sparkSQL自定义数据源
Posted 子不语归来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sparkSQL自定义数据源相关的知识,希望对你有一定的参考价值。
sparkSQL自定义数据源
spark读取hbase的数据时,可以先使用newAPIHadoopRDD得到一个RDD,然后将rdd转换为DF,注册一张表,然后直接就是使用SparkSql用sql语句进行分析。
spark读取hbase的数据时,可以先使用newAPIHadoopRDD得到一个RDD,然后将rdd转换为DF,注册一张表,然后直接就是使用SparkSql用sql语句进行分析。
sparkContext.newAPIHadoopRDD ==》 RDD ==>转换成为rdd里面包含样例类, ==》 转换成为DF ==》 SparkSql使用sql进行数据分析
但此种方式写的比较复杂。SparkSQL支持多种数据源,但目前支持的几种数据源并不满足像此处业务,如HBase、redis等,此时便可以采用自定义数据源的方式读取sparkSql数据源,实现用sql对hbase进行分析。
本文写的Spark版本为2.3
创建hbase数据源表
为了实现我们的sparkSQL自定义数据源获取Hbase当中的数据,我们可以开发测试用例,通过自定义数据源实现获取Hbase当中的数据,然后将查询的数据保存到Hbase里面去
创建 spark_hbase_a表并插入部分数据,作为源数据
bin/hbase shell
create 'spark_hbase_a','f1'
put 'spark_hbase_a','0001','f1:name','caixukun'
put 'spark_hbase_a','0001','f1:score','80'
put 'spark_hbase_a','0002','f1:name','xiaozhan'
put 'spark_hbase_a','0002','f1:score','70'
创建Hbase的数据保存表
执行以下命令创建Hbase表,用于将分析之后的结果数据保存到Hbase当中来
创建spark_hbase_b表,用来存储分析后的数据
bin/hbase shell
create 'spark_hbase_b','f1'
自定义SparkSQL的数据源读取Hbase数据以及将分析结果
自定义sparkSQL数据源的过程中,需要对sparkSQL表的schema和Hbase表的schema进行整合;
整体代码如下:
package com.xyu.programApp
import java.util
import java.util.ArrayList, List, Optional
import com.xyu.utils.HbaseTools
import org.apache.hadoop.hbase.TableName
import org.apache.hadoop.hbase.client.Connection, Put, ResultScanner, Scan, Table
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.SparkConf
import org.apache.spark.sql.DataFrame, Row, SaveMode, SparkSession
import org.apache.spark.sql.sources.v2.reader.DataReader, DataReaderFactory, DataSourceReader
import org.apache.spark.sql.sources.v2.writer.DataSourceWriter, DataWriter, DataWriterFactory, WriterCommitMessage
import org.apache.spark.sql.sources.v2.DataSourceOptions, DataSourceV2, ReadSupport, WriteSupport
import org.apache.spark.sql.types.StructType
object HBaseSourceAndSink
def main(args: Array[String]): Unit =
val conf = new SparkConf().setMaster("local[2]").setAppName("HBaseSourceAndSink")
val sparkSession = SparkSession.builder().config(conf).getOrCreate()
//format需要我们自定义数据源
val df: DataFrame = sparkSession.read.format("com.travel.programApp.HBaseSource") //com.travel.programApp.HBaseSource 为一个class类
.option("hbase.table.name", "spark_hbase_a") //我们自带的一些参数
.option("f1.cc", "f1:name,f1:score") //定义有那些列族 定义查询habse的那些列
.option("scheam", "`name` STRING,`score` STRING") //定义我们表的scheam 字段
.load //加载数据
df.createOrReplaceTempView("sparkHbaseSql")
df.printSchema()
val reslutDf: DataFrame = sparkSession.sql("select * from sparkHbaseSql where score > 70 ")
reslutDf.show()
println("读取完成")
reslutDf.write.format(source = "com.travel.programApp.HBaseSource")
.mode(SaveMode.Overwrite)
.option("hbase.table.name", "spark_hbase_b") //保存到那个表
.option("f1", "f1") //定义有那些列族
.save() //保存
println("写完成")
/**
* 自定义数据源,实现数据的查询
* 需继承DataSourceV2
*/
class HBaseSource extends DataSourceV2 with ReadSupport with WriteSupport
override def createReader(options: DataSourceOptions): DataSourceReader =
//获取前面option的参数
val tableName: String = options.get("hbase.table.name").get()
val f1AndCC: String = options.get("f1.cc").get()
val scheam: String = options.get("scheam").get()
new HbaseDataSourceReader(tableName, f1AndCC, scheam)
override def createWriter(jobId: String, schema: StructType, mode: SaveMode, options: DataSourceOptions): Optional[DataSourceWriter] =
val tableName: String = options.get("hbase.table.name").get()
val f1: String = options.get("f1").get()
Optional.of(new HbaseDataSourceWriter(tableName,f1))
class HbaseDataSourceWriter(tableName:String,f1:String) extends DataSourceWriter
