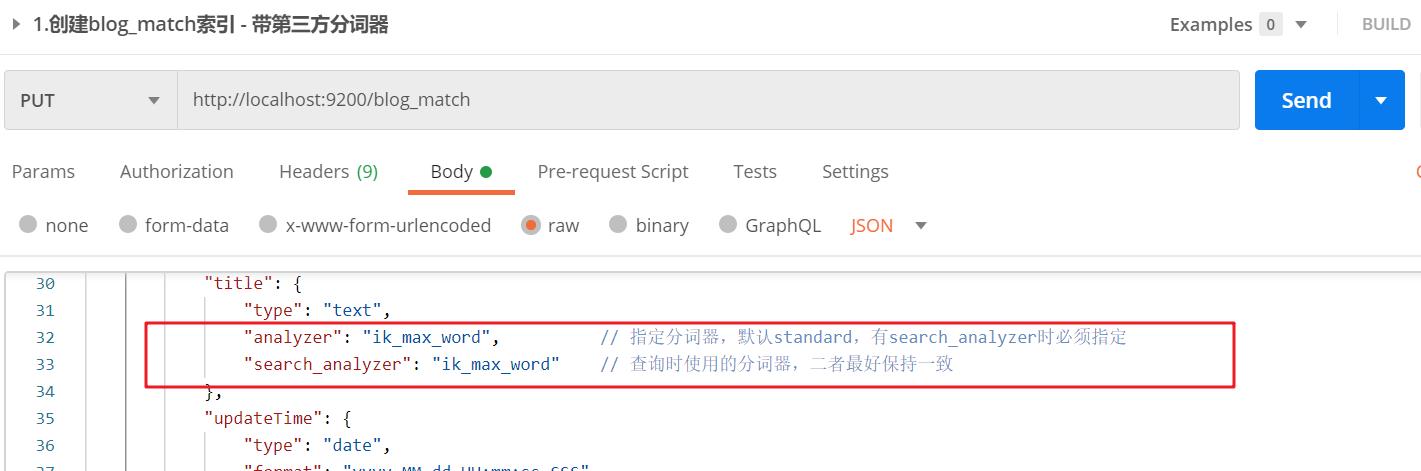
【栗子】:创建blog_match索引,指定title映射,并使用ik_max_word分词器
【HTTP请求】:
·
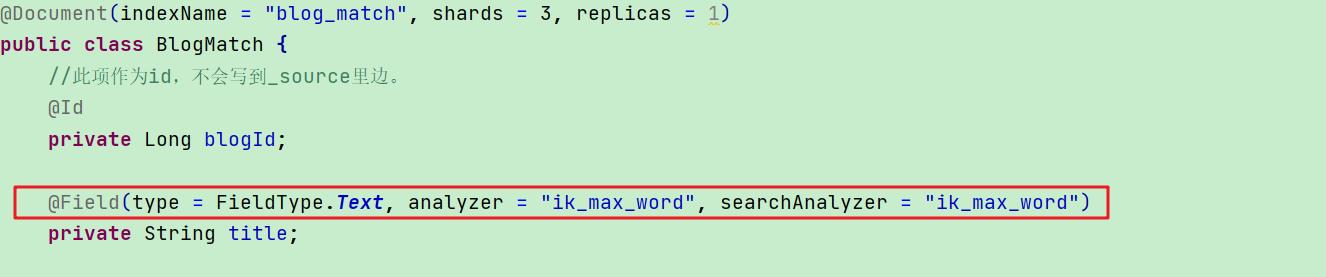
【API请求】:调用索引创建的API即可,只是注意在实体类添加注解参数
·
2.2. 数据准备 - 添加文档
新增一条"title":“ElasticSearch学习教程”;“content”:“星星之火可以燎原的文档数据”
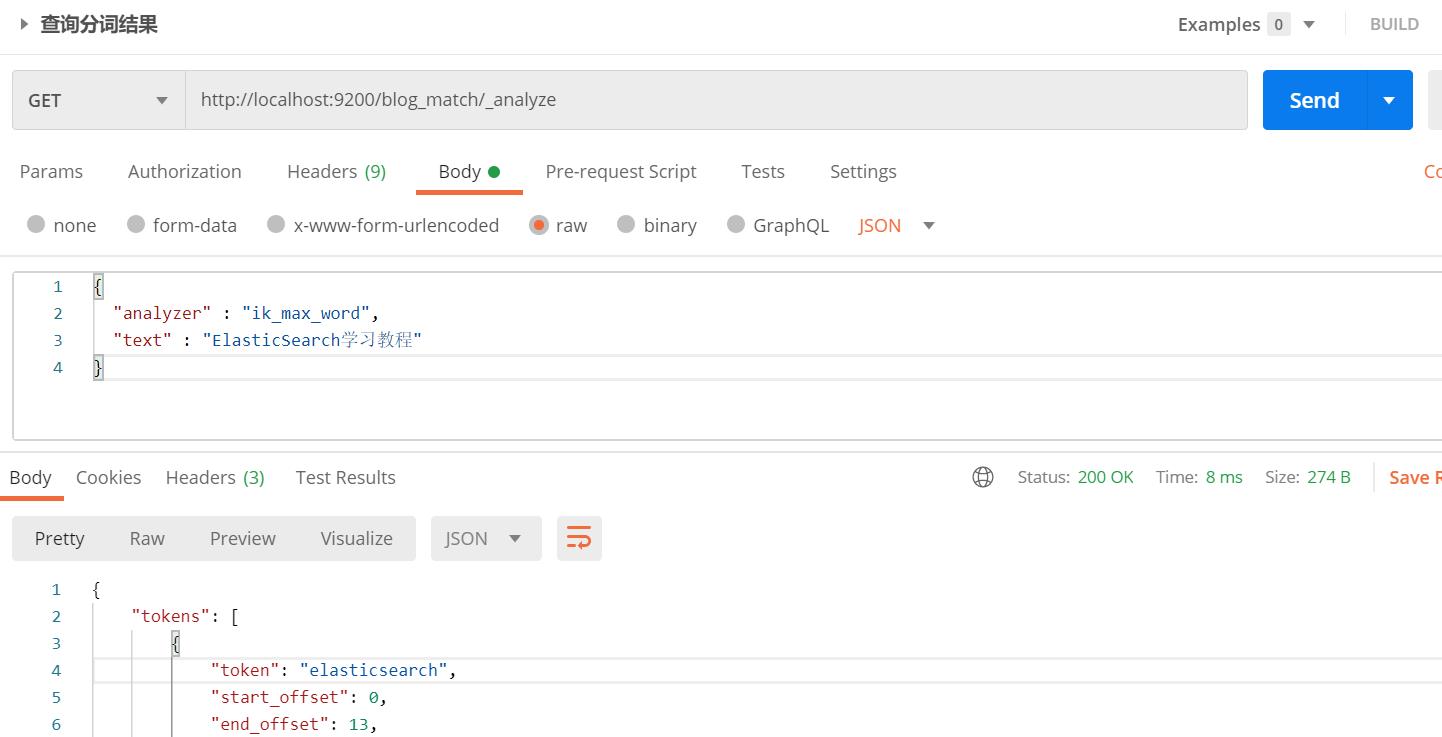
2.3. 数据准备 - 查看文本分词
对"ElasticSearch学习教程"文本进行ik分词器分析,可见分为elasticsearch、“学习”、"教程"三个分词
·
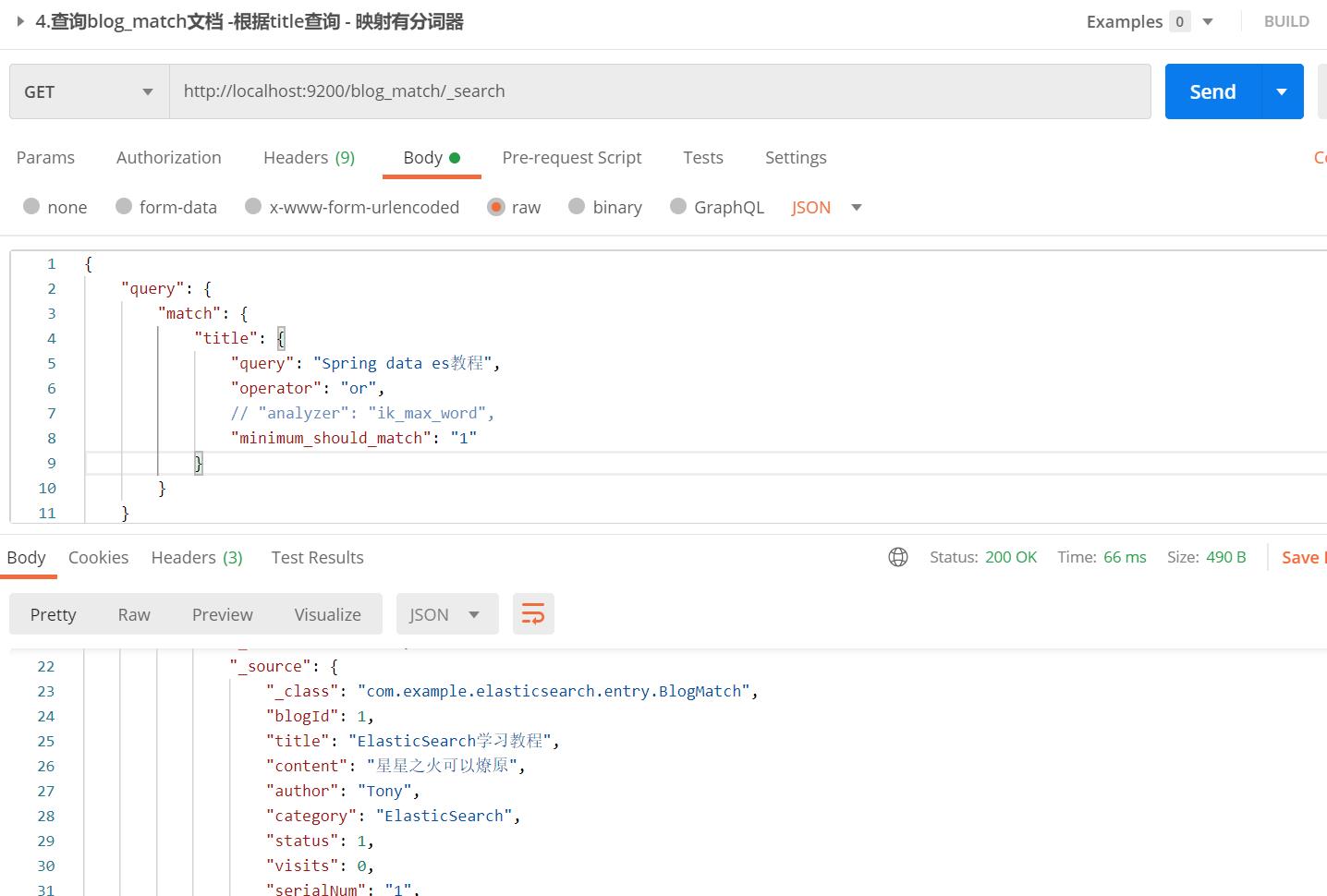
2.4. 查询 - 映射有分词器的字段查询
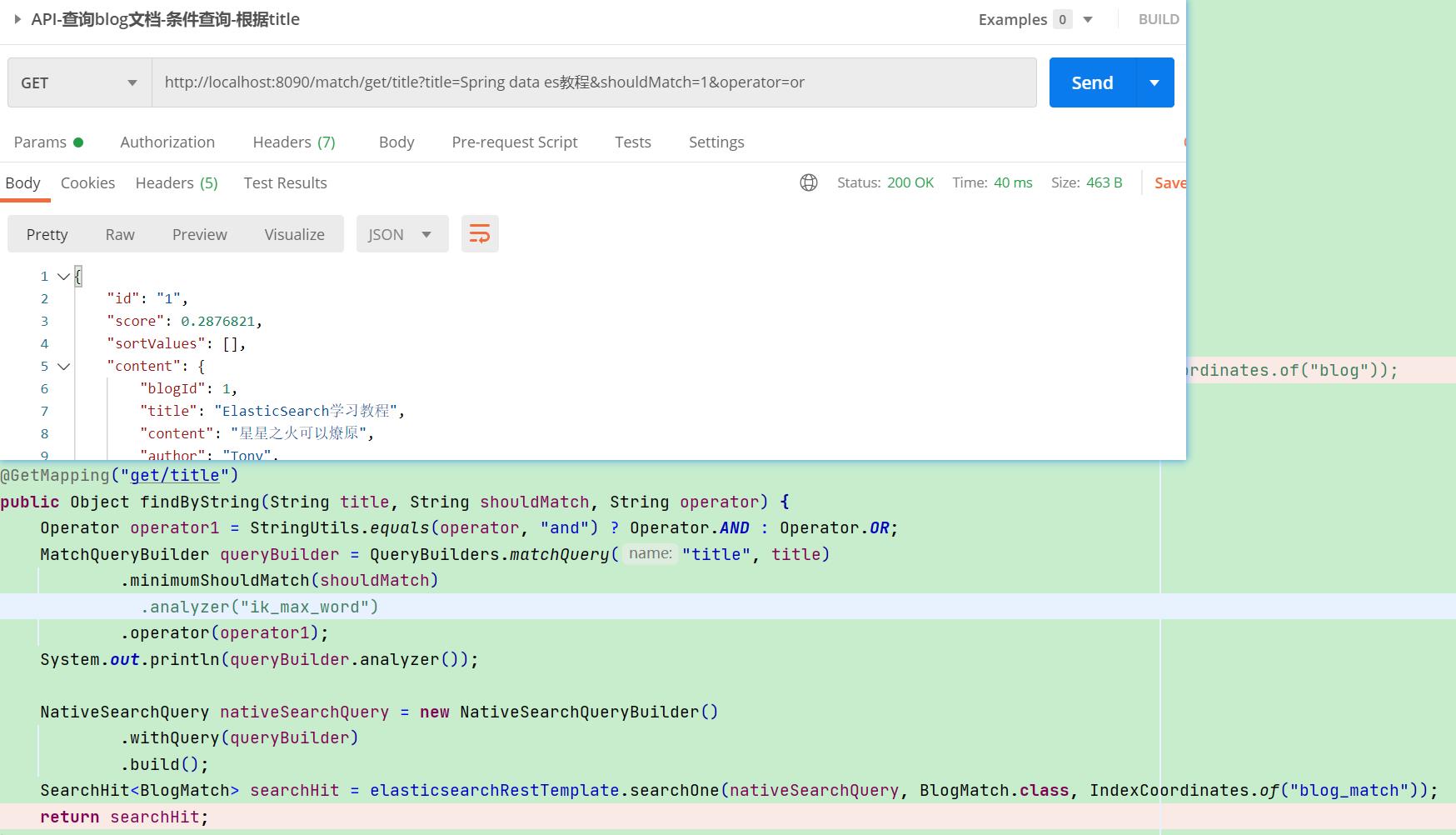
【栗子】上述title字段是配置了分词器映射的,这里使用title字段进行查询,查询内容为"Spring data es教程"
·
【参数说明】:
- query - 搜索的字符串
- operator - 操作符or或and,默认or,具体含义见【栗子分析】
- minimum_should_match - 最小匹配单元,整型为分词个数匹配、百分比则为百分比匹配,and操作符时不能使用改参数
·
【HTTP请求】:
·
【栗子分析】
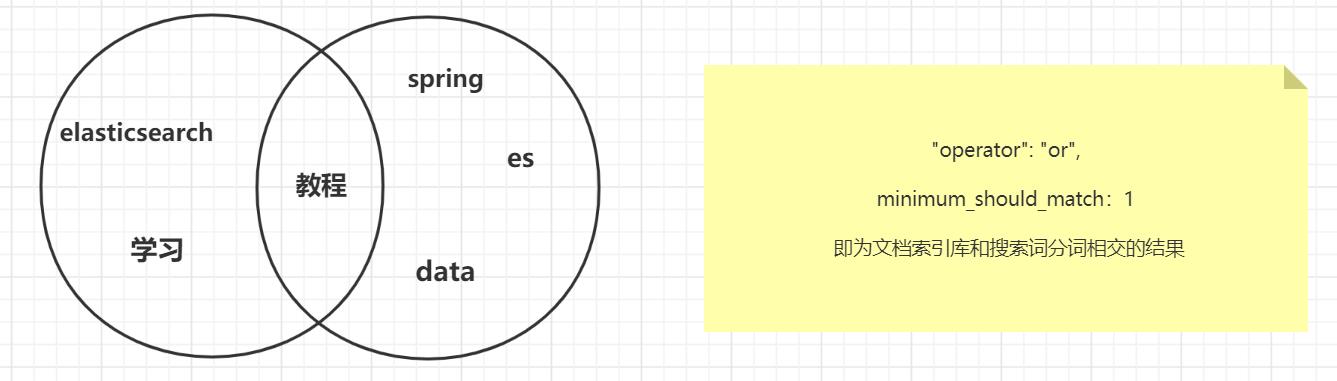
- 像2.3一样对"Spring data es教程"进行同样的分词分析,分为"spring"、“data”、“es”、"教程"4个分词
