MySQL从入门到精通高级篇(二十五)EXPLAIN中refrowsfilteredExtra字段的剖析
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL从入门到精通高级篇(二十五)EXPLAIN中refrowsfilteredExtra字段的剖析相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 5. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
1. 简介
上一篇文章我们介绍了
【MySQL从入门到精通】【高级篇】(二十四)EXPLAIN中select_type,partition,type,key,key_len字段的剖析,重点介绍了EXPLAIN命令的select_type,partition,type,key,key_len 字段含义。这篇文章我将接着介绍剩余字段的含义。本文会介绍ref、rows、filtered、Extra这几个字段。比较重要的两个字段是rows、Extra
2. 测试的表和数据

详细的测试表创建以及插入测试数据,请参见:【MySQL从入门到精通】【高级篇】(二十三)EXPLAIN的概述与table,id字段的剖析,其中:Extra 字段非常重要
3. ref
ref:当使用索引列等值查询时,与索引列进行等值匹配的对象信息。比如只是一个常数或者某个列。
测试的SQL
EXPLAIN SELECT * FROM s1 WHERE common_field='A';
EXPLAIN SELECT * FROM s1 WHERE key1='a';
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id=s2.id;
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s2.key1=UPPER(s1.key1);
-
使用非索引列

-
使用索引列进行常数等值查询

-
使用主键关联查询
这里会列出数据库名.表名.字段名

-
使用索引列 包含函数查询
这里列出的则是表示使用到了函数

4. rows
rows: 预估的需要读取的记录条数,值越小越好
测试的SQL语句
EXPLAIN SELECT * FROM s1 WHERE key1='z';
EXPLAIN SELECT * FROM s1 WHERE key1>'z';
- 可以通过索引精确查找
这里key1='z'可以直接通过索引精确查找,所以预估的rows为1。

- 范围查找
这里key1>'z'可以不能通过索引精确查找,所以预估的rows大于1。这里的rows值为398。

5. filtered
filtered 表示某个表经过搜索条件过滤后剩余记录条数的百分比,如果使用的是索引执行的单表扫描,那么计算时需要估计出满足除使用到对应索引的搜索条件外的其他搜索条件的记录有多少条。
- 单表查询的情况
EXPLAIN SELECT * FROM s1 WHERE key1>'z' AND common_field='a';

这里s1表预计扫描了398条记录,其中10%满足条件。
2. 连接查询的情况
对于单表查询来说,这个filtered列的值没什么意义,我们更关注在连接查询中驱动表对应的执行计划记录的filtered值,它决定了被驱动表要执行的次数(即:rows*filtered)
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.key1=s2.key1 WHERE s1.common_field='a';

从执行计划中可以看出,查询优化器打算把s1当做驱动表,s2当做被驱动表,我们可以看到驱动表s1表的执行计划的rows列为9895,filtered列为10.00, 这意味着驱动表s1的扇出值就是9895*0.1=989.6,这说明还要对被驱动表执行大概989次查询。
6. Extra
顾名思义,Extra列是用来说明一些额外信息的,包含不适合在其他列中显示但十分重要的额外信息,我们可以通过这些额外信息来更准确的理解MySQL到底将如何执行给定的查询语句。mysql提供的额外信息有好几十个,我们就不一个个介绍了,所以我们只挑选比较重要的额外信息。
6.1. No tables used
当查询语句的没有FROM子句时将会提示该额外信息,比如:
EXPLAIN SELECT 1;

6.2. Using where
当我们使用全表扫描来执行对某个表的查询,并且该语句的WHERE 子句中有针对该表的搜索条件时,在Extra 列中会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE common_field='a';

当使用索引访问来执行对某个表的查询,并且该语句的WHERE 子句中,有除了该索引包含的列之外的其他搜素条件时。在Extra 列中也会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE key1='a' AND common_field='a';

6.3. Using index
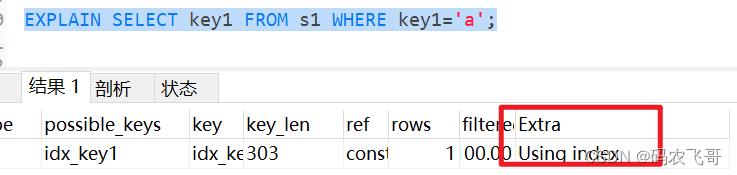
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下,在Extra 列将会提示该额外信息,比方说下边这个查询中只需要使用到idx_key1 而不需要回表操作
EXPLAIN SELECT key1 FROM s1 WHERE key1='a';
6.4. Using index condition
有些搜索条件中虽然出现了索引列,但却不能使用到索引
EXPLAIN SELECT * FROM s1 WHERE key1>'z' AND key1 LIKE '%a';

