Flink 实战系列如何给 Flink 任务设置合理的并行度?
Posted JasonLee实时计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 实战系列如何给 Flink 任务设置合理的并行度?相关的知识,希望对你有一定的参考价值。
如何给 Flink 任务设置合理的并行度?

背景介绍
最近看到很多朋友都在问这个问题,当我在开发 Flink 实时计算任务的时候,如何给每个算子设置合理的并行度呢?如果设置多了可能会出现资源浪费的情况,如果设置少了任务可能会出现反压,所以给 Flink 任务设置一个合理的并行度就显得尤为重要,那今天就针对这个问题做一个详细的分析。
一个 Flink 任务通常是由三个部分组成的,Source,Transformation,Sink,下面就分别说一下每一部分如何设置。
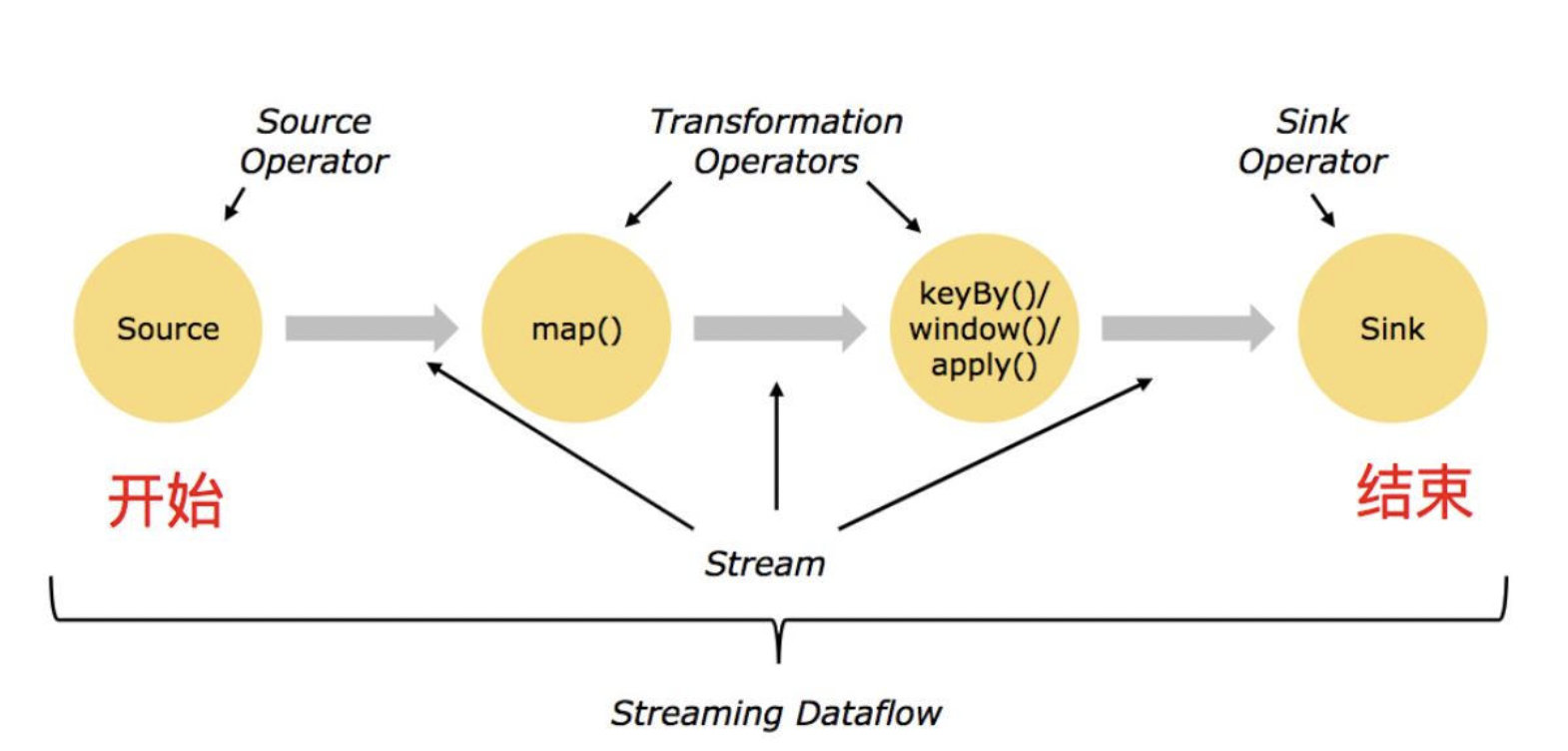
Source
Source 也就是整个任务的数据源,流式任务的 Source 通常是一个消息队列,所以我们就以 kafka 来举例,众所周知,Kafka 的 Topic 是可以设置多个 partition 的,所以最理想的情况下我们就把 source 的并行度设置成和 Topic 的 partition 保持一致,此时一个 Flink 的 subtask 会负责消费一个 partition 的数据,subtask 和 partition 之间是一一对应的关系,此时消费数据的性能是最高的。
Source 的并行度一定要和 Topic 的 par
以上是关于Flink 实战系列如何给 Flink 任务设置合理的并行度?的主要内容,如果未能解决你的问题,请参考以下文章