- “minimum_should_match”: “1” 意味着只要有一个分词匹配即可,“operator”:“or” 意味着上述4个分词,任意1个和索引库匹配
- 可见"教程"这个分词是匹配的,所以能查询到"ElasticSearch学习教程"的文档,如果"minimum_should_match": “2”,那么无法匹配成功
·- 如果"operator":“and”,意味着搜索词分词的搜索词分词要全部包含在文档索引库中
- 显然"Spring data es"教程是不匹配的,如果搜索"学习教程",即是匹配的
`·
【API请求】:MatchQueryBuilder构建Query
·
searchOne方法获取一个查询结果,如果有多个,取第一个;search方法可以返回多个结果

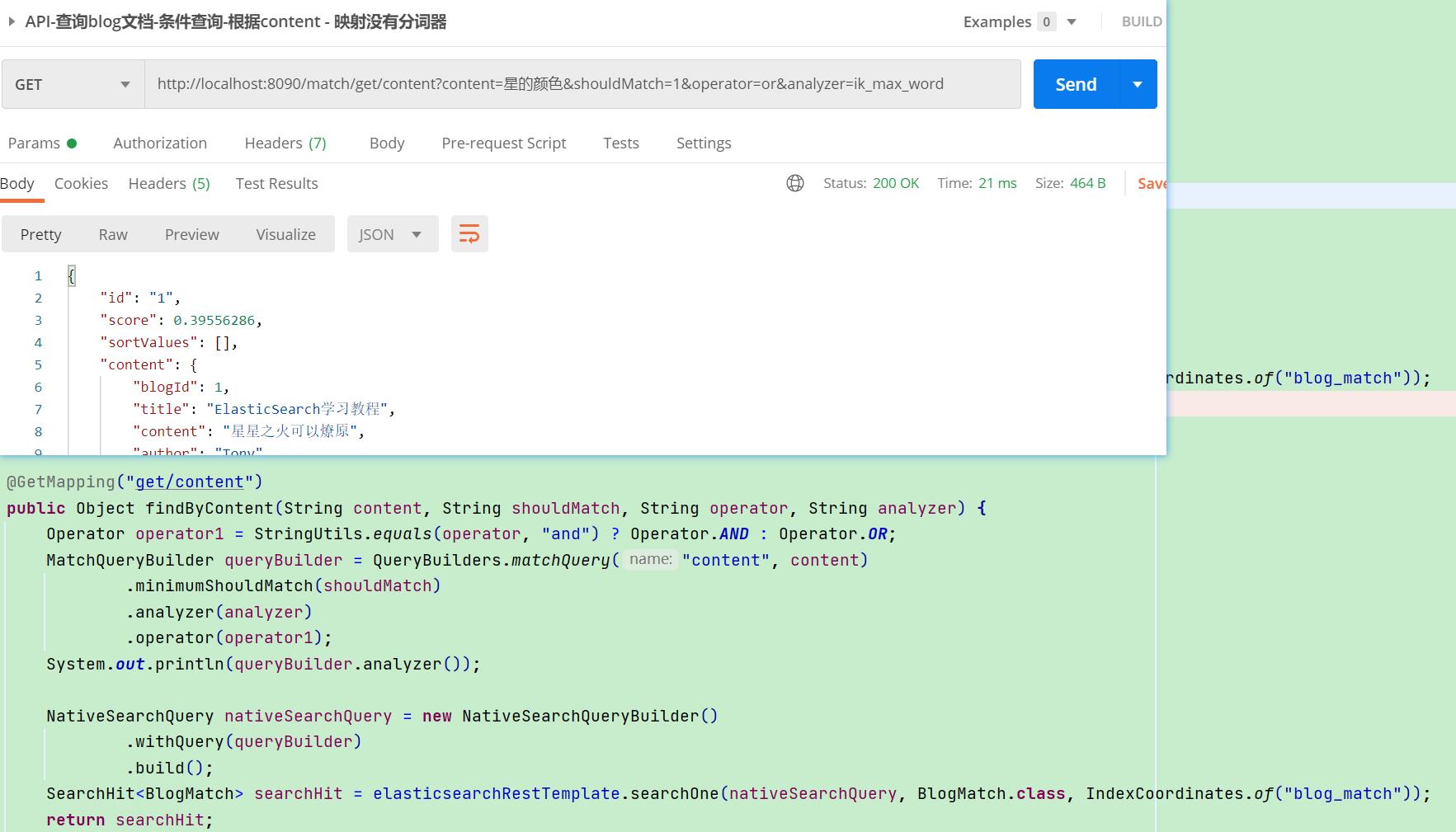
2.4. 查询 - 映射没有分词器的字段查询
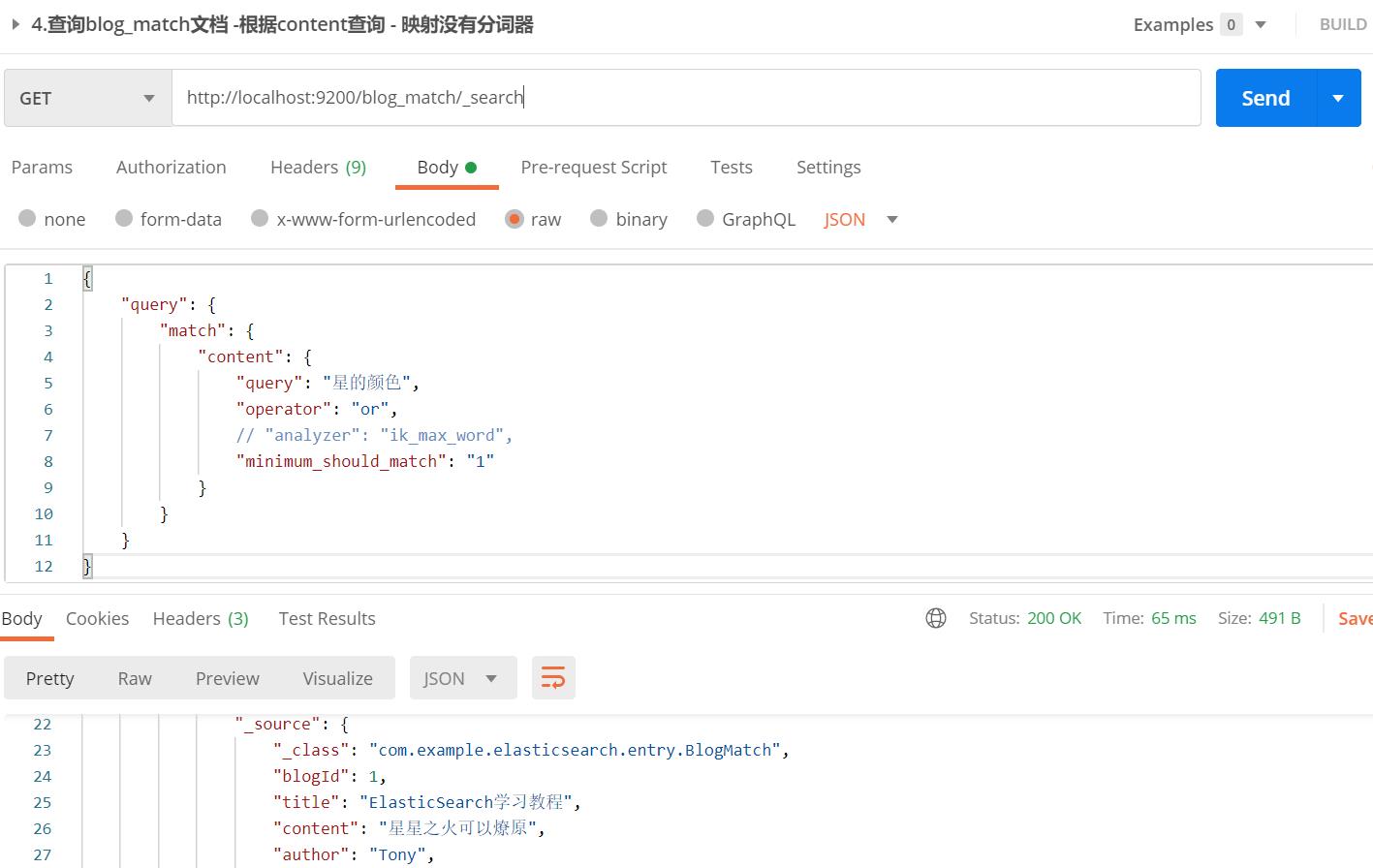
【栗子】上述content字段是没有配置分词器映射的,这里使用content字段进行查询,查询内容为"星的颜色"
·
【HTTP】:
·
【栗子分析】:
- content默认采用内置standard分词器,会将文本逐字分词,即"星星之火可以燎原",分为了8个分词
- 当搜素"星的颜色",根据standard,分为4个分词,or操作,minimum_should_match为1,所以符合分词"星"匹配
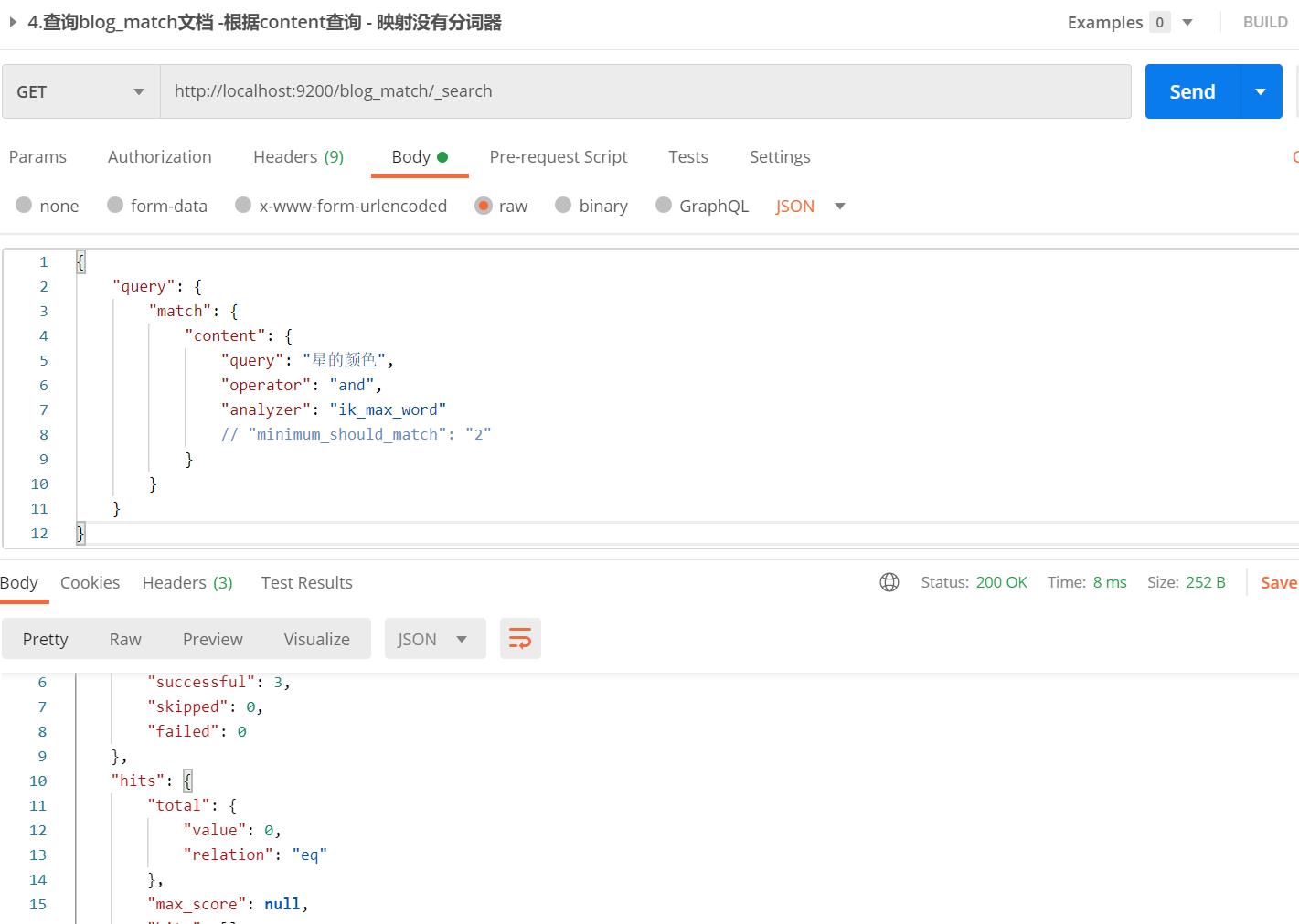
- 我们也可以显示指定analyzer分词器查询,根据ik分词,“星的颜色"分为"星”、“的”、"颜色"这3个分词
- 所以or仍然符合分词"星"匹配能搜索到文档,但and操作不符合匹配,所以搜索不到文档
·