这里根据key1>'z' 的条件预估会找出398条记录,然后在根据主键id 到聚簇索引中去进行回表操作。如果使用 Using index condition 的话在会在回表之前先从398条记录中筛选满足 key1 LIKE '%a' 的记录,再去进行回表操作。
6.5. Using join buffer (Block Nested Loop)
在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer 的内存块来加快查询速度,也就是我们所讲的基于块的嵌套循环算法

6.6. Not exists
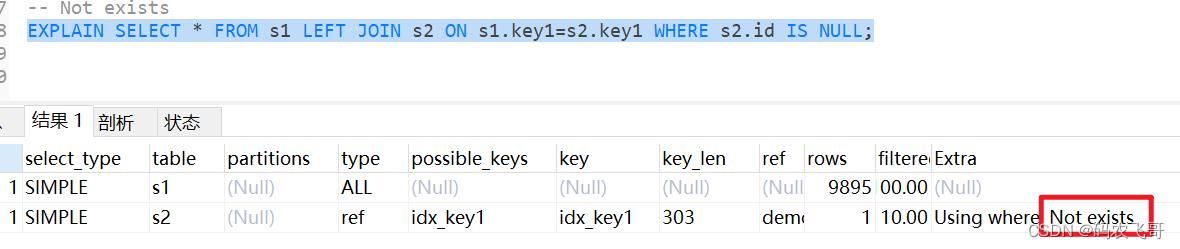
当我们使用左(外)连接时,如果WHERE 子句中包含要求被驱动表的某个列等于NULL 值的搜索条件,而且那个列又是不允许存储NULL值的,那么在该表的执行计划的Extra列就会提示Not exists 额外信息。
EXPLAIN SELECT * FROM s1 LEFT JOIN s2 ON s1.key1=s2.key1 WHERE s2.id IS NULL;
6.7. Using union
如果执行计划的Extra 列出现了Using intersect(…) 提示,说明准备使用Intersect 索引合并的方式执行查询,括号中的**…** 表示需要进行索引合并的索引名称;如果出现Using union(…) 提示,说明准备使用Union 索引合并的方式执行查询,出现了Using sort_union(…) 提示,说明准备使用Sort-Union 索引合并的方式执行查询。
EXPLAIN SELECT * FROM s1 WHERE key1='a' OR key3='a';

6.8. Using filesort
有一些情况下对结果集中的记录进行排序是可以使用到索引的,比如下边这个查询:
EXPLAIN SELECT * FROM s1 ORDER BY key1 LIMIT 10;

这个查询语句可以利用 idx_key1 索引直接取出key1列的10条记录,然后在进行回表操作就好了,但是很多情况下排序操作无法使用到索引,只能在内存中(记录较少的时候)或者磁盘中(记录较多的时候)进行排序,MySQL把这种内存中或者磁盘上进行排序的方式统称为文件排序(英文名:filesort)。如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的Extra列中显示Using filesort 提示,如果这样:
EXPLAIN SELECT * FROM s1 ORDER BY common_field LIMIT 10;

6.9. Using temporary
在许多查询的执行过程中,MySQL可能会借助临时表来完成一些功能,比如去重,排序之类的,比如我们在执行许多包含DISTINCT、GROUP BY、UNION等子句的查询过程中,如果不能有效利用索引来完成查询,MySQL很有可能寻求通过建立内部的临时表来执行查询。如果查询中使用到了内部的临时表,在执行计划的Extra 列将会显示Using temporary 提示
EXPLAIN SELECT DISTINCT common_field FROM s1;
EXPLAIN SELECT common_field,COUNT(*) AS amount FROM s1 GROUP BY common_field;

执行计划中出现Using temporary 并不是一个好的征兆,因为建立与维护临时表要付出很大成本的,所以我们最好能使用索引来替换掉使用临时表,比如:扫描指定的索引 idx_key1即可。
EXPLAIN SELECT key1,COUNT(*) AS amount FROM s1 GROUP BY key1;

从Extra的Using index 的提示里我们可以看出,上述查询只需要扫描idx_key1 索引就可以搞定了,不再需要临时表了。
6.10 小结
- EXPLAIN 不考虑各种Cache
- EXPLAIN 不能显示MySQL在执行查询时所作的优化工作
- EXPLAIN不会告诉你关于触发器,存储过程的信息或用户自定义函数对查询的影响情况
- 部分统计信息是估算的,并非精确值。
7. EXPLAIN 四种输出格式
EXPLAIN可以输出四种格式:传统格式、JSON格式、TREE格式以及可视化输出。用户可以根据需要选择适用于自己的格式。
7.1. 传统格式
传统格式简单明了,输出是一个表格形式,概要说明查询计划

