A Hierarchical Model for Data-to-TextGeneration阅读笔记
Posted 云才哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了A Hierarchical Model for Data-to-TextGeneration阅读笔记相关的知识,希望对你有一定的参考价值。
目录
四、模型介绍(Hierarchical Encoder Model for Data-to-Text)
前言:
论文发表于2019年
论文链接:A Hierarchical Model for Data-to-Text Generation
一、摘要(abstract)
在摘要部分作者主要提了两方面内容:
- 现有问题提出:现在的data-to-text通常是依赖于翻译任务的编码解码器模型,在此过程中需要将表格(结构化数据)转化为一个线性的序列,但这样子就丢失了原有结构化数据所拥有的结构化信息。
- 问题解决方案(创新工作):通过使用元素级和结构级两层编码来使得尽可能减少输入信息的损失。
二、引言(Introduction)
在引言这一部分,作者介绍了
- 结构化数据主要包括:索引、表、键值对或三元组
- 研究意义:结构化数据不容易被人们理解和使用,所以使用自然语言概括它们以减轻它们的可理解性和有用性具有较好的实际意义。
- 研究应用:
- 可应用行业:新闻、医疗
- 可开发应用程序:财务和天气分析报告
- 体育广播
- 现有工作的主要做法:(基于翻译的编码-解码框架)
- 首先将结构化的数据表示成一个固定长度的序列
- 引入注意力机制使得模型专注于重要的元素,
- 引入复制机制来处理未知词和罕见词
- 对现有模型的吐槽:
- 结构化数据线性化:当前的工作主要集中在解码部分的创新,而对于编码部分仍然采用的是序列化编码(即将一个表格表示为:[(行索引, 列索引, 取值), ..., (行索引, 列索引, 取值)]),如此损失了各行之间的差异。
- 循环神经网络包含的潜在语义信息:由于循环神经网络循序的特点,使得原本没有顺序关系的序列化的结构化数据在编码是默认具备先后顺序的,由此对学习的性能造成了一定的影响。
- 提出新的编码方案(创新工作):
- 两层编码:
- 根据数据元素对所有实体进行编码
- 基于所有实体对数据结构进行编码
- 引入Transformer进行编码
- 整合了一个层次化的注意机制
- 两层编码:
三、相关工作(Related Work)
在这一部分,作者介绍了这一领域的起源,以及现有的相关研究工作,介绍了从研究工作的演化,阐述了自己研究工作的由来。
介绍了自己工作相对于已有工作的创新点:实际上就是对自己在引言中提到的创新工作的细节阐述。
四、模型介绍(Hierarchical Encoder Model for Data-to-Text)
模型的主要贡献是在编码阶段(采用两层编码),在解码部分直接采用别人的成果(带复制机制的两层LTSM)
1、数据介绍:
实验采用的数据集是RotoWire,目的是通过表格类型的结构化数据集自动生成描述文本。
针对RotoWire数据集:该数据属于当前Table-to-Text任务中较难的数据集,首先,其结构化数据部分由两个表格构成,第一个表格记录的是整队的比赛数据,而第二个表格记录的是每一个球员的比赛数据。而描述文本显然的结构是:首先根据整队的比赛数据分析和推理哪个队获胜,对整队的数据进行对比。然后,对各个队员进行分析,主要分析表现好的队员,所以这里其实需要判断哪个队员更加“值得去描述”。