【API请求】:MatchQueryBuilder构建Query指定analyzer分词器
·
3. match_phrase查询:
- 短语匹配:个人理解为临近分词匹配,查询过程和match类似,也支持指定analyzer分词器查询,此外还可以指定slop临近分词总数量
【数据准备】:文档"title":“Spring Data ElasticSearch小白学习教程”
·
【栗子】查询"Spring教程"
·
【栗子分析】:
- 文档"Spring Data ElasticSearch小白学习教程"由ik分词会分为"spring",“data”,“elasticsearch”,“小白”,“学习”,"教程"这6个分词
- 如果不指定slop(默认为0),那么是查询不到文档数据的,如果指定slop>=4,即可查询到文档数据,因为间隔了4个分词
·
【HTTP请求】:
·
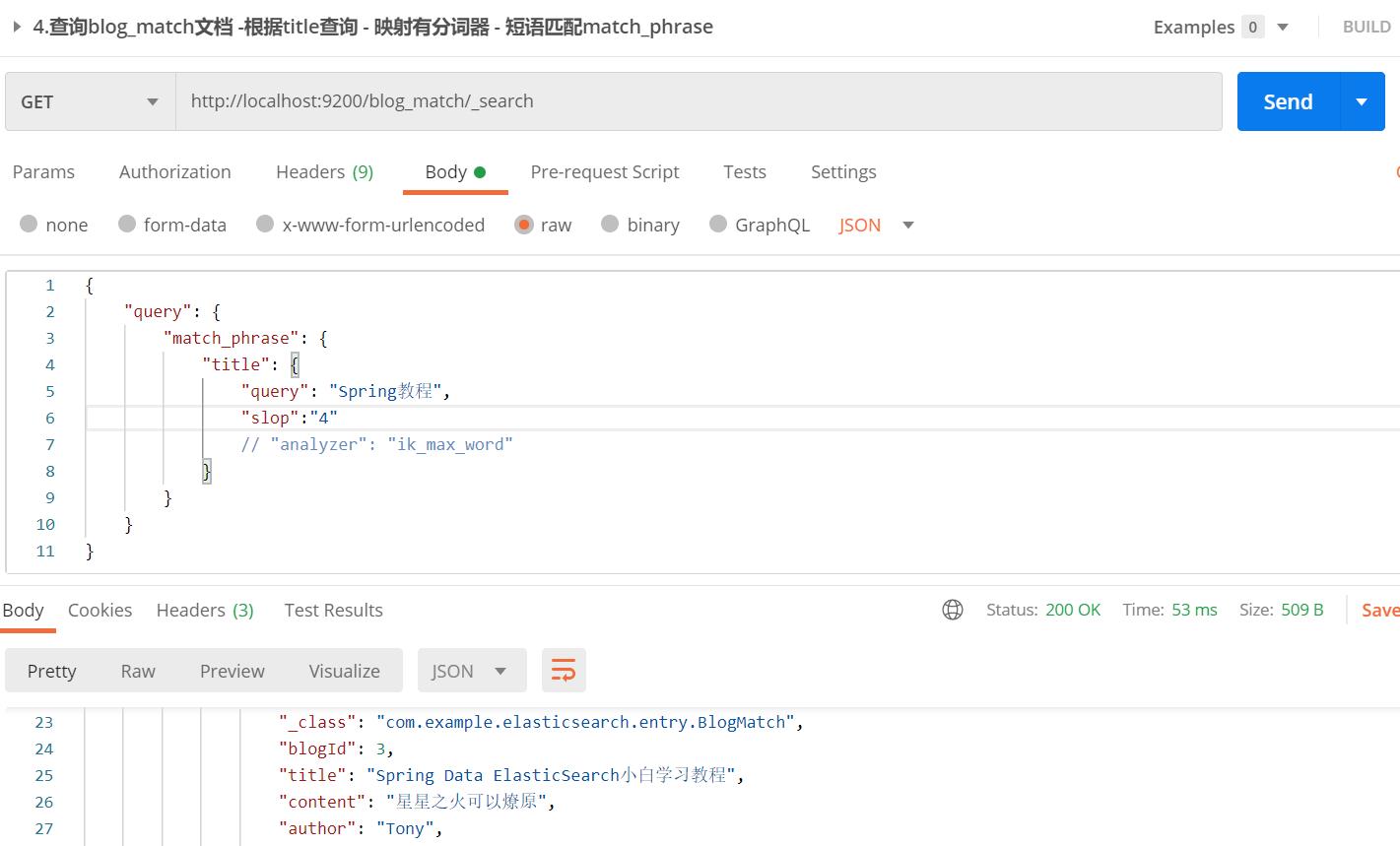
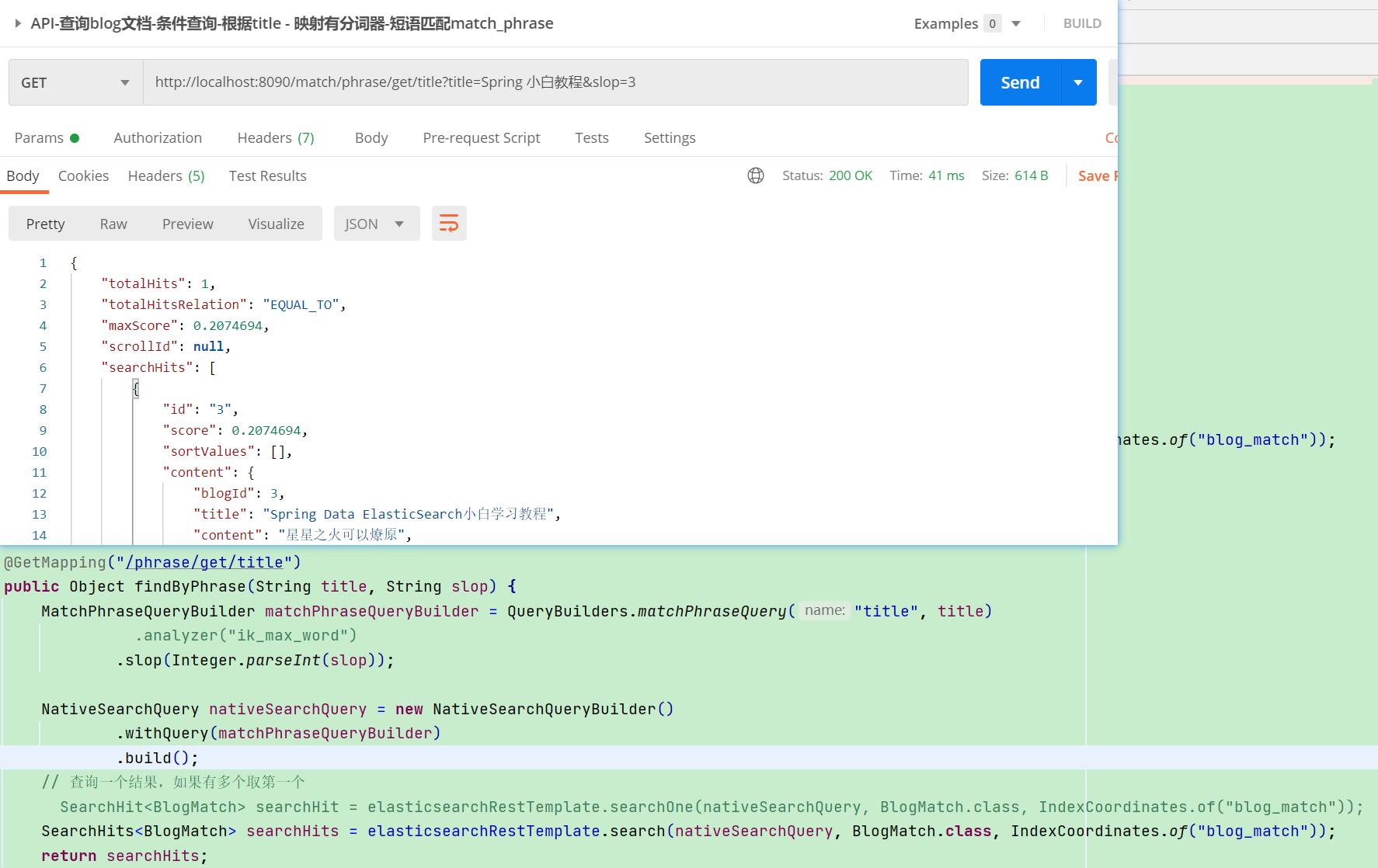
【栗子】查询"Spring小白教程"
·
【栗子分析】:
- 文档"Spring Data ElasticSearch小白学习教程"只需间隔3个分词(“data”,“elasticsearch”,“学习”)即可被查询出来
·
【API请求】:
·
- 此外,如果值为数组,如:“title”: [“Spring Data ElasticSearch”,“小白学习教程”],那么数组间存在position_increment_gap,默认100
- 如上述数组搜索"Spring小白教程",则slop值起码为103(100+3),才可搜索得到该文档
4. match_phrase_prefix查询:
短语前缀匹配:在match_phrase基础上,将最后一个分词作为前缀去匹配查询