7.2. JSON格式
第一种格式中介绍的EXPLAIN语句输出中缺少了一个衡量执行计划好坏的重要属性–成本,而JSON格式是四种格式里面输出信息最详尽的格式,里面包含了执行的成本信息。
JSON格式:在EXPLAIN单词和真正的查询语句中间加上FORMAT=JSON。
EXPLAIN FORMAT=JSON SELECT ....
EXPLAIN 的Column与JSON的对应关系:(来源于MySQL 5.7文档)
| Column | JSON Name | Meaning |
|---|---|---|
| id | select_id | The Select identifier |
| select_type | None | The SELECT type |
| table | table_name | The table for the output row |
| partitions | partitions | The matching partitions |
| type | access_type | The join type |
| possible_keys | possible_keys | The possible indexes to choose |
| key | key | The index actually chosen |
| key_len | key_length | The length of the chosen key |
| ref | ref | The columns compared to the index |
| rows | rows | Estimate of rows to be examined |
| filtered | filtered | Percentage of rows filtered by table condition |
| Extra | None | Additional information |
| 这样我们就可以得到一个json格式的执行计划,里面包含该计划花费的成本,比如这样: |
EXPLAIN FORMAT=JSON SELECT * FROM s1 \\G;
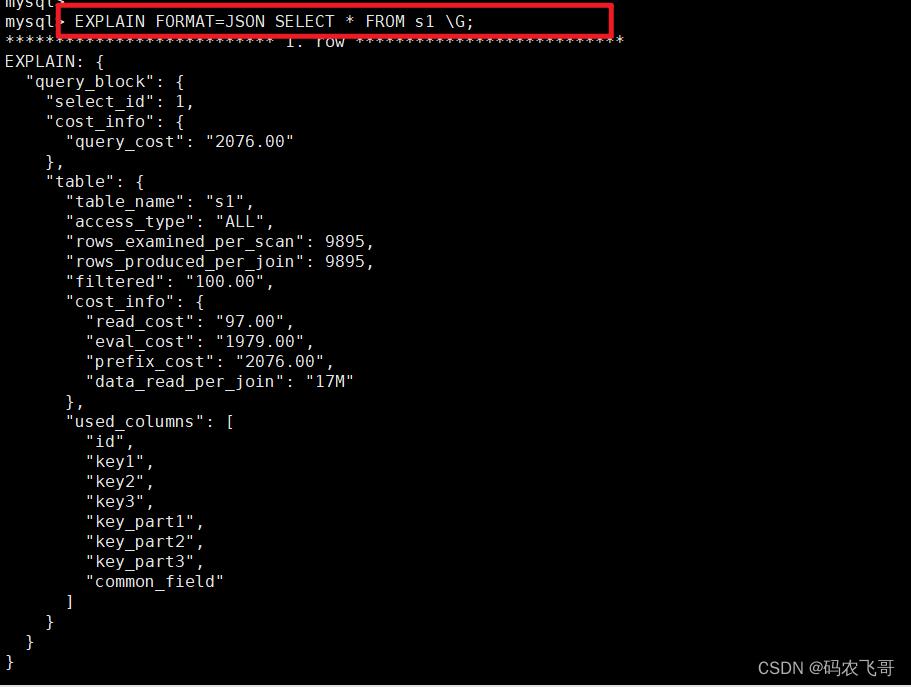
其中:"query_cost": "2076.00" 表示总的查询成本。s1表的"cost_info"部分:
"cost_info":
"read_cost": "97.00",
"eval_cost": "1979.00",
"prefix_cost": "2076.00",
"data_read_per_join": "17M"
- read_cost 是由下边这两部分组成的:
IO成本
检测rows*(1-filtered)条记录的CPU成本 - eval_cost 是这样计算的:
检测rows*filtered条记录的成本。 - prefix_cost 就是单独查询s1表的成本,也就是:read_cost+eval_cost
- data_read_per_join 表示在此次查询中需要读取的数据量。
8. 总结
本文详细介绍了EXPLAIN中ref、rows、filtered、Extra字段的剖析,其中rows字段和Extra字段非常的重要,另外EXPLAIN有四种输出格式,其中JSON格式可以列出查询的执行成本。
以上是关于MySQL从入门到精通高级篇(二十五)EXPLAIN中refrowsfilteredExtra字段的剖析的主要内容,如果未能解决你的问题,请参考以下文章