/**
* 将我们到数据保存起来,全部依靠这个方法
*
* @return
*/
override def createWriterFactory(): DataWriterFactory[Row] =
new HbaseDataWriterFactory(tableName,f1)
//提交数据的时候带的一些注释信息
override def commit(messages: Array[WriterCommitMessage]): Unit =
//数据插入失败的时候带的一些注释信息
override def abort(messages: Array[WriterCommitMessage]): Unit =
class HbaseDataWriterFactory(tableName:String,f1:String) extends DataWriterFactory[Row]
override def createDataWriter(partitionId: Int, attemptNumber: Int): DataWriter[Row] =
new HbaseDataWriter(tableName,f1)
class HbaseDataWriter(tableName:String,f1:String) extends DataWriter[Row]
//获取hbase连接
val conn: Connection = HbaseTools.getHbaseConn
val table = conn.getTable(TableName.valueOf(tableName))
//写如数据
override def write(record: Row): Unit =
val name: String = record.getString(0)
val score: String = record.getString(1)
val put = new Put("0001".getBytes()) //rowkey
put.addColumn(f1.getBytes(), "name".getBytes(), name.getBytes())
put.addColumn(f1.getBytes(), "score".getBytes(), score.getBytes())
table.put(put)
//数据的提交方法,数据插入完成之后,在这个方法里面进行数据的事务的提交
override def commit(): WriterCommitMessage =
//因为此时暂时没有事务的提交,所以就在此处将table和conn关闭
table.close()
conn.close()
null
//如果此写入程序失败,则中止它
override def abort(): Unit =
class HbaseDataSourceReader(tableName: String, f1AndCC: String, scheam: String) extends DataSourceReader
/**
* 定义我们映射表的schema
*
* @return
*/
override def readSchema(): StructType =
StructType.fromDDL(scheam)
override def createDataReaderFactories(): util.List[DataReaderFactory[Row]] =
import scala.collection.JavaConverters._
//转成java的集合 import scala.collection.JavaConverters._ .asJava
Seq(new HbaseDataReaderFactory(tableName, f1AndCC).asInstanceOf[DataReaderFactory[Row]]).asJava
class HbaseDataReaderFactory(tableName: String, f1AndCC: String) extends DataReaderFactory[Row]
override def createDataReader(): DataReader[Row] =
new HBaseDataReader(tableName, f1AndCC)
/**
* 自定义HBaseDataReader实现了DataReader接口
*/
class HBaseDataReader(tableName: String, f1AndCC: String) extends DataReader[Row]
var conn: Connection = null
var table: Table = null
var scan = new Scan()
var resultScanner: ResultScanner = null
/**
* 就在这里获取我们Hbase的数据
*
* @return
*/
def getIterator: Iterator[Seq[AnyRef]] =
//获取hbase连接
conn = HbaseTools.getHbaseConn
table = conn.getTable(TableName.valueOf(tableName))
resultScanner = table.getScanner(scan)
val strs: Array[String] = f1AndCC.split(",") //f1:name,f1:score
//转成scala的Iterator scala.collection.JavaConverters._ .asScala
import scala.collection.JavaConverters._
//获取到每一条数据
val iterator: Iterator[Seq[AnyRef]] = resultScanner.iterator().asScala.map(eacheResult =>
// val name: String = Bytes.toString(eacheResult.getValue("f1".getBytes(), "name".getBytes()))
// val score: String = Bytes.toString(eacheResult.getValue("f1".getBytes(), "score".getBytes()))
// Seq(name,score)
//todo自己写的
var seq = Seq[String]()
for (str <- strs)
val str1: String = str.split(":")(0)
val str2: String = str.split(":")(1)
val seq_item: String = Bytes.toString(eacheResult.getValue(str1.getBytes(), str2.getBytes()))
seq = seq :+ seq_item
seq
)
iterator
val data: Iterator[Seq[AnyRef]] = getIterator
/**
* 这个方法反复不断的被调用,只要我们查询到了数据,就可以使用next方法一直获取下一条数据
*
* @return
*/
override def next(): Boolean =
data.hasNext
/**
* 获取到的数据在这个方法里面一条条的解析,解析之后映射到我们提前定义的表里面去
*
* @return
*/
override def get(): Row =
val seq: Seq[AnyRef] = data.next()
//从“Seq”值构造一个[[Row]]
Row.fromSeq(seq)
/**
* 关闭一些资源的
*/
override def close(): Unit =
table.close()
conn.close()
查询hbse的结果
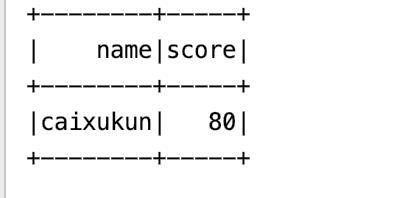
保存前

保存后
以上是关于sparkSQL自定义数据源的主要内容,如果未能解决你的问题,请参考以下文章