【数据准备】:文档"title":“小白学习教程Euraka"和文档"title”:“小白学习教程ElasticSearch”
·
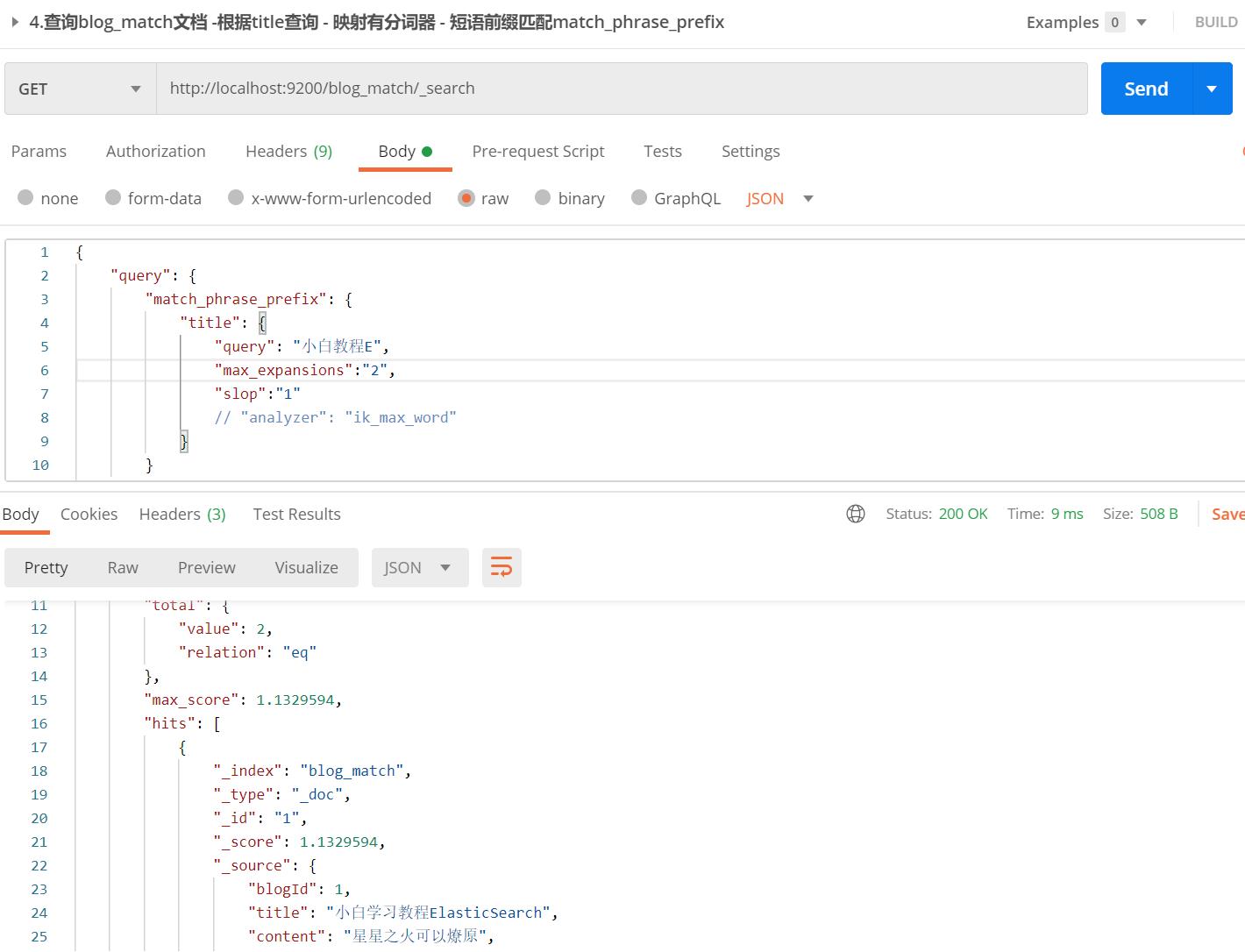
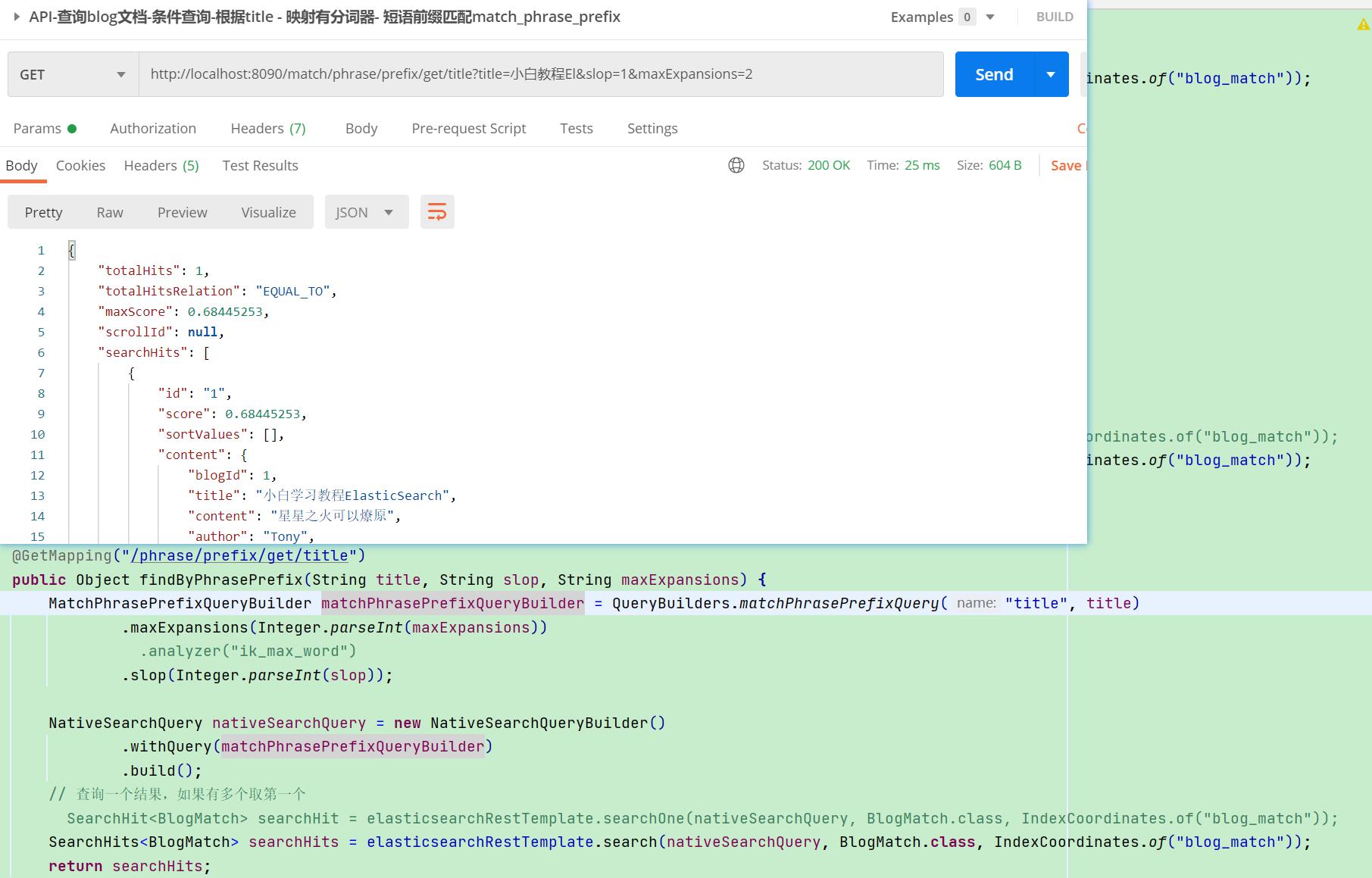
【栗子】查询"小白教程E"
·
【栗子分析】:
- 和match_phras一样,根据slop的设置,保证能进行到E的前缀匹配,通过E作为分词前缀,找到符合的文档
- max_expansions默认是50,指定为2,意味着取符合E前缀的所有文档的前两个;如果查询小白教程El,那么只能查询到1个
- max_expansions要注意是同一个分片数据的限制,不同分片可以routing指定,参考资料
·
【HTTP请求】:
·
【API请求】:
·
5. match_bool_prefix查询:
短语前缀乱序匹配:在match基础上的前缀匹配,同样将最后一个分词作为前缀去匹配查询
【数据准备】:文档"title":“小白学习教程Euraka"和文档"title”:“小白学习教程ElasticSearch”
·
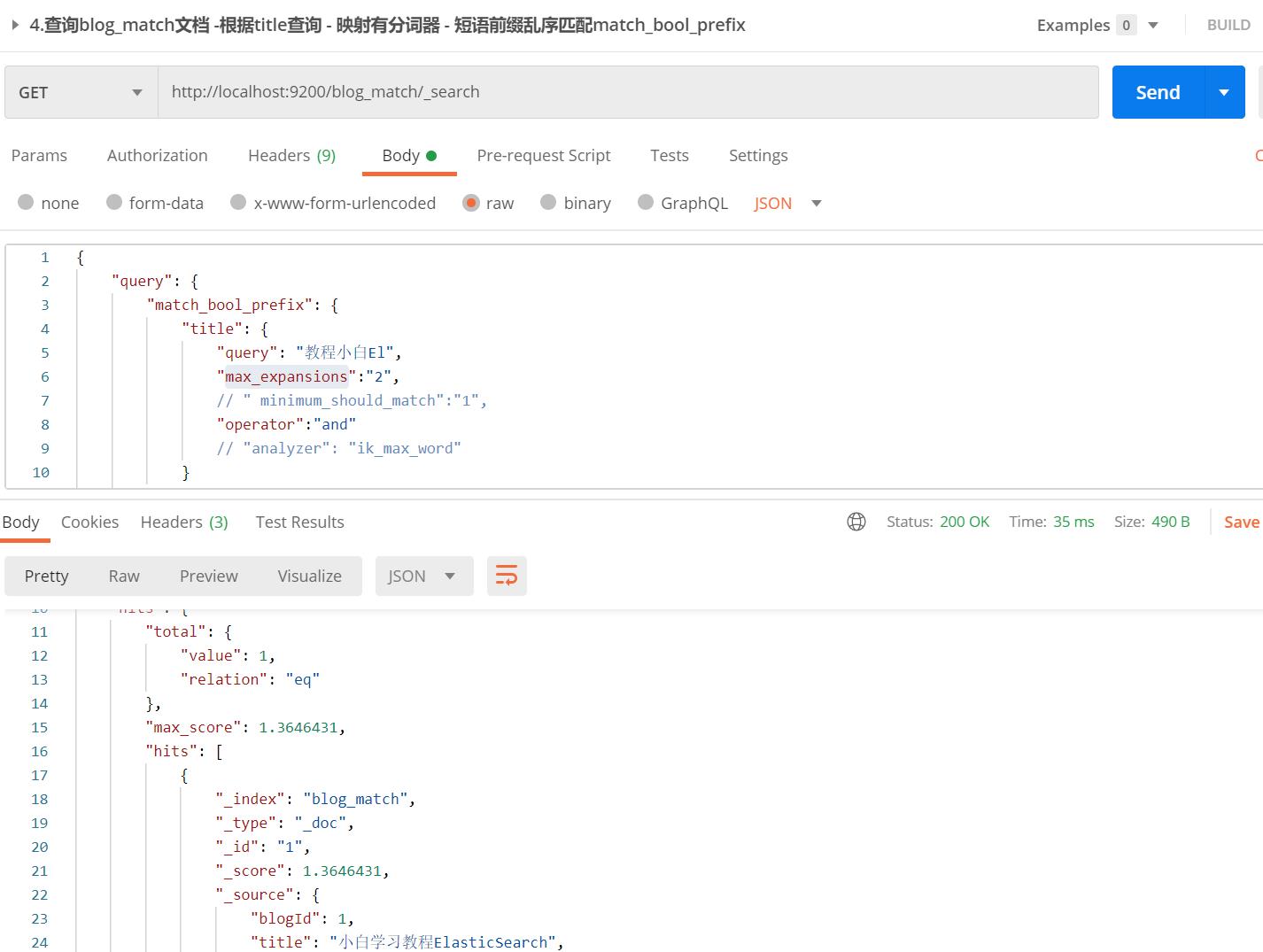
【栗子】查询"教程小白El"
·
【栗子分析】:
- 和match一样,可以设置operator、minimum_should_match参数;通match_phrase_prefix一样可以设置max_expansions参数
- 不像match_phrase_prefix查询要求文档的"教程"在"小白"之前,match_bool_prefix的分词可以乱序
- 所以同样的两个数据match_bool_prefix不用设置slop,也能查找到文档
·
【HTTP请求】:
·
【API请求】:暂无找到与之匹配的API,应该是使用bool的,这个后面再介绍
·