2、符号介绍:
entity ei:实体实际上就是表格数据中的一行,如(Hawks, Magic, Al Horford, Jeffff Teague, ...)
record ri j:记录是一个键值对,实际上就是每一行的元素值,键为列索引,如(PTS, 17), (REB, 0), (AST, 7) ...
整体的表格结构使用s表示,而描述文本则使用y表示。
符号间的关系:一个实体由一组记录(record)组成,一个表格则由一组实体(entity)组成。
3、模型介绍:
该论文模型的创新主要在编码过程,而在解码部分,模型直接采用的是两层使用带复制机制的两层LSTM网络。
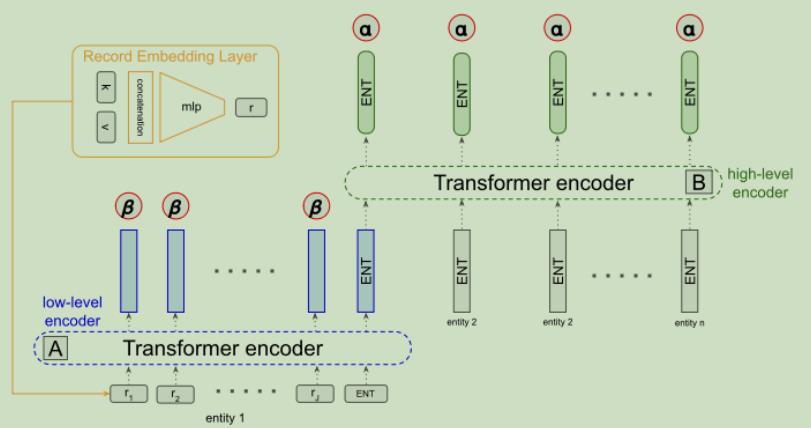
1.分层编码模型
- 第一层编码器:根据实体的记录对各个实体进行编码
- 第二层编码器:根据表格的实体对整个表格结构进行编码
2.记录数据表示
在模型的第一层使用记录嵌入层(Record Embedding Layer)来表示各个记录,所以在第一层编码部分,在输入数据处理部分需要先得到记录的嵌入表示。
在文章中,作者首先将记录的每一个元素进行记录嵌入:如将键 ki,j 使用向量 ki,j 表示,而元素对应的值vi,j表示 vi,j ,将每一个元素的键和值进行关联,使用[ki,j ; vi,j ]进行表示。最终的记录嵌入表示ri,j 则使用公式:
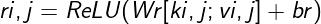
得出。
模型编码部分计算图如下图所示:
3.分层注意力机制
为了充分利用分层编码的优势,文章使用分层注意力机制。文章假设在根据表格数据得到对应的文本时,首先关注实体,然后关注与这些实体对应的记录。文章中介绍了两种分层注意力机制:
1.Traditional Hierarchical Attention:(关注的是整个记录)
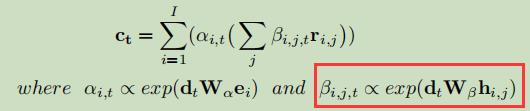
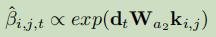
4、模型评测指标:
- BLEU Score:常用于翻译效果评测
-
Information extraction-oriented metrics
- Relation Generation (RG):测量生成的描述中有多少记录的取值是准确的。
- Content Selection (CS):测量生成的描述中有多少记录在真实描述中也被提到
- Content Ordering (CO):测量选中的记录在顺序上的表现
五、实验结果分析(Results)
模型整体效果评测:可以发现在Hierarchical-k注意力机制下的模型效果指标相对较好,如图,图中加粗的数据即为模型得出的最佳指标。

模型注意力机制对比:(如下图所示,虽然在两种注意力机制下的模型都选中了相同的实体,但是在记录选取的时候,Hierarchical-k(只用记录的键来计算注意力)选取更加准确)
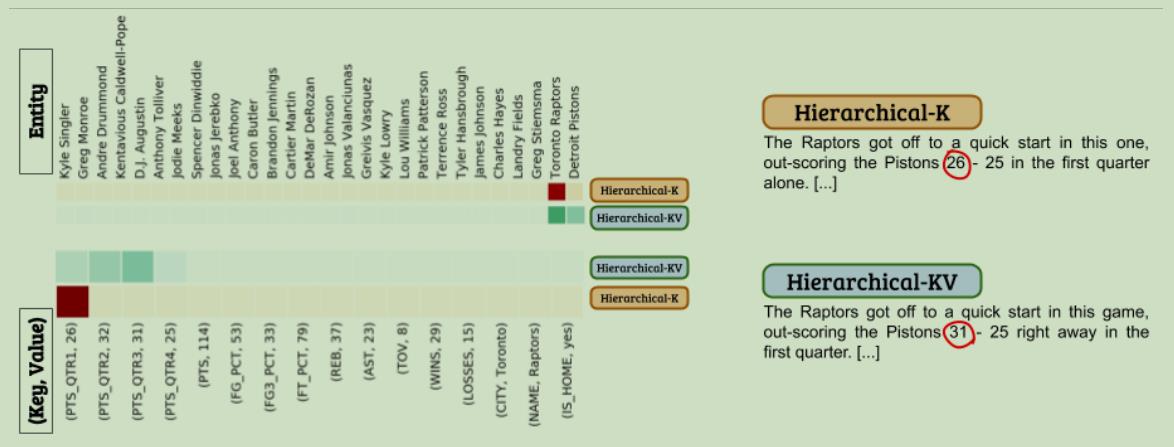
模型最后预测得出的文本:(下图的描述可以直接和上文中的数据介绍部分的描述进行比较),如下图:黑色加粗表示实体,在原文中提到的使用绿色表示,红色表示错误提到的数据,而蓝色表示没有错也没有在原文中提及的语句。

六、总结
本文提出的模型大体思路就是参考人类在根据一个表格书写描述文本时,首先考虑的是需要书写哪个实体,然后考虑需要描述这一个实体的哪些记录信息。实现过程大体分为两部分:
- 使用两层编码,在编码时先考虑对记录进行编码,然后再对实体进行编码,从而记录下整个表格结构。
- 结合编码特点,使用分层的注意力机制。
以上是关于A Hierarchical Model for Data-to-TextGeneration阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章