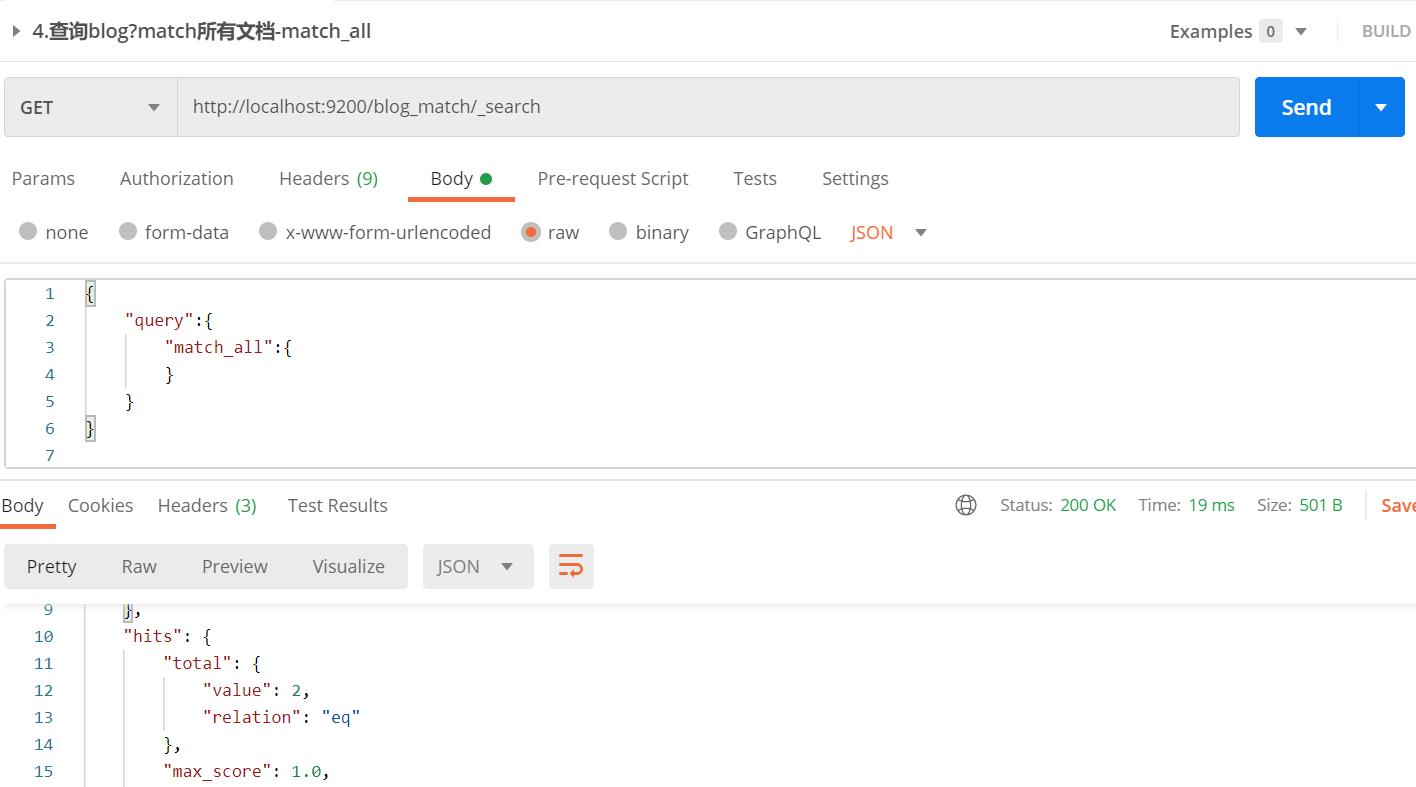
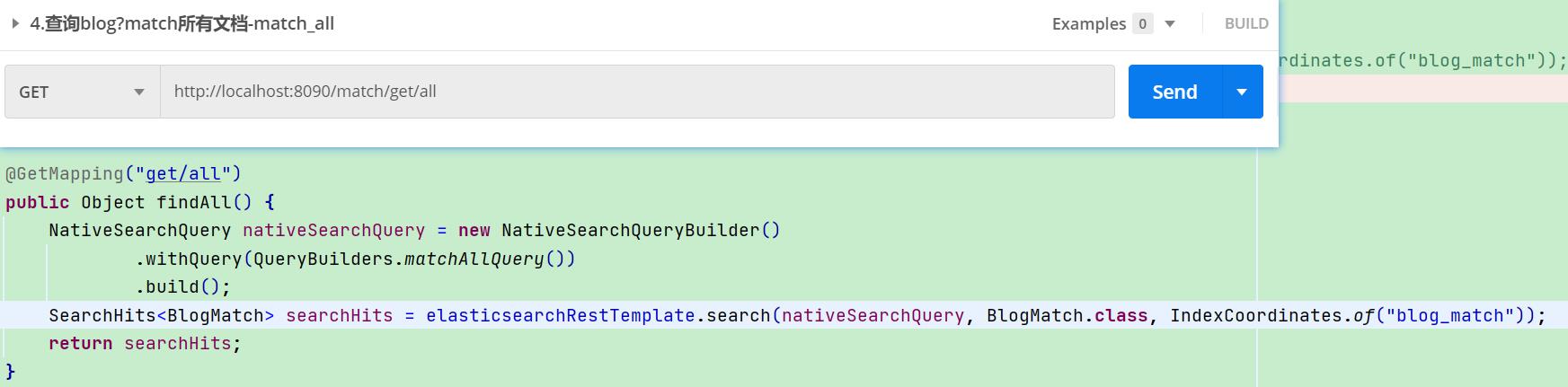
6. match_all查询所有:
直接索引/_search即可,也可以match_all使用DSL的方式查询所有文档
【HTTP请求】:
·
【API请求】:
·
7. multi_match查询:
多字段查询:基于match匹配查询,允许对多个字段进行匹配查询,有六种类型查询
- best_fields: 默认类型,查询与任何字段匹配的文档,但是使用匹配的最佳字段对应的 _score
- most_fields:查询与任何字段匹配的文档,并将所有匹配字段的 _score 进行合并
- cross_fields:把要匹配的所有字段当成一个大字段。对搜索词分析成分词列表,对每个分词在这个大字段上搜索,只要查询到,就算匹配上
- phrase:在每个要匹配的字段上运行 match_phrase 查询,并使用匹配的最佳字段对应的 _score
- phrase_prefix:在每个要匹配的字段上运行 match_phrase_prefix 查询,并使用匹配的最佳字段对应的 _score
- bool_prefix:在每个要匹配的字段上运行 match_bool_prefix 查询,并将所有匹配字段的 _score 进行合并
这里主要讨论best_fields、most_fields、cross_fields,其他的只是各字段查询方式不一样
7.1. best_fields类型查询:
更使用于在同一个字段搜索多个词,因为往往多个词在同一个字段比分开在多个字段更有意义
【数据准备】:准备两个文档内容"
“title”: “我爱北京天安门”,
“content”: “早起去广场上看升旗”“title”: “我爱我家广场”,
“content”: “广场上看升旗”·
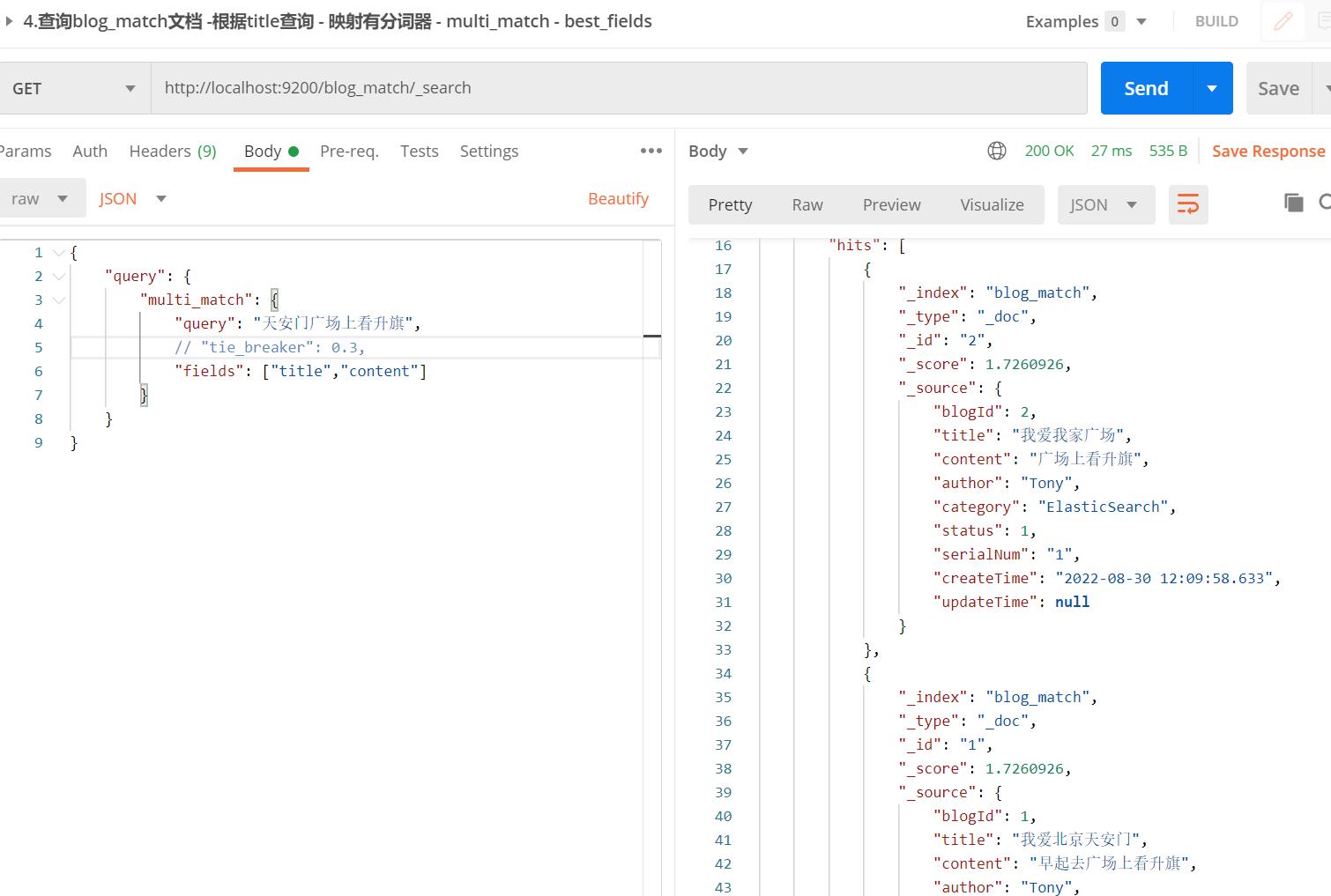
【栗子】多字段查询"天安门广场上看升旗"
·
【HTTP请求】:
·
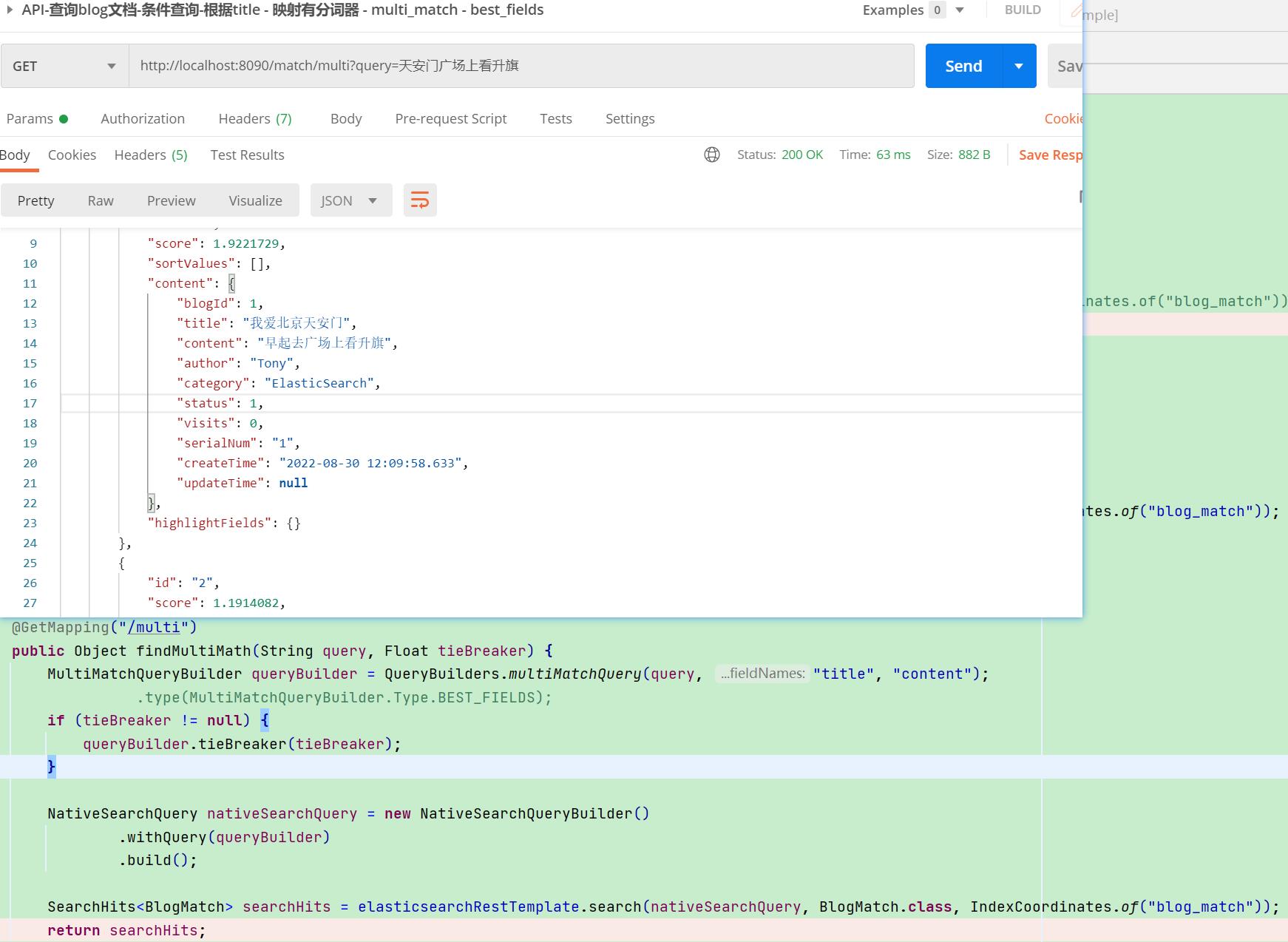
【栗子分析】:
- 按理应该blogId=1的更匹配,但best_fields查询时,最佳字段匹配的文档就越靠前
- 首先对比title,明显content的关联性更强(词短,匹配的分词多)
- 虽然blogId=1的title有明确的天安门,但很遗憾,best_fields采用关联性强的conten来进行score
- 明显blogId=2的content关联性更强(词短,匹配分词多),最终blogId=2的靠前
·
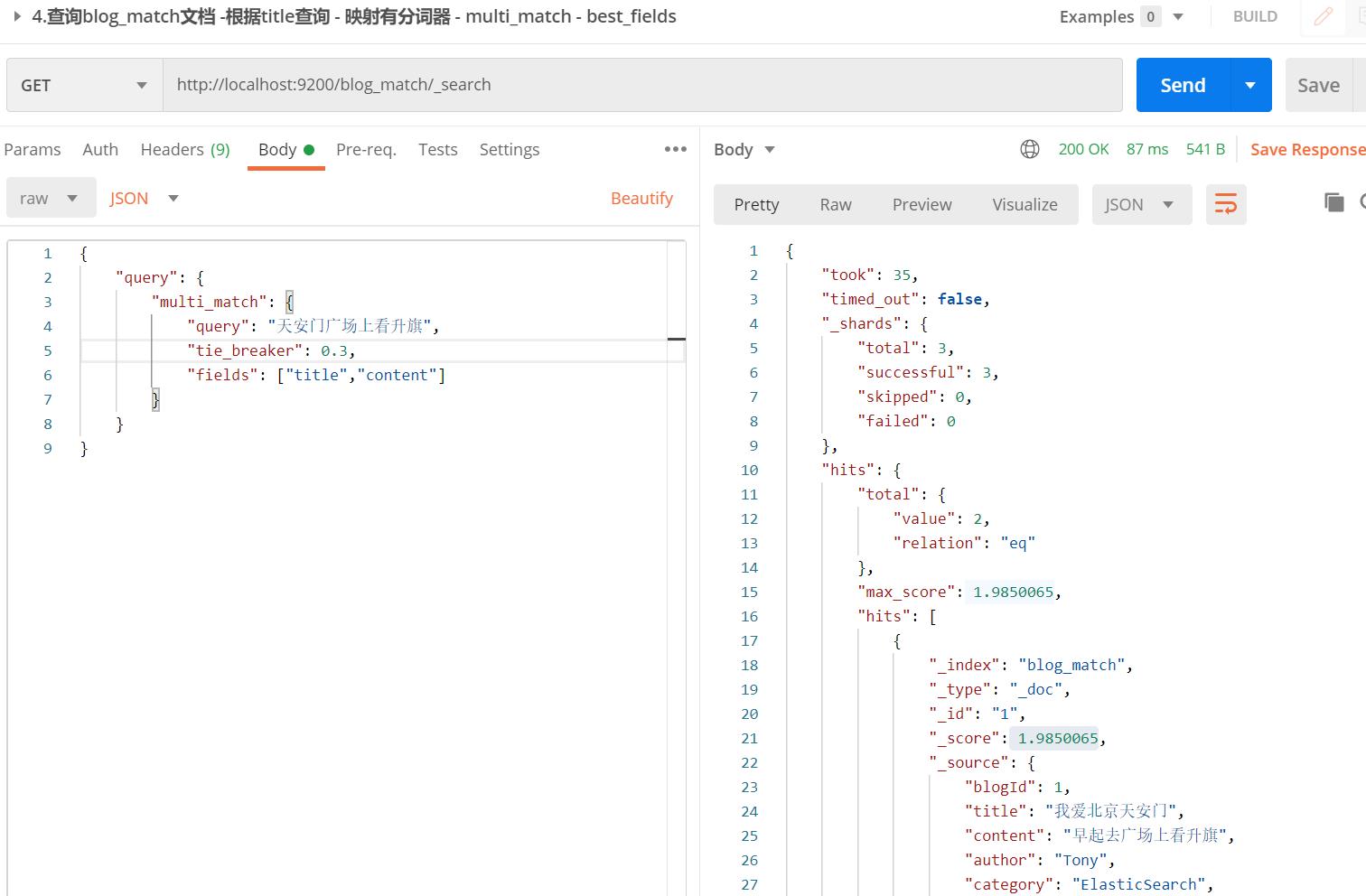
【栗子优化-使用tie_breaker】:
- tie_breaker:使用这个参数,会把非最佳的score也考虑进去,具体规则:最终_score = 最佳匹配的score+非最佳匹配的score*tie_breaker
- 1.9850065 = 1.7260926 + 0.8630463 * 0.3;score是怎么算出来的咱也不懂,反正最终的sorce就是这么来的,修改文档好像会影响score
- 可见,加上tie_breaker后就能较精确搜索到符合的文档
·
【API请求】:multiMatchQuery好像API的score不太一样,母鸡啊
·
7.2. most_fields类型查询:
结合多个字段搜索的相关性,最终评分高的靠前
【数据准备】:准备两个文档内容"
“title”: “我在北京天安门广场”,
“content”: “排队看升旗”“title”: “我在北京天安门”,
“content”: “广场很多人在排队看升旗”·
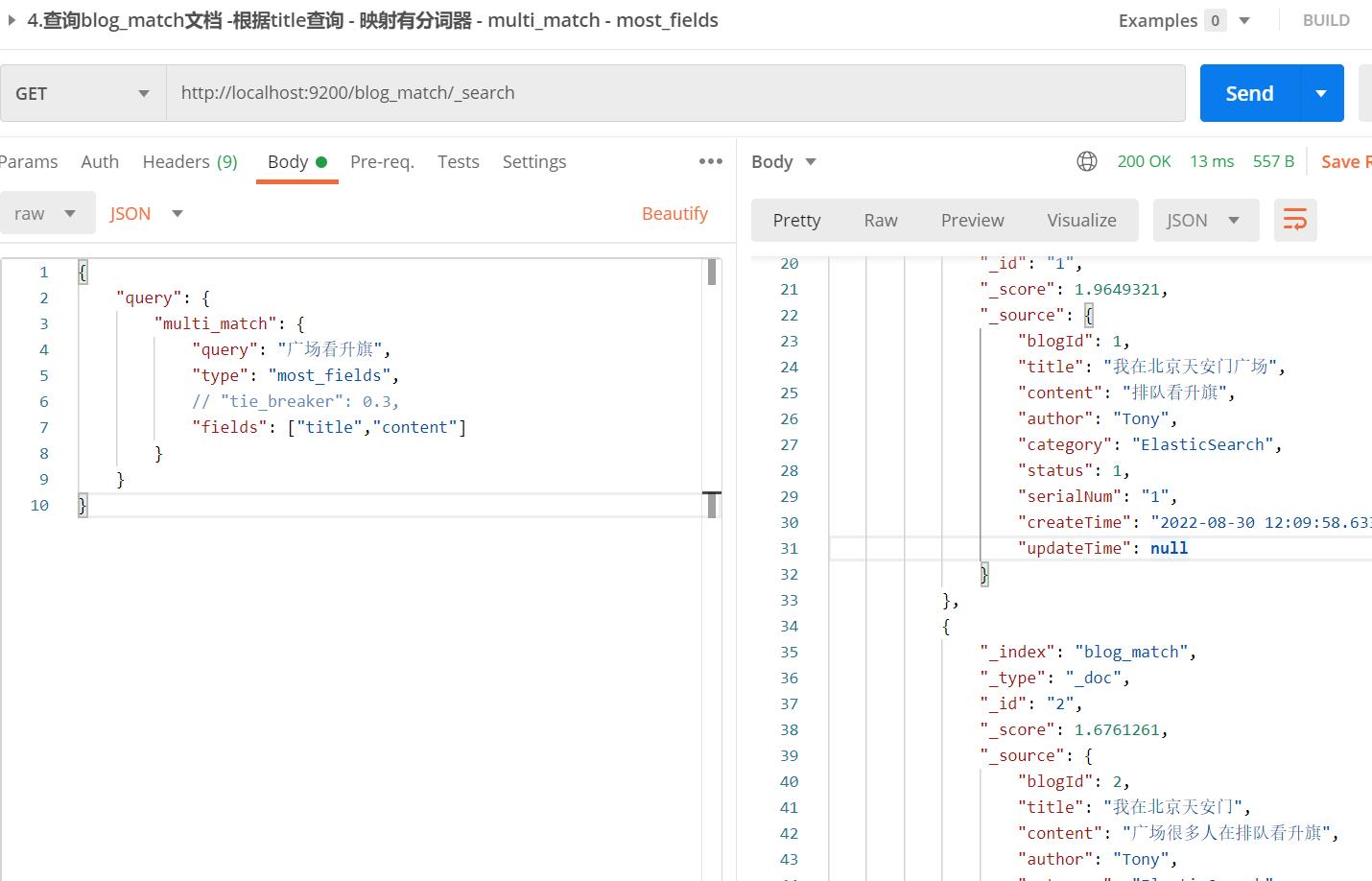
【栗子】多字段查询"广场看升旗"
·
【HTTP请求】:
·
【栗子分析】:
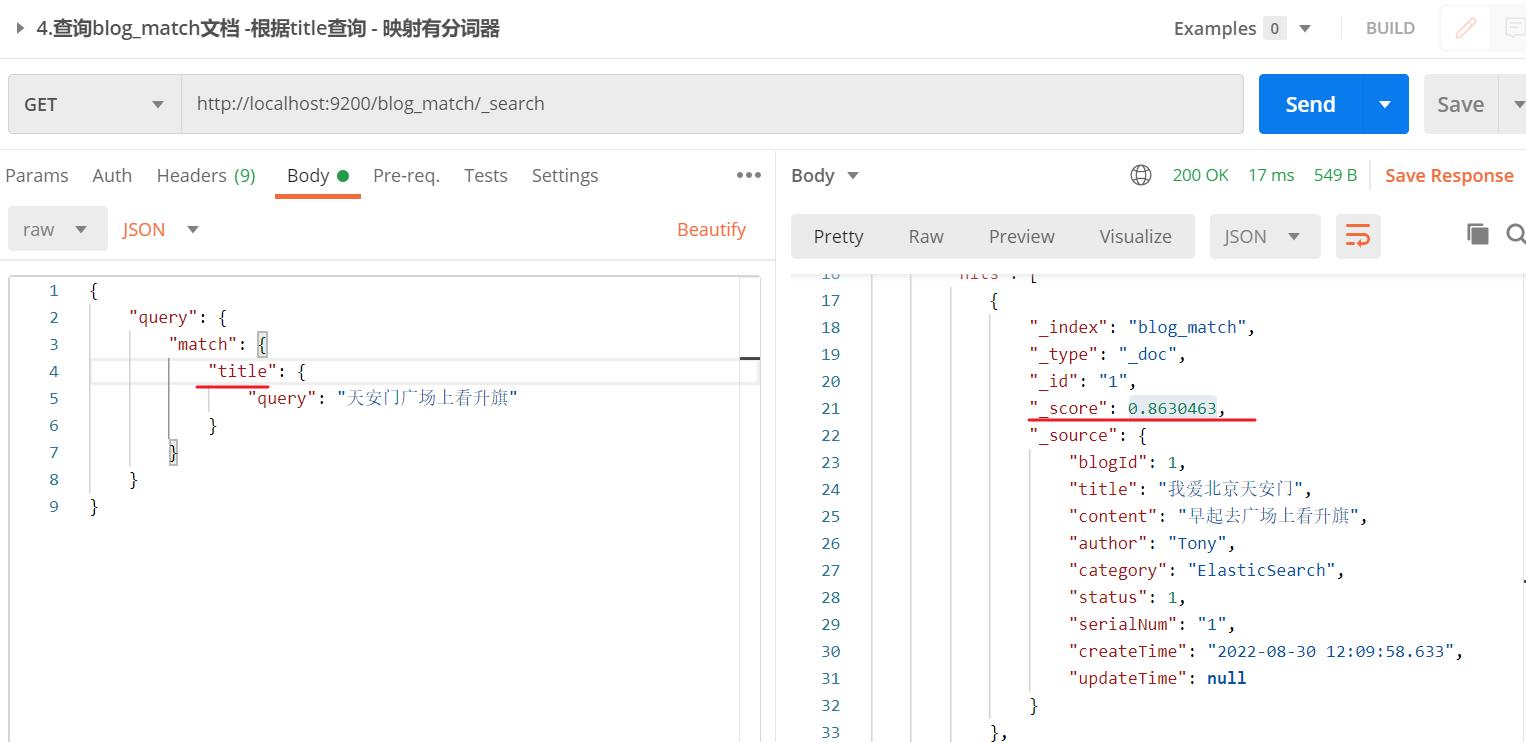
- 按理应该blogId=2的更匹配,但most_fields查询时,会考虑到其他非最佳字段匹配的相关性
- 首先blogId=2的title是没有相关性的,而blogId=1有分词"广场",所以有相关性
- 通过match的普通查询同一个搜索词,对于title结果显示blogId=2的score为0;而blogId=1的score为1.318853;
- 对于content结果显示blogId=2的score=1.6761261;而blogId=1的score为 0.6460791;
- 所以最终的score,如blogId=1的是1.9649321 = 0.6460791 + 1.318853,最终blogId=1的靠前
·
【API请求】:multiMatchQuery
·
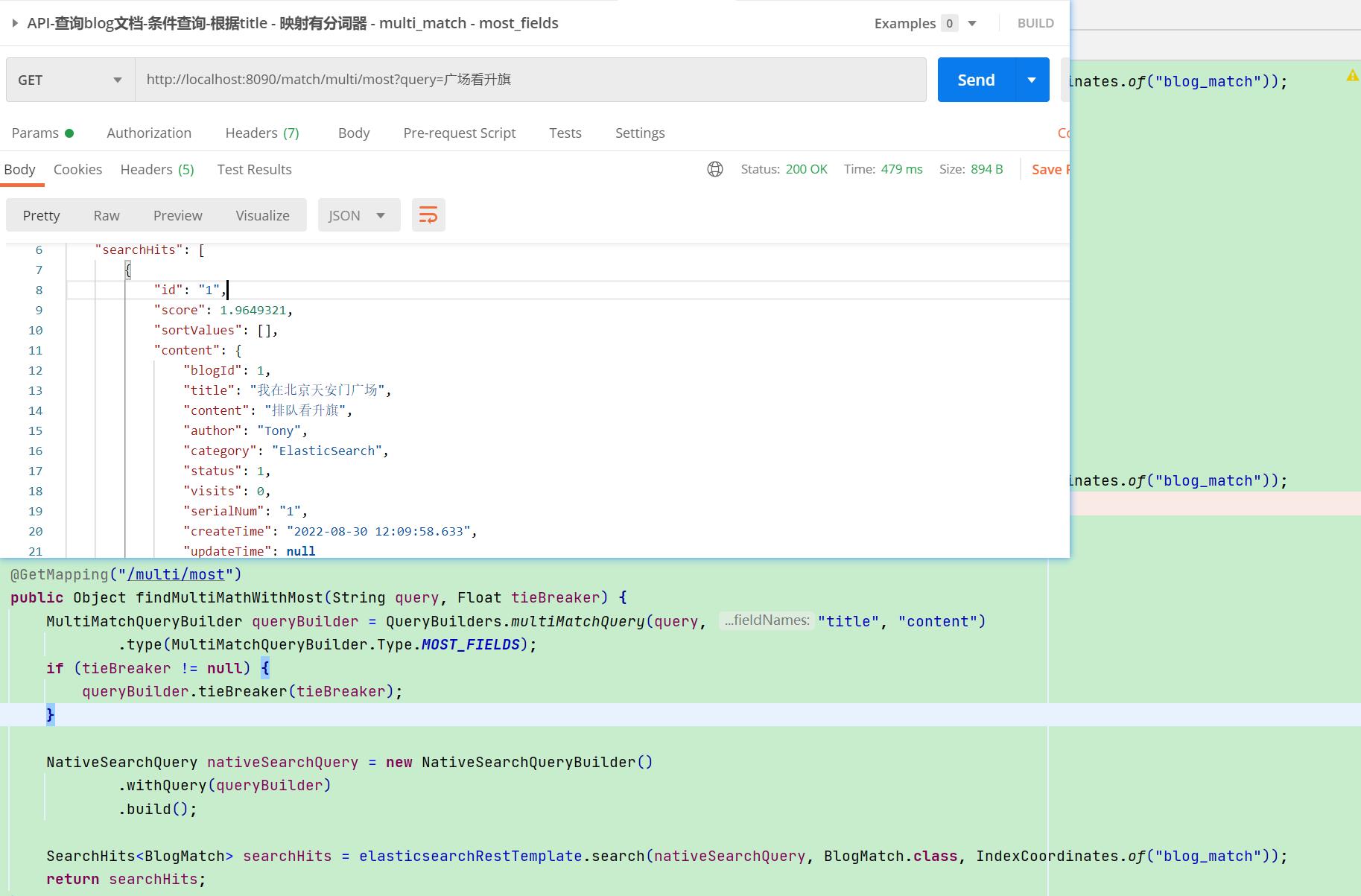
所以most_fields可以相当于best_fields + tie_breaker的效果,当然most_fields也支持tie_breaker参数
7.3. cross_fields类型查询:
- 类型相同的字段为一组,类似当作一个大字段;如果有类型不同,也就是多组,那么会结合bool-should来分析
- 对搜索词分析成分词列表,对每个分词在这个大字段上搜索,只要查询到,就算匹配上
- multi_match是支持operator和minimum_should_match参数的,但对于best_fields和most_fields会有所出入,因为他们是以字段为中心
【数据准备】:准备两个文档内容,其中这两个字段都是Text类型"
“content”: “ElasticSearch By Tony”,
“author”: “Tom”“content”: “ElasticSearch Use”,
“content”: “Tony”·
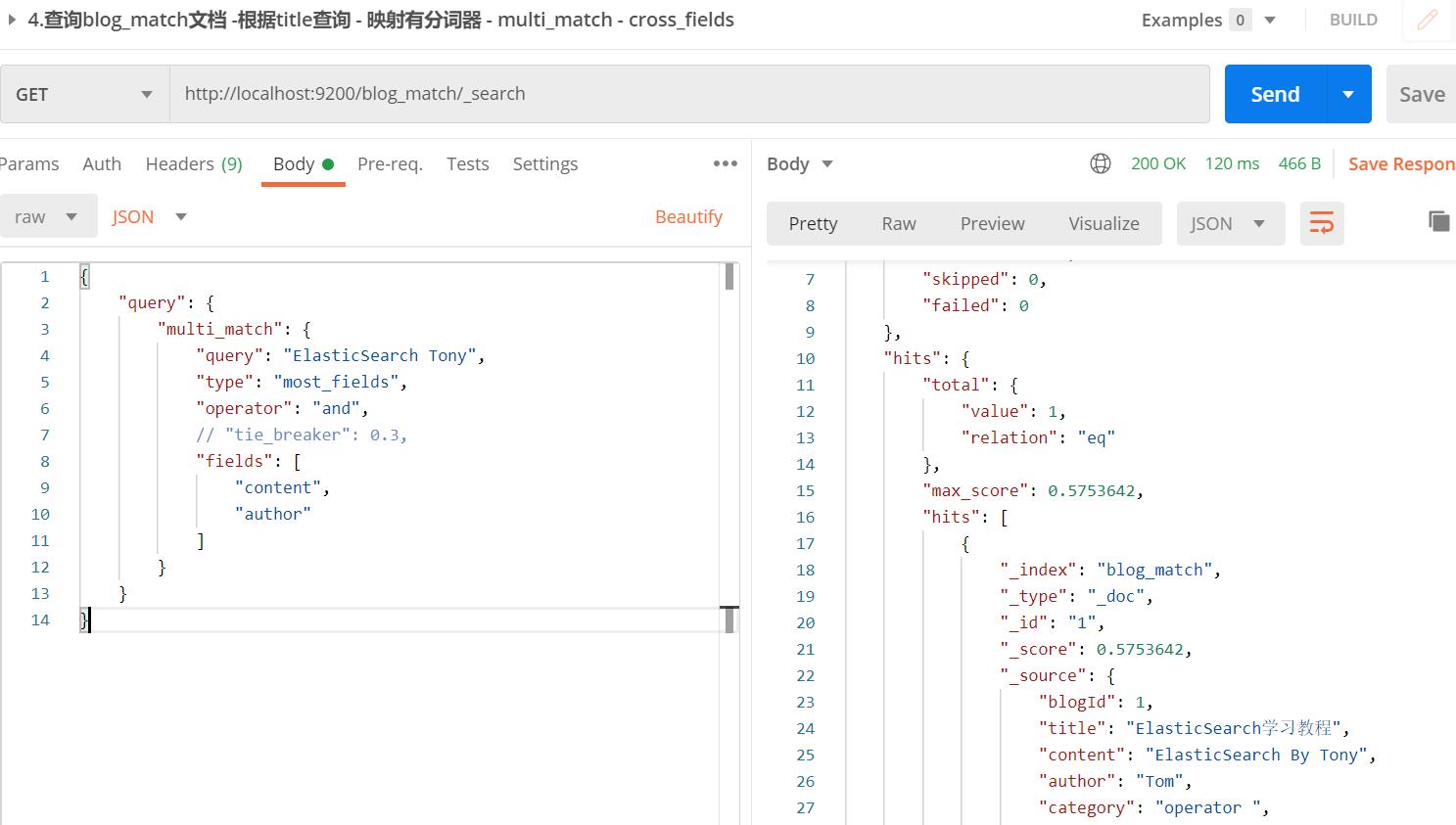
【栗子】多字段查询"ElasticSearch Tony"·
【HTTP请求】:most_fields并设置and操作符
·
【栗子分析】:most_fields并设置and操作符
- ElasticSearch Tony两个分词都需要在content或author字段上匹配才能匹配到文档,所以不能搜索到"ElasticSearch Use"的文档
·
【栗子分析】:most_fields并设置and操作符
·
【HTTP请求】:cross_fields并设置and操作符
·
【栗子分析】:cross_fields并设置and操作符
- 将同类的字段进行组合,此处类似一个大字段"ElasticSearch Use Tony"
- cross_fields是以词为中心,将"ElasticSearch","Tony"两个分词同时能在上述字段组合中匹配成功,即可搜索到文档
·
【API请求】:multiMatchQuery
·
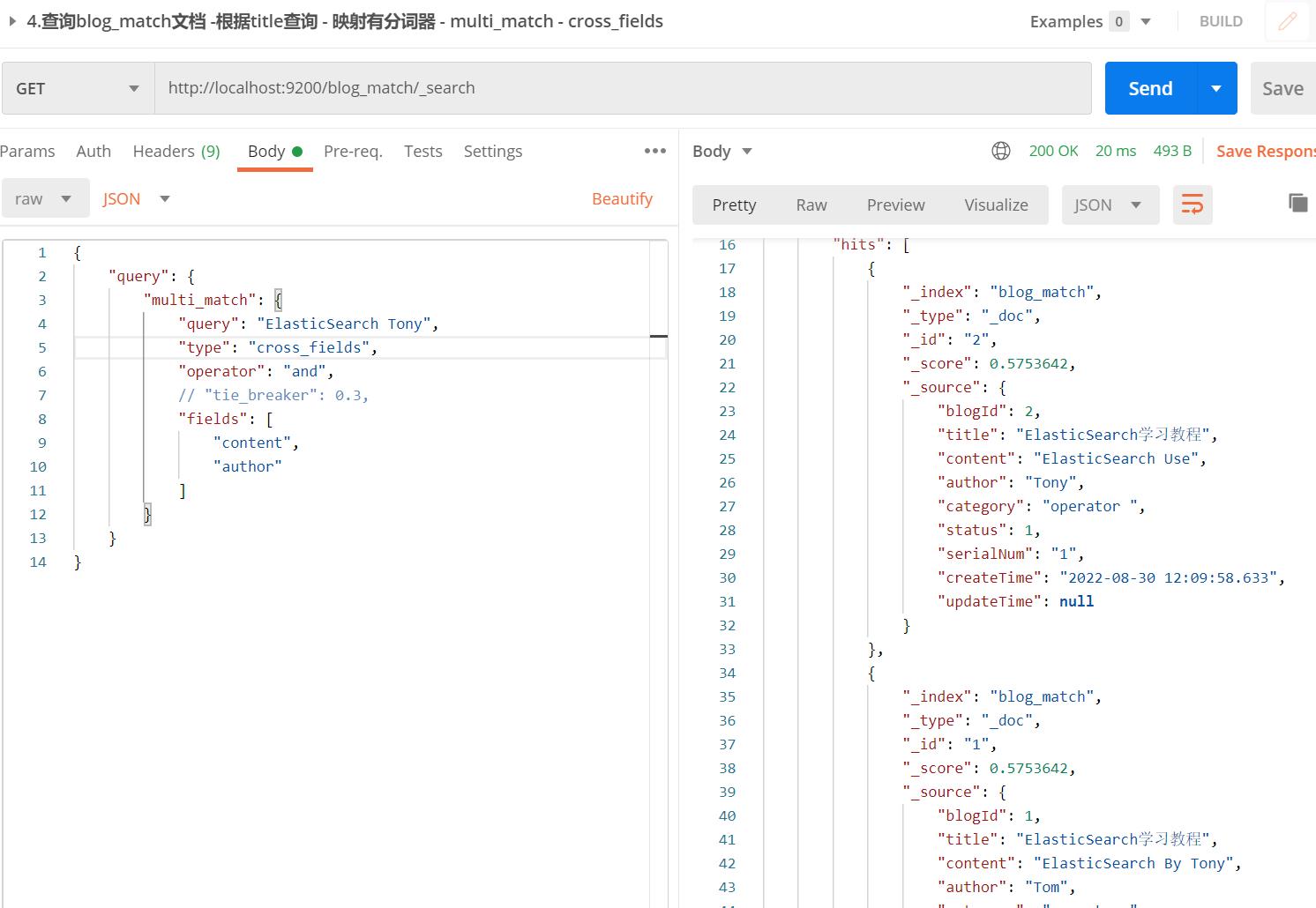
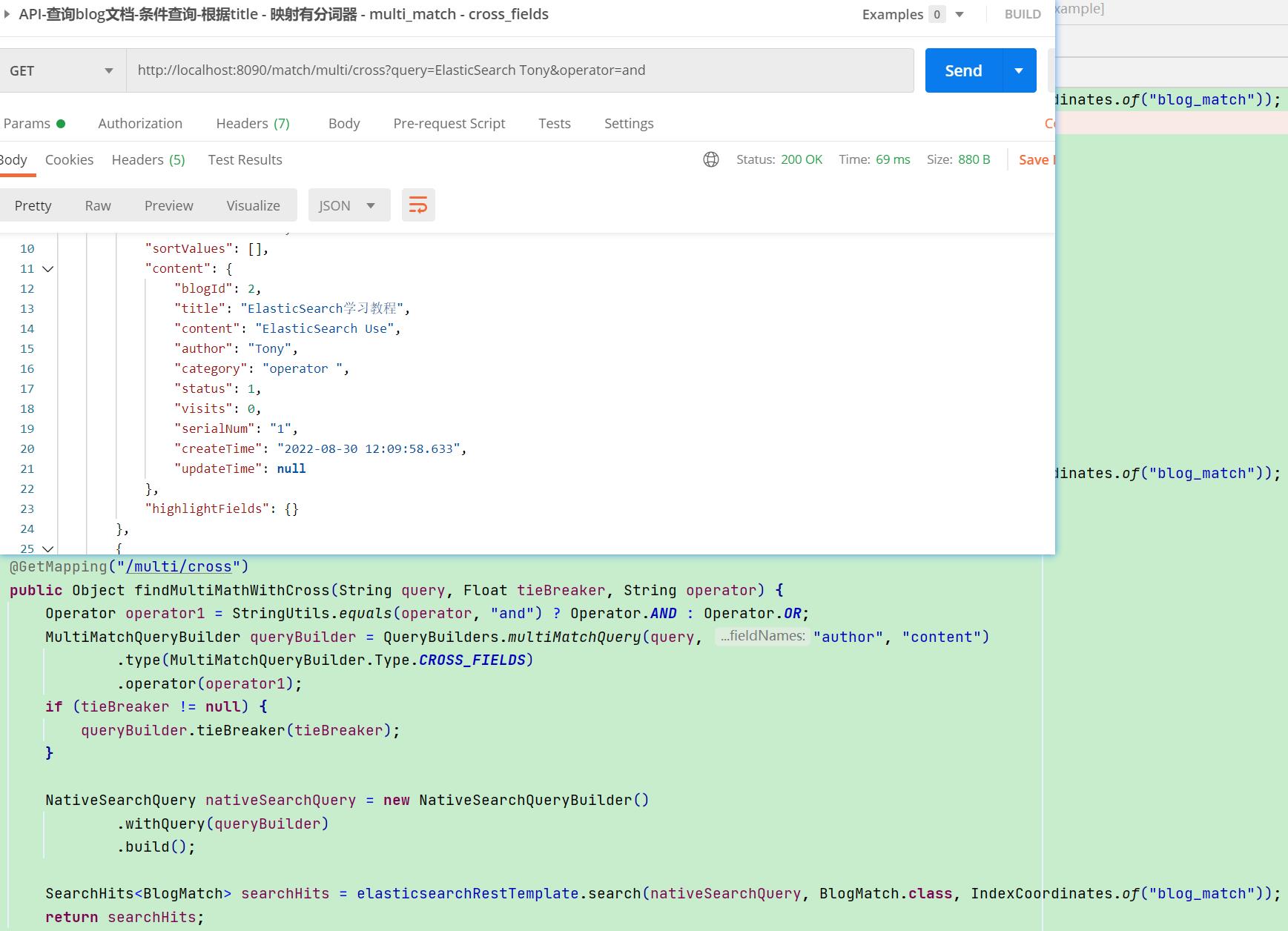
cross_fields和best_fields,most_fields一个区别就是cross会将同类字段组合再进行分词匹配
7.4. 字段通配符和字段加权提升:

boost 会影响字段匹配的score,从而影响结果
以上是关于初识ElasticSearch -文档查询之match查询 | 分词器的主要内容,如果未能解决你的问题,请参考以下文章